What is Unsupervised Learning: A Comprehensive Guide
Understanding What is Unsupervised Learning, the Mechanisms, Types, and Applications of Various Algorithms and Challenges it presents in Machine Learning

31 Jul, 2023. 16 minutes read
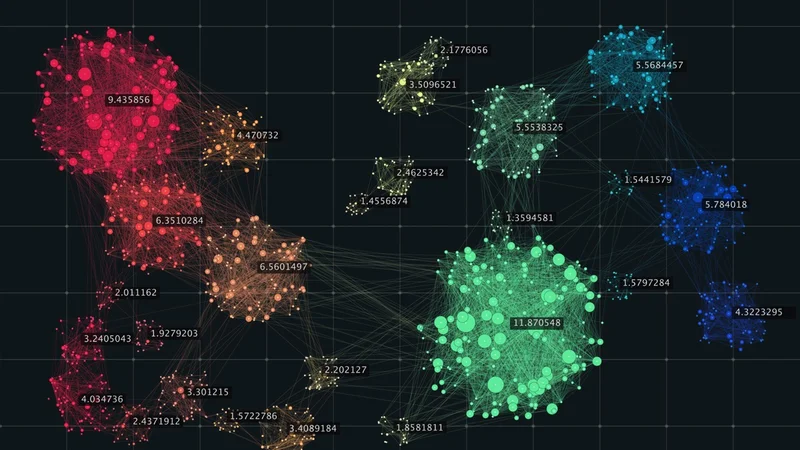
Clustering - A Common Unsupervised Learning Technique
Introduction
Machine learning is a critical subset of Artificial Intelligence, enabling machines to make predictions and learn from the environment, helping humans make decisions by predicting and analyzing the input information. Depending on the nature of the problem, some machine learning models require guidance with prelabeled datasets, while others tend to learn independently. This is where one must know what is unsupervised learning and supervised learning.
Unsupervised learning is a branch of machine learning that focuses on discovering patterns and structures in data without prior knowledge of the desired output. This type of learning is significant in artificial intelligence and machine learning, as it allows algorithms to learn and adapt to new data without human intervention.
The Basis of Unsupervised Learning
Unsupervised learning is a type of machine learning where algorithms learn patterns and structures within data without the guidance of labeled examples. It is deployed to discover hidden relationships, groupings, or representations within the data, allowing the algorithm to make predictions or generate insights autonomously.
In contrast to supervised learning, unsupervised learning does not rely on labeled data, which consists of input-output pairs where the desired output is known. Instead, unsupervised learning algorithms work with unlabeled data where the underlying structure is unknown. This distinction makes unsupervised learning particularly useful for exploratory data analysis, as it can reveal patterns and relationships that may not be apparent through manual inspection or supervised learning techniques.
In many ways, machine learning is most suited for discovering hidden information and identifying data patterns. But since the output isn't always known, unsupervised learning poses several challenges in data science, including:
Increased computational complexity
High probability of output inaccuracy
Extended training duration
Human dependency for output validation
Lack of clarity in clustering methods
Considering the algorithms, use of datasets, challenges, and applications, unsupervised machine learning significantly differs from supervised learning and has a wide range of use cases.
Further Reading: Unsupervised vs Supervised Learning: A Comprehensive Comparison
Labeled Data and Its Need in Supervised Learning
Labeled data is a type of data that is accompanied by explicit annotations or tags that indicate the correct output or target variable for each corresponding input. In machine learning, labeled data is essential for training supervised learning algorithms.
In supervised learning, the algorithm learns from the labeled data by analyzing the relationship between the input features and their associated output labels. The labels act as the ground truth or the correct answers the algorithm aims to predict when presented with new, unseen input data.
For example, let's consider a supervised learning task of classifying images of animals into different categories, such as "cat" or "dog." In this case, the labeled data would consist of images of cats and dogs, with each image tagged or labeled with its corresponding class ("cat" or "dog"). During training, the algorithm uses these labeled examples to learn patterns and features distinguishing cats and dogs. Once the model is trained, it can predict the correct class (cat or dog) for new, unlabeled images it has not seen before.
Creating labeled data often requires human effort and expertise. While datasets are critical for reinforcement learning and building accurate supervised machine learning models, using appropriate techniques to create datasets is equally essential. That's because the training data must provide only the necessary information for the algorithm to learn while reducing computational complexity. Labeled datasets are one of the fundamental distinguishing factors between supervised and unsupervised learning.
Types of Unsupervised Learning
Unsupervised learning can be broadly categorized into two main types:
Clustering
Dimensionality Reduction
These techniques aim to identify patterns and structures in data, to help better understand and interpret the underlying information.
Clustering
Clustering is a technique that groups similar data points based on their features. It helps identify natural groupings within the data, which can be helpful in various applications, such as customer segmentation, image segmentation, medical imaging, recommendation engines, and anomaly detection.
Typical examples of clustering may include:
Grouping stars based on brightness
Create document groups based on their titles
Group animals and organisms in a specific taxonomy
Some of the commonly used clustering techniques include:
K-means Clustering
It is a popular clustering algorithm that works by partitioning the data into a predetermined number of clusters (K). The algorithm initializes K cluster centroids randomly and iteratively refines their positions by minimizing the sum of squared distances between each data point and its nearest centroid.

The process continues until the centroids' positions converge or a maximum number of iterations is reached. K-means is computationally efficient and works well with large datasets. The initial placement of centroids is critical in clustering algorithms. Poorly placed initial centroids force them to converge to a local minimum, resulting in suboptimal clustering.
A good K-Means clustering algorithm creates clusters that have the minimum within-cluster variation. For this purpose, there are several techniques to measure the distance between the observations in each cluster, such as:
- Euclidean Distance - Computes the square root of square of the distances between coordinate pairs of objects.
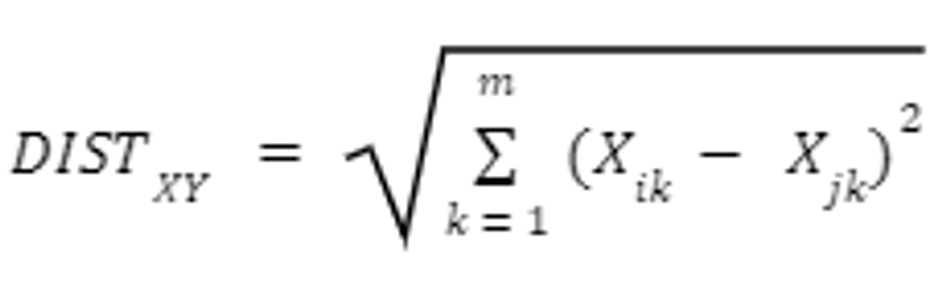
- Manhattan Distance - Computes absolute distance between object pairs
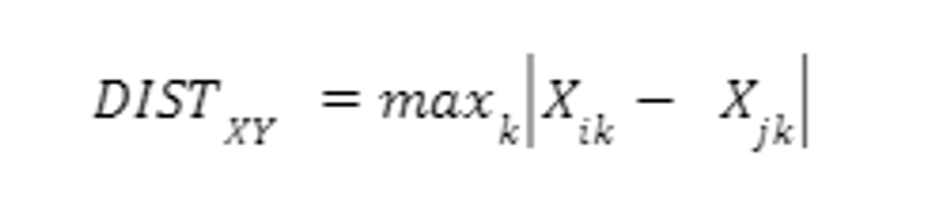
- Chebychev Distance - Computes absolute magnitude of the difference between object pairs.
- Minkowski Distance - Calculates generalized metric distance
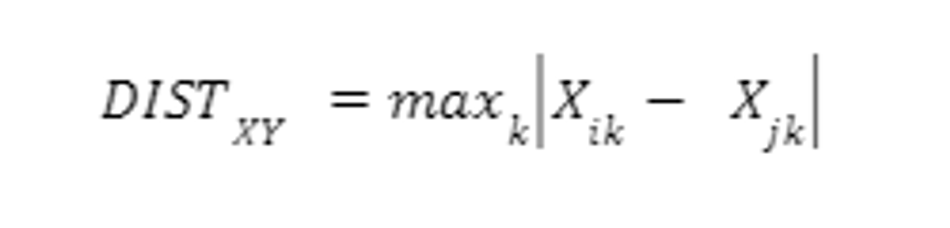
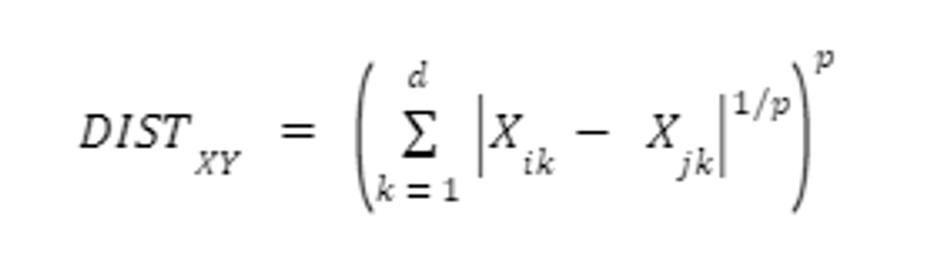
Hierarchical Clustering
Hierarchical clustering builds a tree-like structure to represent the relationships between data points. This method can be either agglomerative (bottom-up) or divisive (top-down).
Agglomerative Clustering - each data point starts as its cluster, and the algorithm iteratively merges the closest pairs of clusters until only one cluster remains.
Divisive Hierarchical Clustering - starts with a single cluster containing all data points and recursively splits the clusters until each data point forms its cluster.

Hierarchical clustering produces more interpretable data in the form of dendrograms. That's why it's more intuitive and visualizes the nested structure of clusters.
But simultaneously, hierarchical clustering is computationally more expensive than K-means and may not scale well to large datasets.
Dimensionality Reduction
Datasets can have several dimensions and features, which makes them computationally complex and more expensive. Dimensionality reduction is used to reduce the number of features or dimensions in a dataset while preserving its essential structure and relationships.
This process helps mitigate the curse of dimensionality, a phenomenon where the performance of machine learning algorithms degrades as the number of dimensions increases. Dimensionality reduction has several advantages, such as:
Improved computational efficiency
Noise Reduction
Improved Data Visualization.
There are many dimensionality reductions, among which the following ones stand out:
Principal Component Analysis (PCA)
It is a widely used technique for linear dimensionality reduction. PCA projects the original high-dimensional data onto a lower-dimensional subspace defined by the principal components.
PCA reduces redundancies in the data and compresses datasets through feature extraction. It uses a linear transformation to create new data representations, which results in a set of new Principal Components which are orthogonal vectors that capture the directions of maximum variance in the data.
By retaining only the first few principal components, PCA can effectively reduce the dimensionality of the dataset while preserving most of the original variance.
t-Distributed Stochastic Neighbor Embedding (t-SNE)
t-SNE is a popular nonlinear dimensionality reduction technique that can capture complex, nonlinear relationships in the data. The algorithm works by minimizing the divergence between two probability distributions:
One that represents pairwise similarities in the high-dimensional space
Another that represents pairwise similarities in the low-dimensional space.
The resulting low-dimensional representation aims to preserve the local structure of the data, making t-SNE particularly useful for visualizing high-dimensional datasets.
Limitations of Dimensionality Reduction Methods
PCA and t-SNE have their strengths and limitations, as summarized in the following table.
PCA | t-SNE |
Since, PCA assumes that the data lies in a linear subspace, it only provides the best results for linear data. | It can be computationally expensive, especially for large datasets. Moreover, its results can be sensitive to the choice of hyperparameters. |
Generally, the choice of dimensionality reduction technique depends on the problem and dataset at hand. An effective way to use dimensionality reduction is to use a combination of multiple techniques. For instance, it can be used for preprocessing data for other unsupervised learning tasks, such as clustering or anomaly detection.
Applications of Unsupervised Learning
With the ability to identify hidden patterns and relationships in data, unsupervised learning has various applications across various industries and fields. It doesn't need labeled data, which makes it computationally friendly and can work with a wide range of readily available data across industries. Primarily, unsupervised learning finds its applications in anomaly detection, recommender systems, and natural language processing.
Anomaly Detection
Anomaly detection identifies data points or patterns that deviate significantly from the norm, indicating potential errors, fraud, or other unusual occurrences. Unsupervised learning can be beneficial for anomaly detection, as it can analyze large volumes of data without needing labeled examples, which may be difficult or time-consuming to obtain.
One common approach to anomaly detection using unsupervised learning is clustering, where data points are grouped based on their similarity. After clustering, data points that do not belong to any cluster or are distant from their nearest cluster center can be considered anomalies.
PCA is another approach to dimensionality reduction, which focuses on representing the data in a lower-dimensional space while preserving its essential structure. It can project the data onto a lower-dimensional subspace, and use the reconstruction error between the original data as an indicator of anomalousness. Data points with high reconstruction errors are more likely to be anomalies, as they cannot be accurately represented in the lower-dimensional space.
Computer vision is an essential application of Anomaly detection, extracting features and patterns from images. Typically, it requires careful tuning of algorithm parameters and choosing an appropriate threshold for identifying anomalies.
Recommended Reading: DOT-HAZMAT: An Android application for detection of hazardous materials (HAZMAT)
Recommender Systems
Recommender systems are algorithms that suggest relevant items or content to users based on their preferences, behavior, or other contextual information. Unsupervised learning plays a crucial role in developing recommender systems, as it can help identify patterns and relationships within the data that can be used to make personalized recommendations.
Clustering - It is a typical application of unsupervised learning in recommender systems. It can be used to group users or items based on their similarity. For example, after running the data through a K-means algorithm, the system can generate recommendations based on customers' purchases, browsing history, and demographics.
Dimensionality Reduction - PCA or t-SNE can reduce the data complexity in recommender systems. It further improves the efficiency of the recommendation process. The algorithm projects the user-item interaction data onto a lower-dimensional space and helps identify latent factors that explain the observed preferences and behavior.
Collaborative Filtering - It assumes that users who have interacted with similar items will have similar preferences in the future. Collaborative filtering can be either user-based, where recommendations are generated based on the preferences of similar users, or item-based, where recommendations are based on the similarity between items. In both cases, similarity scores can be computed using various distance metrics, such as cosine similarity or Pearson correlation coefficient.
Natural Language Processing
Natural Language Processing (NLP) is a subfield of artificial intelligence that focuses on the interaction between computers and human languages. It involves the development of algorithms and models to understand, interpret, and generate human language in a meaningful and helpful way.
Not only does it focus on understanding the standard words and phrases, but the latest AI techniques can also learn human language patterns that often map to specific linguistic rules.
Regarding NLP, unsupervised learning is pivotal as it can help uncover hidden patterns and structures in textual data without needing labeled examples.
Applications of Natural Language Processing
Natural Language Processing is a vast field with text and speech recognition systems applications. So, its applications also vary accordingly.
Text Analysis - Latent Dirichlet Allocation (LDA) is a commonly used unsupervised learning technique that focuses on finding a hidden topic from a text. It does so by clustering the topics and analyzing the occurrence of words in specific documents.
Word Embeddings - These are continuous vector representations that capture semantic meaning. Popular techniques like Word2Vec and GloVe are used to analyze large text, which helps predict word context to generate embeddings that work as an input for NLP tasks like sentiment analysis, machine translation, machine translation, etc.
Unsupervised learning in NLP often requires preprocessing steps, such as tokenization, stemming, and stopword removal, to transform the raw text into a suitable format for analysis. Additionally, the choice of unsupervised learning technique and its parameters depends on the problem and dataset, making domain expertise and knowledge of the application context essential for achieving optimal results.
Challenges in Unsupervised Learning
Unsupervised learning presents several challenges that must be addressed to ensure the effectiveness and reliability of the algorithms and models developed. These challenges include feature selection, model evaluation, and the choice of appropriate techniques and parameters.
Feature Selection
Since unsupervised learning doesn't work with labeled datasets, feature selection can be a significant challenge compared to supervised learning. Feature selection identifies the most relevant and informative features or variables in a dataset to be used as input for unsupervised learning algorithms.
Understandably, the quality of the features can significantly impact the algorithm's performance, as irrelevant or redundant features can introduce noise and make it difficult for the algorithm to uncover meaningful patterns and relationships in the data.
In unsupervised learning, feature selection is typically achieved through:
Filter Methods - involve ranking features based on a specific criterion, such as variance or mutual information, and selecting a subset of features with the highest scores. These methods are computationally efficient and independent of the learning algorithm, but they do not consider the interactions between features or the specific requirements of the learning task.
Wrapper Methods - These methods evaluate the performance of the unsupervised learning algorithm on different subsets of features and select the subset that yields the best results. These methods can be more accurate than filter methods, as they consider the interactions between features and the specific learning task but are computationally expensive for large datasets and high-dimensional feature spaces.
Embedded Methods - Incorporate feature selection as part of the learning algorithm itself. For instance, some unsupervised learning techniques, such as PCA or Lasso, can inherently perform feature selection by reducing the dimensionality of the data or by imposing sparsity constraints on the model parameters. These methods can provide a good balance between computational efficiency and accuracy but may be limited to specific learning algorithms or assumptions about the data.
Choosing the Right Feature Selection Technique
Selecting the appropriate feature selection technique and the optimal number of features often requires domain expertise and careful consideration of the problem.
Model Evaluation
Evaluating the performance of unsupervised learning models can be challenging, as there are no ground-truth labels to compare the algorithm's output against. This makes it difficult to determine whether the model has successfully captured the underlying structure of the data or if it is merely fitting noise.
Researchers often rely on domain-specific evaluation metrics to address this issue or use unsupervised learning as a preprocessing step for supervised learning tasks, where performance can be more easily quantified.
Internal Evaluation Metrics - It assesses the quality of unsupervised learning models. These metrics are based on the properties of the model, such as the compactness and separation of clusters in clustering algorithms or the reconstruction error in dimensionality reduction techniques. Silhouette score and Davies-Bouldin index are typical examples of internal evaluation metrics that perform cluster analysis and evaluate features like similarity and ratio of cluster scatter.
External Evaluation Metrics - These metrics compare the output of unsupervised learning models to a set of ground-truth labels or a known reference structure. These metrics are helpful for labeled data or when the actual underlying structure of the data is known. Examples of external evaluation metrics include the adjusted Rand index and normalized mutual information.
The choice of evaluation metric depends on the specific problem, dataset, and application context. In some cases, it may be necessary to use a combination of internal and external evaluation metrics or to employ additional validation techniques, such as visual inspection or expert judgment, to assess the performance of unsupervised learning models.
Advanced Unsupervised Learning Techniques
Unsupervised learning is an evolving field. As a result, the researchers have developed more advanced techniques to address complex problems and improve the performance of existing methods. These advanced techniques often leverage deep learning and transfer learning to enhance the capabilities of unsupervised learning algorithms.
Deep Learning for Unsupervised Learning
Deep learning focuses on using artificial neural networks with multiple layers to model complex patterns and representations in data. Primarily, it has shown remarkable success in various supervised learning tasks, such as image classification and speech recognition. However, it has applications in unsupervised learning problems to discover more intricate structures and representations within the data. Some of the major applications include:
Autoencoders
Autoencoders are deep learning architectures designed for dimensionality reduction and feature learning. An autoencoder consists of two main components: an encoder, which maps the input data to a lower-dimensional representation, and a decoder, which reconstructs the original data from the lower-dimensional representation. By training the autoencoder to minimize the reconstruction error, it learns to capture the data's most important features and patterns.
Generative Adversarial Networks (GANs)
GANs are used for data generation and representation learning. GANs consist of two neural networks, a generator, and a discriminator, that are trained simultaneously in a competitive manner. The generator learns to produce realistic samples from a given distribution, while the discriminator learns to distinguish between actual samples and those generated by the generator.
Deep learning in unsupervised learning can uncover more sophisticated patterns and representations in data, leading to improved performance and more powerful models.
Limitations of Deep Learning
Deep learning-based unsupervised learning techniques often require large amounts of data and computational resources, making them more challenging to implement and scale than traditional ones.
Transfer Learning for Unsupervised Learning
Transfer learning leverages knowledge gained from one task or domain to improve the performance of a model on a different but related task or domain. This approach is beneficial when limited labeled data is available for the target task, as it allows the model to benefit from the knowledge acquired during the training on a source task with abundant data.
Natural Language Processing is an example of transfer learning which learns with a pre-trained language model. It doesn't learn from scratch but uses already-learned language patterns from available datasets. So, with some fine-tuning of the pre-trained models, new models can be extracted, resulting in higher efficiency even with low computational resources.
Knowledge transfer can improve performance, mainly when the target task has limited labeled data. Typically, this model is used in many NLP applications like sentiment analysis, machine translation, question-answering systems, text classifiers, etc.
Limitations of Transfer Learning
While being a powerful learning model, transfer learning has its set of limitations too. Here is how transfer learning can be limited.
Task Dependency - It only produces the best results when source and target tasks aren't related. It affects the transferred knowledge and relevance with the new application.
Biased Datasets - When trained on larger datasets, the pre-trained models tend to become biased, leading to suboptimal performance on the following target tasks.
Fine Tuning - These models tend to overfit with limited target datasets, so they respond less efficiently to new and unseen data.
Conclusion
Unsupervised learning is best suited for applications that don't rely on labeled datasets. It finds its major applications in pattern recognition and image processing for identification and recommendation systems. That's why it's a powerful tool for anomaly detection, natural language processing, and recommender models. Even though unsupervised learning faces challenges with feature selection and model evaluation.
However, it uses powerful techniques like clustering and dimensionality reduction to uncover hidden patterns and structures that yield valuable data insights that might be otherwise unknown. And with the evolution of new techniques like deep learning and neural networks, unsupervised learning will likely become more efficient across new and evolving industries.
Frequently Asked Questions (FAQs)
1. What is the difference between supervised and unsupervised learning?
Supervised learning involves training algorithms on labeled data where the desired output (or "label") is known. In contrast, unsupervised learning algorithms analyze and process data without any prior knowledge of the desired output, allowing them to uncover hidden patterns, groupings, and relationships within the data.
2. What are some standard unsupervised learning techniques?
Standard unsupervised learning techniques include clustering (e.g., K-means, hierarchical clustering) and dimensionality reduction (e.g., Principal Component Analysis, t-Distributed Stochastic Neighbor Embedding).
3. How is unsupervised learning used in anomaly detection?
Unsupervised learning can be used in anomaly detection by identifying data points or patterns that deviate significantly from the norm, indicating potential errors, fraud, or other unusual occurrences. Clustering and dimensionality reduction techniques can be employed to detect anomalies based on the distance between data points and their nearest cluster center or the reconstruction error between the original data and its lower-dimensional representation.
4. What is the role of unsupervised learning in natural language processing?
Unsupervised learning plays an important role in natural language processing by helping uncover hidden patterns and structures in textual data without needing labeled examples. Techniques like Clustering, dimensionality reduction, and word embeddings can be used for tasks like text analysis, topic modeling, and semantic representation learning.
5. How does transfer learning relate to unsupervised learning?
Transfer learning is a technique that leverages knowledge gained from one task or domain to improve the performance of a model on a different but related task or domain. Unsupervised learning can play a crucial role in transfer learning scenarios, as it can help extract useful features or representations from the source data that can be transferred to the target task
References
[1] What is Unsupervised Learning? | IBM
[2] What is Clustering? | Machine Learning | Google for Developers
[3] Jin Yao, Qi Mao, Steve Goodison, Volker Mai, Yijun Sun, (2015). Feature selection for unsupervised learning through local learning - ScienceDirect
[4] Archana Singh, Avantika Yada, Ajay Rana, (2013). K-means with Three different Distance Metrics (ijcaonline.org)
in this article
1. Introduction2. The Basis of Unsupervised Learning 3. Labeled Data and Its Need in Supervised Learning4. Types of Unsupervised Learning5. Dimensionality Reduction6. Applications of Unsupervised Learning7. Challenges in Unsupervised Learning8. Advanced Unsupervised Learning Techniques9. Deep Learning for Unsupervised Learning 10. Transfer Learning for Unsupervised Learning11. Conclusion12. Frequently Asked Questions (FAQs)13. References