2023 Edge AI Technology Report. Chapter VI: Edge AI Algorithms
What to Consider When Selecting Your Edge AI Hardware and Software.

2023 Edge AI Technology Report. Chapter VI: Edge AI Algorithms
Edge AI, empowered by the recent advancements in Artificial Intelligence, is driving significant shifts in today's technology landscape. By enabling computation near the data source, Edge AI enhances responsiveness, boosts security and privacy, promotes scalability, enables distributed computing, and improves cost efficiency.
Wevolver has partnered with industry experts, researchers, and tech providers to create a detailed report on the current state of Edge AI. This document covers its technical aspects, applications, challenges, and future trends. It merges practical and technical insights from industry professionals, helping readers understand and navigate the evolving Edge AI landscape.

Introduction
Artificial Intelligence (AI) deployment on edge devices has become increasingly popular due to its ability to perform tasks locally without relying on cloud services. However, one of the most critical considerations is the selection of a suitable algorithm that is appropriate for the problem it is intended to solve. The complexity, size, and accuracy of AI models can vary significantly, and choosing the best-performing algorithm may not be enough.
In many cases, edge devices have limited computing resources, so the selection of the algorithm should also take into account the computation power of the edge device and whether the chosen algorithm can run smoothly on the hardware. Balancing the algorithm's performance with the available resources is essential to ensure that the edge device can execute the AI model effectively.
While various types of AI algorithms can be successfully utilized on edge devices, including regression and classification algorithms, recent advancements and practical applications have shown that other types of applicable algorithms, such as clustering algorithms and natural language processing (NLP) algorithms. Clustering algorithms enable edge devices to group data points into clusters based on their similarities, while regression algorithms can predict the relationship between different data points. NLP algorithms allow edge devices to understand and respond to natural language commands.
However, the most popular and suitable algorithms for deployment on edge devices are classification, detection, segmentation, and tracking algorithms. These four algorithm types offer practical solutions for various applications, from object recognition and tracking to quality control and predictive maintenance. Here, we will discuss these four algorithm types in detail and explore their practical applications on Edge AI systems.
Classification Algorithms
Classification algorithms play a significant role in Edge AI technology as they enable edge devices to recognize and categorize different types of data. Recognizing and classifying data is essential for many Edge AI applications, such as object recognition, speech recognition, and predictive maintenance. Using classification algorithms, edge devices can process data locally, reducing latency and saving on network bandwidth. Several commonly used classification algorithms are applied in edge computing, including Support Vector Machines (SVMs), Decision Trees, Random Forests, and Convolutional Neural Networks (CNNs). We'll focus on these algorithms next.
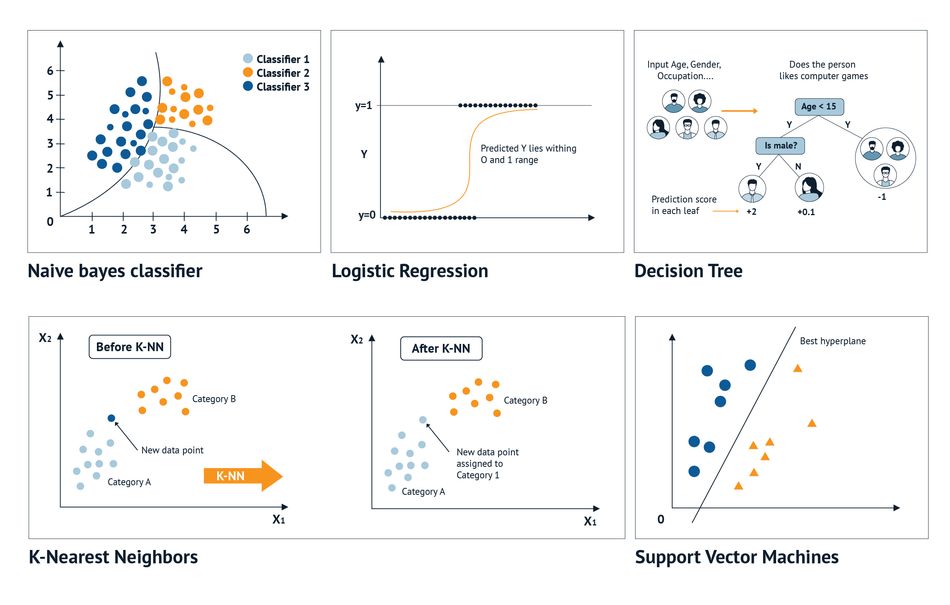
Support Vector Machines
SVMs are popular binary linear classifiers used in classification tasks such as image recognition. These algorithms work by identifying a hyperplane in high-dimensional space that can best separate the different classes of data. The distance between the hyperplane and the closest data points from each class is maximized to increase the classification accuracy. SVMs are particularly well-suited for smaller datasets and have a strong theoretical background for binary classification problems. They can perform well even with high-dimensional features, whereas other methods may face difficulties or limitations. However, SVMs can be sensitive to the choice of the involved kernel function, which maps the data into a higher-dimensional feature space. The choice of this function can significantly affect the model's accuracy and computation time, so precise selection and efficient optimization are necessary to achieve desired performance.
Random Forest
Random Forest is an ensemble learning method that constructs multiple decision trees to make predictions. Each tree is trained on a random subset of the data and produces its prediction, and the final prediction is determined by aggregating the predictions of all the trees in the forest. Random Forest is an excellent solution for handling large datasets and high-dimensional features because it can handle a large number of input features without overfitting the model to the training data. This is possible because the trees in the Random Forest are trained on different subsets of the data and different subsets of the features, reducing the risk of overfitting. Random Forests are particularly useful for classification problems with a large number of input features, such as image classification tasks.
Convolutional Neural Networks
CNNs are deep learning algorithms that excel at image recognition tasks by effectively extracting features from raw input data. They exploit a series of convolutional layers to learn filters applied in feature extraction. The pooling layers that follow these convolutional layers reduce the spatial dimensions of the feature maps and introduce invariance to small translations in the input. The scalability of CNNs is one of their strengths, as they can handle a wide range of image sizes and resolutions. In addition, CNNs can be trained on large datasets using stochastic gradient descent and backpropagation to learn highly complex and abstract features. To optimize CNNs for low-power applications, techniques like weight pruning, quantization, and model compression can be used. This makes CNNs an ideal solution for edge devices in energy-constrained environments.
Detection Algorithms
Detection AI algorithms play a crucial role in Edge AI systems by facilitating real-time analysis and decision-making at the edge of the network. These algorithms leverage sophisticated machine learning techniques, including computer vision, natural language processing, and signal processing, to identify specific patterns or events in real time. By deploying detection AI algorithms, Edge AI systems can operate with low latency and high accuracy without relying on frequent communication with a cloud provider. This is particularly advantageous in applications where real-time analysis is vital, such as security and surveillance systems, industrial automation, and autonomous vehicles. Furthermore, deploying such algorithms can reduce the data transfer requirements and associated costs of Edge AI systems since only relevant data is transmitted to the cloud for storage. The most commonly used categories of detection algorithms include object detection, anomaly detection, event detection, and face detection algorithms.
Object-Detection Algorithms
Object-detection algorithms are essential tools in computer vision, enabling accurate object recognition within images or videos. These algorithms identify regions of interest in an image or video frame and classify them based on the objects they contain. The accuracy of these algorithms relies on the quality and size of the training dataset, as well as the complexity and performance of underlying AI models.
Deep learning-based object detection algorithms, such as YOLO and Faster R-CNN, have shown good performance in various applications, including robotics, autonomous vehicles, and surveillance systems, where they are employed for real-time object detection. Additionally, the algorithms are successfully used in the medical field to help identify anomalies in medical images. However, detecting small or occluded objects remains a challenge for most algorithms, requiring new approaches and techniques to improve their robustness.
Anomaly-detection algorithms are designed to identify and flag events that deviate significantly from a system's expected or normal behavior. These algorithms establish a pattern of normal behavior based on historical data and then monitor the system to compare new data against the established pattern.
There are various approaches to anomaly detection, including statistical methods, clustering algorithms, and deep learning. Deep learning-based anomaly detection algorithms, such as autoencoders and RNNs, have gained popularity because they can learn complex patterns and detect anomalies. However, one of the challenges of anomaly detection is the difficulty in defining what is expected or normal behavior for a given system, as this can vary depending on the application and the system itself.
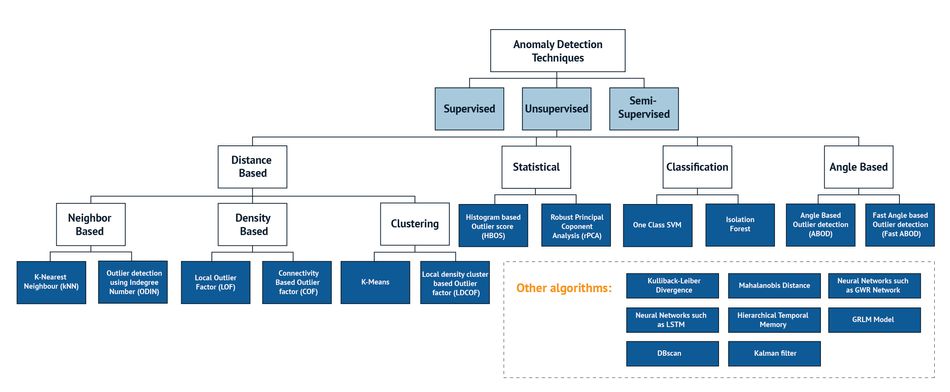
Anomaly detection algorithms are widely used in industrial applications for predictive maintenance, where they can identify equipment malfunctions before they occur, and in cybersecurity, where they can identify malicious behavior by monitoring network traffic and identifying anomalous patterns.
Event-Detection Algorithms
Event-detection algorithms can identify specific events or changes in data over time based on patterns or changes in the data. One commonly used algorithm for event detection is the background subtraction algorithm, which subtracts a static background image from each video frame and identifies pixels that differ from the background. Another popular algorithm for motion detection is optical flow, which tracks the movement of objects in successive video frames.
For sound event detection, a widely used algorithm is Mel-frequency cepstral coefficients, which extract features from sound waves to identify specific sound patterns. These algorithms are highly valuable in various applications, such as security monitoring and industrial automation. For instance, motion detection algorithms can trigger an alert or begin video recording upon detecting suspicious motion. Similarly, sound event detection algorithms could identify events such as speech, music, or machine noise. In industrial automation, event detection algorithms can monitor manufacturing processes, detect when a machine has stopped working, and prevent potential damage situations.
Face-Recognition Algorithms
Face-recognition algorithms are biometric recognition systems that detect and identify human faces within a photo or video. These algorithms work by analyzing and comparing facial features, such as the distance between the eyes, the shape of the nose, and the contours of the face. The first step in face recognition is face detection, which involves identifying the presence of a face in an image or video frame.
Once a face is detected, the algorithm extracts its features and compares them to a database of known faces to determine the subject's identity. There are several approaches to face recognition, including geometric, photometric, and hybrid methods, where geometric methods analyze the shape and structure of the face, photometric methods analyze the patterns of light and shade in the face, and hybrid methods combine both geometric and photometric features to improve accuracy.
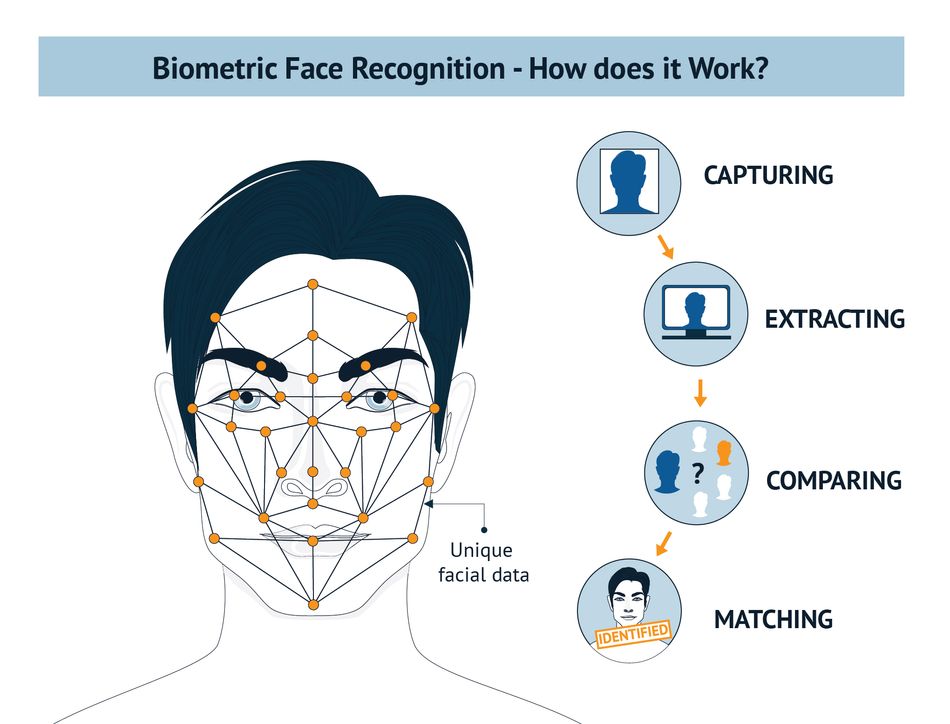
Face recognition algorithms are widely used in various applications, such as security and surveillance, law enforcement, and marketing. However, there has been an upsurge in scrutiny and regulation in some regions due to concerns about privacy and the potential misuse of facial recognition technology.
Segmentation Algorithms
Segmentation algorithms enable real-time image segmentation, which divides an image into multiple segments corresponding to different objects or backgrounds. Image segmentation simplifies image representation, making it easier to analyze and interpret. Edge devices use segmentation algorithms to analyze images and video streams captured by cameras at the edge of the network. By segmenting images into distinct regions, these algorithms enable edge devices to detect and track specific objects in real-time. The popular segmentation algorithms include CNNs, Random Forest algorithms, and the K-Means Clustering approach.
CNNs extract features from images using convolutional filters and classify pixels in the image into regions. Random forest algorithms generate a segmentation map for the input image based on the output of decision trees. The K-Means Clustering algorithm first converts an image into a high-dimensional space represented by pixels. The objective is to minimize the sum of squared distances between each pixel and its corresponding cluster center by partitioning the image. This process iteratively updates the cluster centers until convergence.
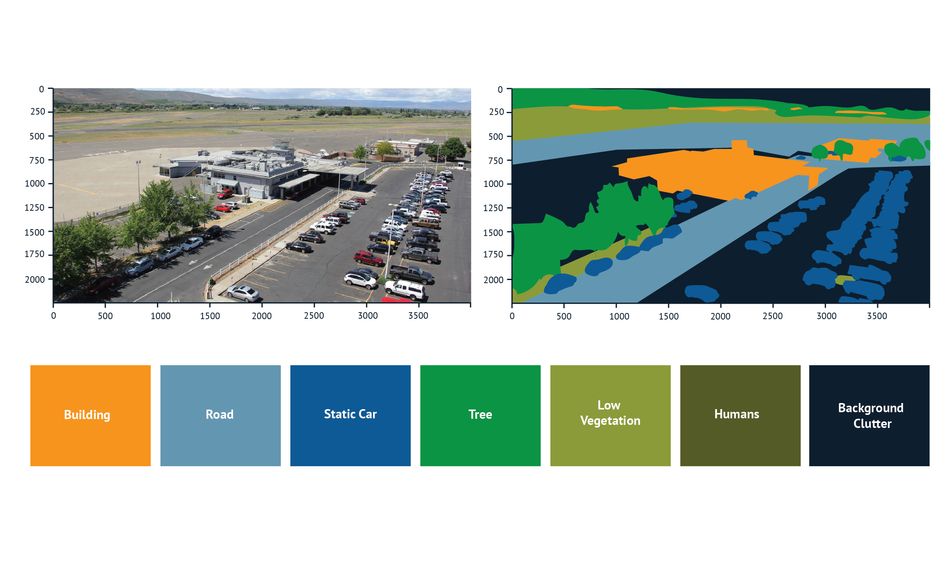
Tracking AI Algorithms
The last group of AI algorithms we want to highlight are the tracking algorithms that enable real-time detection and tracking of specific objects. These algorithms are crucial for various applications, such as surveillance and autonomous vehicles. The primary objective of tracking algorithms is to locate and follow moving objects accurately, providing essential information for decision-making or triggering actions. Kalman filters are a well-known solution for tracking objects in motion.
These filters estimate the object's position, velocity, and acceleration and predict its future positions based on this information. Particle filters are another popular solution that represents the object's position as a probability distribution and updates it over time based on new observations from images or videos. CNNs have also shown promising results in tracking tasks. They use convolutional filters to extract the features of the object of interest and track its movement. Furthermore, optical flow algorithms can identify movement patterns in an image and track the object using these patterns. These algorithms can track objects with smooth motion patterns, such as the motion of cars on a highway.
Temporal Event-based Neural Nets (TENNs)
Unlike standard CNN networks that only operate on spatial dimensions, TENNs are event-based networks that contain both temporal and spatial convolution layers. They may combine spatial and temporal features of the data at all levels, from shallow to deep layers. TENNs efficiently learn both spatial and temporal correlations from data in contrast with state-space models that mainly treat time-series data with no spatial components. Given the hierarchical and causal nature of TENNs, relationships between elements that are both distant in space and time may be constructed for efficient, continuous data processing
For applications like video, raw speech, and medical data, TENNs provide highly accurate processing with substantially smaller model size, and they can be trained just like CNNs.
Vision Transformers
An innovative advancement in Neural Networks for Computer Vision is the adoption of Vision Transformers (ViT) as a substitute for CNN backbones. Drawing inspiration from the remarkable performance of Transformer models in Natural Language Processing (NLP), researchers have begun applying similar principles to Computer Vision.
Prominent examples, including XCiT, PiT, DeiT, and SWIN-Transformers, highlight this trend. In this approach, images are treated as sequences of image patches, similar to NLP processing. Feature maps are represented as token vectors, with each token embedding a specific image patch.
Vision Transformers are quickly gaining prominence in various Computer Vision applications. They outperform CNNs on extensive datasets due to their increased modeling capacity, reduced inductive biases, and wider global receptive fields.
Harmonizing Algorithms with Hardware
Edge devices often have limited computing power. So, choosing an algorithm that works well with the device's hardware is vital, balancing performance and resources.
Bram Verhoef, Head of Machine Learning at Axelera AI, explains how the combination of hardware and software design can be an effective solution to such a challenge. “This involves techniques like data compression, specifically data quantization and network pruning. By compressing the data, the device needs less storage and memory and can use simpler computation units, for example, those using fewer bits. This also improves energy efficiency.”
“But data compression can cause the AI model to be less accurate,” Verhoef adds. “To avoid this, developers need to carefully choose which parts of the AI network can be compressed and by how much without losing too much accuracy.”
Additionally, the compression algorithm should be quick and compatible with many networks. Hardware developers need to work on using compressed data efficiently and communicate their findings to algorithm developers.
This chapter was contributed to by Samir Jaber and report sponsors Alif Semiconductor and Arm.
The 2023 Edge AI Technology Report
The guide to understanding the state of the art in hardware & software in Edge AI.
Click through to read each of the report's chapters.
Report Introduction
Chapter I: Overview of Industries and Application Use Cases
Chapter II: Advantages of Edge AI
Chapter III: Edge AI Platforms
Chapter IV: Hardware and Software Selection
Chapter V: Tiny ML
Chapter VI: Edge AI Algorithms
Chapter VII: Sensing Modalities
Chapter VIII: Case Studies
Chapter IX: Challenges of Edge AI
Chapter X: The Future of Edge AI and Conclusion
The report sponsors:
