Leveraging Synthetic Data to Boost Model Accuracy and Data Collection Efficiency
In both analytics and machine learning (ML), the value of data cannot be overstated. Understanding its importance is essential for unlocking its full potential and driving informed decision-making, enhancing business processes, and exploring new opportunities across various industry sectors.

08 Aug, 2023. 9 minutes read
Introduction
With vast amounts of data generated daily through digital interactions, social media, and internet usage, businesses have access to a wealth of information for analysis and value generation. By harnessing data analytics tools and techniques, companies can gain profound insights into their customers, identify market trends, and make data-driven decisions that significantly contribute to their growth and competitiveness.
However, insufficient real data can lead to under-fitted ML models, lacking the ability to learn complex patterns and handle highly volatile data. Consequently, the model's predictive capabilities may be compromised, resulting in inaccurate or unreliable results. Another challenge arises when processing sensitive data, such as medical records or personal financial information, which may be restricted due to privacy concerns. Additionally, collecting representative samples for rare events or occurrences can be difficult, further limiting the availability of real data for building accurate and robust ML models. Key difficulties include inadequate model training, poor generalization, biases, limited data exploration, and challenges related to costly and time-consuming data collection, as well as privacy and security regulations.
To address the aforementioned challenges and limitations imposed by insufficient real data, the concept of synthetic data is introduced. Incorporating this data into ML projects has proven to be a valuable strategy for overcoming challenges related to limited real data sources. The remainder of this article will focus on explaining the main principles of creating and utilizing such artificial data.
II. Understanding Synthetic Data
At its core, synthetic data refers to artificially generated data that mimics the statistical properties and characteristics of real-world data. Unlike real information, which is collected from actual observations or measurements, synthetic data is created through generative techniques, ensuring that it adheres to the same underlying distribution as the real data. The primary goal of generating synthetic data is to complement existing datasets, overcome data shortages, enhance model performance, and improve the overall efficiency of data-driven projects.
Generating synthetic data represents a critical aspect of ML projects, especially when real-world data is limited or expensive to obtain. Popular techniques like data augmentation or the application of generative models allow the creation of synthetic data that closely resembles real information while providing similar statistical properties. Data augmentation involves transforming existing data to produce diverse additional instances. In contrast, generative models like Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs) offer advanced synthetic data generation approaches. GANs utilize adversarial training with two neural networks: a generative model that acquires latent representations of the dataset and generates samples, and a discriminator that distinguishes authentic from synthetic data. VAEs belong to the unsupervised autoencoder family, understanding the underlying data distribution to generate new data from acquired latent representations. VAEs consist of an encoder for efficient latent representation and a decoder to transform it back to the original data space. Beyond data augmentation and generative models, approaches like rule-based synthesis and simulation also exist, where synthetic data is created based on predefined rules and constraints, and generated by simulating real-world processes, respectively.
Once synthetic data is created, it is not recommended to use it in isolation. Effectively combining real and synthetic data is a crucial step in leveraging the benefits of artificial data for ML projects. The data integration process involves aligning the synthetic data with the real data in terms of features and format to ensure seamless use in training models. Moreover, weighting and balancing datasets help address class imbalance issues and prevent the model from being biased towards overrepresented classes.
III. Advantages of Combining Synthetic and Real Data
Improving model accuracy and generalization capabilities are vital features for the success of ML applications. The incorporation of more diverse data plays a crucial role in achieving these goals by addressing the challenges of overfitting and inaccurate distributions caused by incomplete records. Overfitting occurs when an ML model becomes excessively tailored to the training data, leading to poor performance on new and unseen data. By incorporating diverse examples, the model is exposed to a broader spectrum of scenarios, reducing the likelihood of learning specific noise and outliers. Further, the utilization of diverse data helps stabilize the model's performance, resulting in increased robustness and adaptability when encountering volatile conditions in the real-world environment. Finally, regular datasets commonly have limitations such as class imbalance or lack of representation of specific scenarios. In such cases, the model's performance can be skewed towards overrepresented classes and fail to adequately address underrepresented classes. Incorporation of more diverse and synthetic observations can fill these gaps in the real data distributions, resulting in a more comprehensive and reliable dataset.
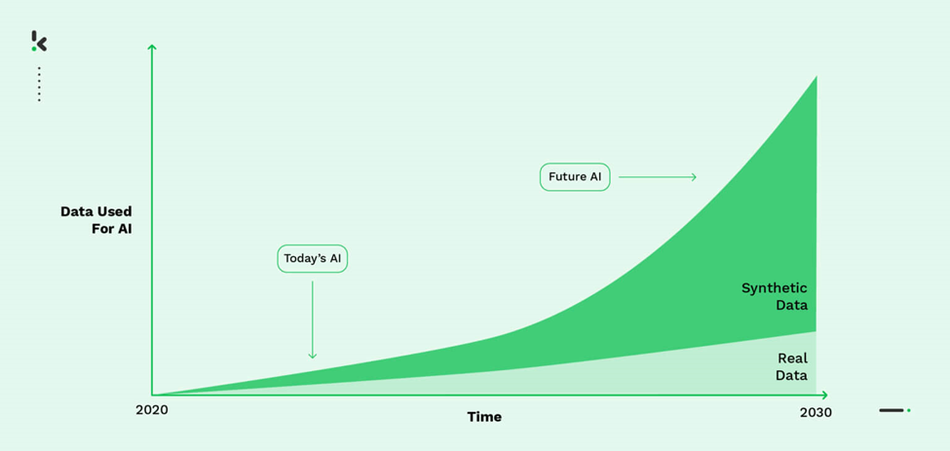
The AI practice has shown that exploiting datasets empowered with synthetic information enables rapid model iteration and refinement, ultimately accelerating AI development across various domains and industries. To explain progressive AI development, the role of synthetic data in enhancing data collection efficiency should be analyzed from two perspectives: time and resources. Time is an invaluable resource in ML projects, where rapid model development and deployment are crucial for delivering high-quality models. Conventional data collection methods often involve manual labeling and extensive fieldwork, leading to significant time consumption. However, incorporating synthetic data generation and augmentation techniques can tremendously accelerate the data gathering process. By introducing diverse variations of information, data augmentation enhances the model's ability to generalize and adapt to different scenarios while reducing the time required for data collection. From the perspective of costs, the process is often resource-intensive, particularly when dealing with specialized domains or large-scale datasets. Hiring data annotators, conducting extensive data gathering, or acquiring specialized computing resources can impose significant financial burdens on ML projects. However, an approach of combining synthetic and real data leads to a simpler methodology of acquiring representative observations and directly results in cost-savings. By generating synthetic data to complement real-world datasets, the need for costly data collection efforts can be reduced while maintaining or enhancing the diversity and data quality required for effective model training. The tremendous increase in the popularity of synthetic data, which is expected in the following years, can be best observed in Fig. 1.
With the increasing integration of AI and data-driven technologies into numerous aspects of society, privacy and security concerns have become paramount. The need to protect sensitive information while preserving data utility poses a significant challenge in data-driven applications. Here, synthetic data generation has emerged as a promising solution to mitigate these risks and provide a fair and sustainable environment for all involved parties.
Data collection techniques often fall short in fully protecting individuals' identities, leading to potential privacy concerns. Synthetic instances offer innovative approaches to overcome these shortcomings. Introducing generative models, synthetic datasets can be created in a way that maintains the statistical properties of the original data while ensuring information does not correspond to real individuals. This process enables the replacement of sensitive attributes with synthetic twins, making it impossible to correlate them with anyone. For instance, in healthcare applications, synthetic data can be used to anonymize patient medical records, protecting people's identities while still enabling comprehensive training of AI models for medical purposes. Through the process of anonymization with synthetic data, organizations can share datasets more confidently with researchers and collaborators, fostering innovation without compromising privacy.
IV. Challenges and Limitations
Unfortunately, the integration of synthetic and real data in AI applications is also accompanied by common challenges and limitations. Synthetic data generation relies on complex algorithms and generative models to approximate real-world data distributions. While these techniques have improved significantly, there is still a risk of introducing inaccuracies and biases into a synthetic dataset. Furthermore, the quality of the synthetic data heavily depends on the chosen generative model and the representativeness of the real data. Biases present in the real observations may inadvertently propagate into the synthetic data, leading to biased AI models and potentially reinforcing existing biases in decision-making processes.
It is true that synthetic data is seen as a promising and significant asset, but it is not a perfect replacement for real-world findings. While it can enhance data availability and diversity, it may not fully capture the complexity and nuances of actual scenarios. Complex relationships and interactions in the real world may be challenging to replicate accurately with artificial data points. As a result, AI models trained solely on synthetic data may not perform optimally in real-world settings. Careful consideration is required to strike a balance between using synthetic and real data to ensure the model's robustness and generalization capabilities.
In terms of legal issues, a combination of synthetic and real data raises questions regarding data ownership and consent. Real data used to train generative models may belong to individuals or entities, and their consent for data sharing and utilization must be respected. When using synthetic data to augment real data, the ownership and usage rights of the combined dataset become a critical ethical concern. Consequently, the legal and ethical frameworks should be navigated to ensure compliance with data privacy regulations and obtain appropriate consent from data subjects. In addition, responsible use of synthetic data also involves transparency and accountability. Users of synthetic information should be aware of its origin and limitations, and the sources of real data used in generating synthetic datasets should be disclosed.
V. Use Cases: Real-world applications of synthetic data integration
Having acquired an understanding of synthetic data and its distinctions from real-world data, let's introduce its vital applications across various industries:
- Healthcare: In the healthcare sector, synthetic data plays a pivotal role in training ML models for accurate disease diagnosis and health hazard detection. This proves invaluable in scenarios where genuine patient data accessibility is constrained due to privacy concerns or limited availability. Synthetic data comes to the rescue by allowing researchers to collect and generate sufficient training data, enabling them to simulate clinical trials even when genuine patient observations are unavailable or insufficient for meaningful conclusions. This fosters a more accurate and personalized approach to utilizing ML techniques in the domain of healthcare, and can facilitate early prediction of rare diseases and expedite drug discovery processes. For instance, in medical imaging, where data collection is challenging, synthetic data can be generated to represent rare medical conditions, enhancing the model's ability to diagnose such conditions accurately. By incorporating these diverse examples, the model gains a better understanding of the underlying data distribution, leading to improved performance across all possible scenarios.
- Finance: Synthetic data empowers ML models to recognize patterns and predict market trends, enabling financial institutions to make well-informed investment decisions and efficiently manage risks. Additionally, synthetic data plays a vital role in fraud modeling tasks, financial crime detection, and anti-money laundering efforts. For example, synthetic data addresses the challenge of lacking comprehensive observations in fraud modeling and financial crime detection by generating balanced datasets through augmenting "fraud" transactions, facilitating more accurate modeling and predicting malicious outcomes.
- Automotive: To train a robust navigation system for autonomous vehicles, a diverse and comprehensive dataset of real-world driving scenarios, including varied road and weather conditions, is necessary. However, manual data collection covering various locations and circumstances could be time-consuming and costly. To address this, research teams commonly combine synthetic and real data, exploiting the power of generative models. Synthetic data enables the generation of additional artificial simulation data to stress test autonomous vehicles, ensuring their ability to navigate complex environments and avoid collisions. By utilizing this data, deep learning models can enhance the efficiency of identifying and categorizing objects on the road, advancing the development of safe self-driving vehicles.
- Retail: Within the retail industry, synthetic data generates realistic simulations of customer behavior and preferences, providing retailers with crucial insights to optimize marketing and sales strategies. Predicting product popularity among specific demographics or during particular periods becomes achievable with synthetic data, even when real-world datasets are not of the highest standards for forecasting purposes.
- Education: Synthetic data offers a safe and controlled environment for learning, where individuals can experiment with various data scenarios, explore different algorithms, and fine-tune their skills. It provides an opportunity to work with diverse datasets that mimic real-world characteristics, enabling learners to build a solid knowledge foundation in a scientific field. Moreover, it allows educators to tailor exercises and projects to specific learning objectives, ensuring that students gain hands-on experience in tackling real-world challenges.
VI. Conclusion
Data scientists often find themselves devoting a significant portion of their time to collect, organize, and clean data, leaving less time for actual analysis. The situation becomes even more challenging when dealing with sensitive or confidential data, such as medical records and credit card information, which demands stringent privacy and security measures. Therefore, synthetic data serves as a valuable bridge between data science teams and the business aspects of an organization. The generation of realistic artificial datasets enables more accurate experiments and simulations, creating scenarios that closely mimic real-world situations. As a result, data scientists gain a deeper understanding of the requirements and expectations of stakeholders, ensuring that their analyses align with the business objectives.
By utilizing datasets that closely resemble actual data, non-technical stakeholders can comprehend the complexities and potential outcomes of various data-driven initiatives. This promotes effective communication and collaboration between data scientists and business decision-makers, facilitating the alignment of data-driven strategies with overall organizational goals. The realistic simulations created through synthetic data enable data scientists to tailor their analyses to meet business requirements while offering non-technical stakeholders a clearer grasp of the data science process.
In summary, the advantages of generating synthetic data encompass improved efficiency, cost reduction, faster development, and enhanced AI performance. By embracing synthetic data, organizations can leverage its potential to achieve in-depth data-driven insights while ensuring data security and ethical use.