SpeeChin aims to boost privacy by using silent speech recognition for smartphone control
Designed as a necklace-style wearable in a 3D-printed case, SpeeChin is capable of recognizing 54 English and 44 Chinese voice commands — even if the wearer never says anything out loud.

02 Mar, 2022. 5 minutes read

The SpeeChin prototype is worn around the neck to capture facial movements via an upwards-angled infrared camera.
Voice control has emerged as one of the most popular approaches for hands-free interaction with technology, from dictating short messages to a smartphone to telling a home assistant system to turn the heating up. It has one big drawback, however: The fact you have to voice your intentions aloud, which brings with it privacy and etiquette issues for public use.
SpeeChin, a necklace-style wearable developed at Cornell University with colleagues from McGill and Zhejiang Universities, aims to solve that problem — by ensuring you never have to utter a single word out loud, using silent speech recognition (SSR) derived from infrared camera footage.
Why a necklace?
“There are two questions: First, why a necklace? And second, why silent speech,” corresponding author Chen Zhang, assistant professor at Cornell, says of the project. "We feel a necklace is a form factor that people are used to, as opposed to ear-mounted devices, which may not be as comfortable.
“As far as silent speech, people may think, ‘I already have a speech recognition device on my phone.’ But you need to vocalize sound for those, and that may not always be socially appropriate, or the person may not be able to vocalize speech.”
Silent speech recognition systems which track facial movements associated with speech without the need for the user to make any actual noise — simply mouthing the word is enough. Existing systems have typically relied on a front-facing camera or sensors fitted to the head, face, or even inside the mouth, none of which are particularly well-suited to frequent use.
SpeeChin, by contrast, uses a single infrared camera module plus infrared LEDs for lighting — and points it up at the user’s chin from a 3D-printed necklace worn on a small silver chain around the neck. The images thus captured are processed, then fed through a deep-learning system which uses changes in the shape of the user’s neck and face to determine which of a series of pre-set command words are being silently uttered.
“We first tried using a standard RGB [visible light] camera,” the team explains of its prototypes. “However, we found it difficult to segment the user’s head from different backgrounds. We considered using a thermal camera or depth camera [but these] are too large to be considered ‘minimally obtrusive’ or the image resolution is too low. We settled on an IR camera due to its convenient filter system for background segmentation, small size, and relatively high image resolution.”
Using an infrared camera system brings an additional advantage, too: Fitted with filters operating at 650nm and 850nm, the device is unable to capture background details easily — addressing a big privacy issue with previous camera-based silent speech recognition implementations.
Learning the words
Images from the necklace camera, which is connected to a low-cost off-the-shelf Raspberry Pi single-board computer, are pre-processed to remove noise caused by changes in the device’s angle and positioning — minimized through the use of a weighted base and a free-sliding chain — and from clothes or lights entering the frame.
Once processed, the images are split up based on an utterance detection algorithm, designed to cut actual utterances out of general movement, and then fed into the SpeechNet end-to-end deep learning model. Based on a combination of both convolutional and recurrent neural network (CNN and RNN) technologies, the complete chain includes a global average pooling step and a long short-term memory (LSTM) block plus a final linear layer which outputs the detected speech command.
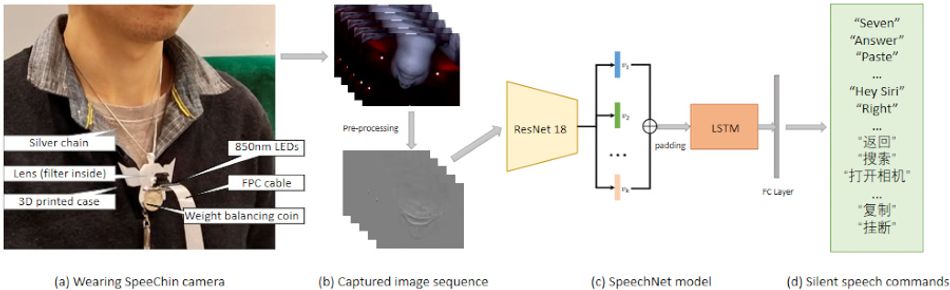
Trained on an augmented dataset — boosted by splitting captured footage’s 60 frames per second into two samples at 30 frames per second plus randomized affine transformation to simulate translation and rotation — the model was used across two primary studies: One with 10 participants testing 54 English-language commands, and another with a further 10 participants using 44 Mandarin commands.
The commands chosen for both languages ranged from digits and smartphone-related interaction tasks like call answering and media playback to punctuation, text handling, and common voice assistant wake-phrases like “Alexa” and “Hey, Siri.” The results are impressive: The English-language test completed with a 90.5 per cent accuracy, while the Mandarin test hit 91.6 per cent.
A third test tried out “non-words” in an effort to determine the SpeeChin system’s ability to extend to the ability to recognize individual phonemes and thus greatly expand its recognizable vocabulary. Performance here was weaker, but showed enough promise — particularly in being able to distinguish between phonemes involving the tongue, despite it being hidden from the camera’s view — for the team to consider implementing a phoneme-based variant in the future.
Work in progress
SpeeChin isn’t quite ready to replace audibly-spoken voice command technology just yet, however. The team admitted to weak user-independent performance — 54.4 per cent and 61.2 per cent in English and Mandarin tests respectively, with a high standard deviation — which could be improved by training a user-adaptive model.
A bigger issue is in the system’s use in mobile settings, where it would arguably be of most use. In a six-participant study, users were given the freedom to walk around while being fed instructions on commands to use via speakers: Differences in users’ walking styles and head movement dropped the accuracy to 72.3 and 65.5 per cent for English and Mandarin respectively in a reduced test set of just 10 phrases each — an issue the team suggests could be corrected through a change in the necklace’s design to reduce movement, stronger post-processing, the collection of a larger-scale training dataset, or the introduction of an activation gesture to trigger recognition.

Other areas to be improved include the prototype’s power consumption, which draws 5.4W excluding the deep-learning system running on a considerably more powerful external server, the camera’s sensitivity to strong sunlight, and the influence of clothing and hair which can occlude the user.
The team’s work has been published under closed-access terms in the Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies.
Reference
Ruidong Zhang, Mingyang Chen, Benjamin Steeper, Yaxuan Li, Zihan Yan, Yizhuo Chen, Songyun Tao, Tuochao Chen, Hyunchul Lim, and Cheng Zhang: SpeeChin: A Smart Necklace for Silent Speech Recognition, Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies Vol. 5 Iss. 4. DOI 10.1145/3494987.