Web image search gets better with graph neural networks
A new approach to image search uses images returned by traditional search methods as nodes in a graph neural network through which similarity signals are propagated, achieving improved ranking in cross-modal retrieval.
Last updated on 30 Nov, 2020. 14 minutes read

iStock/NAVER LABS Europe
This article was first published on
europe.naverlabs.comIf you’re like most people, you probably search for an image on the web by typing the words you think best describe what you’re looking for into a search engine. After browsing through the results, you might try to narrow them down using different words. As you go through this process, you likely don’t consider the many complicated steps that are being taken by the search engine behind the scenes in its endeavour to provide you with an image that matches your query.
Yet searching for an image from text is neither simple nor straightforward. The search engine must take words (often loaded with meaning) and try to match them with representations of images based on pixels. This is difficult because the words in a text query generally have a meaning that is impossible to directly compare or match with the pixels that constitute an image. This issue is referred to as the ‘semantic gap’. To complicate matters further, if you’re anything like me, you might use queries that are only indirectly connected to the image you’re looking for. This problem is known as the ‘intent gap’, which describes the difficulty inherent in trying to understand the thoughts and intentions of a user.
Mind the gap: semantics and intent in search queries
The semantic and intent gaps are best illustrated with examples. Recently, I used a search engine to determine which landmarks and buildings I might be interested in visiting during a stay in an unfamiliar city. One rather tedious approach would have been to first carry out an extensive search for a list of points of interest and then query them individually. Instead, I used a broad query—the name of the city—so that I could quickly browse through images of the points of interest and decide which ones I’d like to visit.
I adopted a similar strategy this morning when I discovered that some of the zucchini in my vegetable patch were looking a bit weird. I had no idea of the cause and wanted to get an idea of what the problem might be, as well as to find advice on what to do. Because I didn’t want to describe the symptoms (I didn’t know which were the most important ones and felt lazy), I instead decided to use an image search as a guide by simply querying ‘diseased zucchini’. I was then able to compare the symptoms I could see on the plant to those shown in the results and, from there, navigate to a website that described the most likely cause.
In both examples, I wasn’t trying to find (or use) words that precisely described my needs. Instead, I used a vague, high-level query in the hope that—with the range of results provided, and the speed with which one can grasp the content of an image—I would quickly find the information I needed.
Trying to bridge the semantic gap has always been a challenge. Fortunately, advances in technology (in particular, deep learning) have helped make substantial progress in this area. Specific neural architectures mean that a machine is now better able to understand the content of an image and is therefore capable of extracting higher semantic information from pixels. Machines can even automatically caption an image, or supply answers to an open-ended question about an image with an image (1). Despite all this progress, though, the semantic gap has not been perfectly filled—primarily because words are not able to describe everything that an image communicates.
Conversely, addressing the intent gap in search is considered one of the most difficult tasks in information retrieval. Indeed, the inability to know what a person is thinking when they enter words as a query would appear to be an insurmountable problem. But by exploiting the user context (e.g. their location, device, and the time of their query) and their previous search history, this problem can be partially alleviated. In particular, using huge collections of logs that contain both the queries and the clicked objects associated with those queries, machine learning techniques can be used to uncover the subtle relationship between the query, its context and the desired result.
In our project, we build on recent state-of-the-art developments—namely ‘text as proxy’, ‘joint embeddings’, and ‘wisdom of the crowd’—to address both the semantic gap and the intent gap. We go beyond what has been achieved by these three approaches by introducing a graph neural network (GNN) that successfully improves image search.
Current approaches to web image search
Text as a proxy
In the early era of web image search, ‘text as a proxy’ was the primary strategy adopted by most search engines. Because images on the web are usually embedded in web pages, they are generally surrounded by text (including the ‘alt text’ of the image) and structured metadata. This information can be used to match images with queries. It’s for this reason that an image with its associated bundle of information is referred to as a ‘multimodal object’. If we’re lucky, an image caption or title within this bundle will accurately describe the content of the image and this text can be relied on for the retrieval task.
More generally, the idea is to index an image not by its visual content but by its associated text. Existing mono-modal text-based retrieval methods can then be applied to rank the objects by relevance score. Additional metrics—such as image quality (determined by neural models that are able to quantify an image’s aesthetics), the PageRank (2) of the associated web page and how new, or ‘fresh’, the image is—can also be used to determine the relevance score of an image. Based on a training set that contains queries and multimodal objects that have been manually annotated for relevance, a machine can learn how to combine all of these so-called weak relevance signals (including the relevance score derived from the text-retrieval engine) to obtain an even more accurate ranking.
Although this approach succeeds in integrating a broad set of elements, some weaknesses remain. First, we can’t be sure that the text used as a proxy for the image is indeed a good summary of its content, or of all the ways that this content could be expressed in a query. These pieces of text are often written by everyday users (i.e. user-generated content) in a specific context, where there’s no obligation for precision or even relevance between the choice of image and the text (or vice versa). Indeed, images and text found in the same page can provide complementary but quite different kinds of information that are not necessarily strongly associated. Second, it is universally accepted that describing everything about an image with words is impossible, particularly in terms of the emotion that it arouses or the aesthetic perceptions, which remain very individual. Finally, any approach that uses a manually annotated dataset entails the costs of those annotations (which are generally commissioned or purchased).
Joint embeddings
The ‘joint embeddings’ family of methods is driven mainly by scientists from the computer vision community and aims to find common representations for images and pieces of text, such as phrases or sentences. In a nutshell, the goal is to design ‘projection’ functions that transform objects from their original spaces—RGB (red, green, blue) pixels for images, and words or sub-words for text—into a new common space, where images and text can then be matched together. These projected objects are high-dimensional numerical vectors called ‘embeddings’.
From these projections, the text describing an image (i.e. one of its perfect captions) can be expected to have its embedding positionally very close, in vector space, to the embedding of its corresponding image. If such a mapping can be built from the data, the query text of the user can then be applied and used to look for the images that lie closest to the projected query in this new common space. Such images are considered most relevant.
Of course, these projection functions are highly complex and typically rely on deep neural architectures. For a machine to learn them requires training data, consisting of a universal collection of thousands (if not millions) of images annotated with one or more sentences that perfectly describe their content. Additionally, for the learning to be feasible and for generalization purposes, the descriptions need to be ‘clean’. In other words, they must be purely factual and observational and free of any subjective aspects (emotions, beauty, etc.) or named entities (proper nouns). Such requirements make training data exceedingly difficult to collect.
The main weaknesses of this approach are the high cost of the human annotations required and the sheer impossibility of covering all possible concepts and domains of human knowledge. Additionally, the maintenance of huge, annotated collections of images becomes increasingly difficult over time because new concepts and entities appear every day. For these reasons, joint embeddings can only partially address the semantic gap from the perspective of annotations. Moreover, this problem exists with all concepts and words to be addressed in the queries. The likelihood of a mismatch between the (often, poorly expressed) user query and the training data is pretty high, even before considering the challenges posed by the intent gap!
The wisdom of the crowd
Who better to tell if an image is relevant to a query than users themselves? This ‘wisdom of the crowd’ approach captures several subjective, time-varying and contextualized factors that a human annotator would never be able to figure out. As an example, consider the query words ‘brown bear’ for an image search. It’s highly likely that the images clicked on in the result will indeed be brown bears. However, these images will be diverse in content (i.e. some will be real brown bears whilst others will represent toys). Additionally, the most attractive images are the ones generally clicked on. Based on a very large collection of image search logs containing several million time-stamped queries covering very diverse topics and their associated clicked images, though, it is relatively easy to characterize images with textual queries. With this information in mind, one of the two previous approaches can then be applied. For instance, in text as a proxy, if the images are indexed with their frequently associated queries, a simple mono-modal text search algorithm can be used to find images that are relevant to a new query. Alternatively, a new joint-embedding model can be trained based on huge crowd-annotated training collections of image-text pairs.
Unfortunately, the ‘wisdom’ in the wisdom of the crowd is not, in fact, all that wise. It’s well known that ‘click signals’ are both noisy and biased. Among the biases that exist, the ‘position bias’—i.e. the likelihood that images are clicked is greater for those placed higher in the list or grid of a page, irrespective of their relevance—is a relatively straightforward one to understand and mitigate for. But there are several other kinds of biases that must be considered too, including the trust bias, layout bias and self-selection bias. Removing bias and noise is a major challenge in exploiting click information. Another difficulty arises due to the number of new, freshly published images that are not yet linked to any queries (or are only linked to a few) with little text representation. For these images, the wisdom of the crowd would appear to be of little use.
An obvious strategy for overcoming this issue would be to consider that, in the case where an image is visually close to a popular image (i.e. one with a high number of clicks, and a high number of clicks relevant to the given query), this newer image should also be popular. Propagating these kinds of ‘weak’ relevance signals within a network of visually linked images comes quite naturally, and is precisely what inspired us in our work. We generalize the propagation mechanism in a more principled way using the graph formalism and, in particular, graph convolution networks (GCNs). These GCNs constitute a general framework that learns how to propagate signals in a graph to solve a task and is the core method we have developed for image search.
A differentiable cross-modal model for image search
Our idea for improving image search is a simple one: to combine the best features of each of these three approaches. We wanted to take advantage of the abundant and easily available text descriptions of images (captions, surrounding text and associated queries) even if they are somewhat noisy, incomplete or occasionally unrelated to the image content. We also wanted to exploit other kinds of weak relevance signals, such as the PageRank of the image web page, the unbiased popularity of the image and its freshness. Finally, we wanted to leverage recent computer vision models, such as ResNet (3), that can extract very powerful semantic representations of images that are especially useful when comparing two images.
Our method initially relies on the text as a proxy strategy. Given a user’s text query, we build an initial set of retrieved images from a standard text-based search engine using the associated noisy textual descriptions. It’s worth pointing out that observing the set as a whole can reveal some interesting patterns and provide hints on how these multimodal objects should be sorted. The next steps consist of considering the whole set of objects, analysing how their weak relevance signals are distributed and, finally, learning to propagate them so that a more accurate global relevance measure can be computed for every object.
Next, we adopt a graph formalism to build a graph from this initial set. The nodes in our graph are the multimodal objects (i.e. the images with their associated text) that are returned by the search engine. Nodes have several features, such as the textual relevance score (computed by the text search engine), the PageRank of the page, the freshness of the image and its de-biased popularity. The edges in the graph are defined by the visual nearest-neighbour relationship between objects. In other words, we compute the visual similarity between every image in the set and retain the edges between images that are the most similar. Each edge has a weight, which is determined by the visual similarity between the images at its two end points.
Once the graph has been built, we apply a GCN that propagates the weak relevance signals of the nodes through the graph. More precisely, these signals are first transformed locally and then transferred to the neighbour following a message-passing scheme (4). This procedure can be repeated multiple times, corresponding to multistep (or multi-hop) propagation in the graph. The important thing here is that the message-passing equations use the edge weights (i.e. the visual similarity between nodes). The algorithm allows these weights to be modulated, or fine-tuned, so that refined visual similarities more suitable for the retrieval task at hand can be automatically derived. The transformation and feature-aggregation functions have parameters that are learned during a training phase. More precisely, the training stage exploits a manually annotated collection of queries and multimodal objects, and the parameters of the model are identified to obtain global relevance scores of the nodes after propagation. We indirectly maximize standard information retrieval metrics, such as Precision@10 (5) and normalized discounted cumulative gain (6), by using ‘proxy’ objectives (i.e. pointwise differentiable objective functions).
Providing better rankings by propagating relevance signals through a GNN
Let’s return to our example of an image search for ‘brown bear’. Although the images that are returned from this query may contain a brown bear, the textual similarity to the query, the image quality or the PageRank of their source website could be quite different. By learning to exchange these relevance signals through the image modality, the GNN can provide better rankings.
Video 1: A set of images retrieved by the standard text-based search engine, based on the query ‘brown bear’, is represented in the form of a graph. The images are connected when their visual similarity is sufficiently high. The assembled graph neural network (GNN) scans each image to propagate similarity signals through each node and then adjusts the edges to reflect the weight of connections (i.e. the similarity) between nodes. The GNN scores the images depending on several features (e.g. popularity and newness) and determines which of the images are most relevant.
Another advantage of this approach is that the image ranking is fully contextualized. The score of an image to a query depends on all other objects in the initial retrieved set, so it is relative rather than absolute. In other words, the GNN learns to propagate or transfer relevance signals between different images; instead of learning the conceptual representation of an image compared directly to the text (as in the joint embedding approach), similarity signals are propagated. The model architecture is depicted in Video 1.
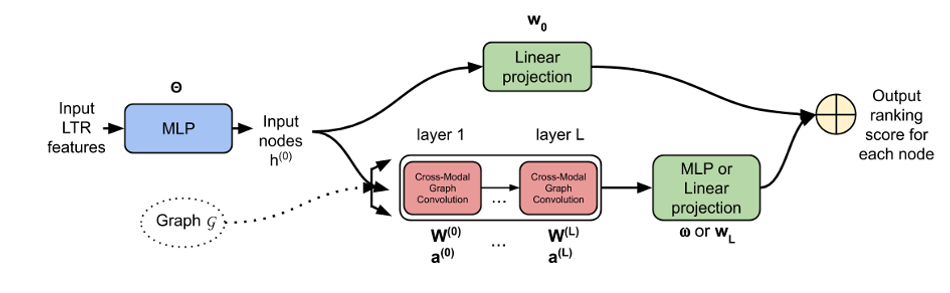
Figure 1: The global architecture of our approach, illustrating the flow of transformations that are applied to the input features to compute the output relevance score for each node. Each rectangle in the graph is a standard neural network building block. These blocks can comprise a simple linear layer (such as the rectangle in the upper branch) or a graph convolutional layer (such as the rectangles in the lower branch). The associated weights—e.g. Θ, w0, W(0) and a(0)—are denoted above or below each block. W(0) are weights that govern how information is propagated over the nodes (message passing), while a(0) are the weights that define the generalized dot product that will characterize the edges (i.e. the image similarities). MLP: Multilayer perceptron. LTR: Learning to rank.
To compute image similarities, we rely on pretrained ResNet descriptors (3) and learn a generalized dot product (also known as ‘symmetric bilinear form’) to adapt these pretrained image similarities to our web image search task. The model is very compact, with roughly 3–10K parameters, depending on the number of cross-modal convolution layers. Any feature can be plugged in, and the visual, textual, structural and popularity features are aggregated in a fully differentiable model. See Figure 1 for an illustration of the global architecture of our approach.
Although the graph structure is implicit in image search, we have found GNNs to be a very powerful model that can generalize some popular heuristics in information retrieval, such as pseudo relevance feedback (7). Additionally, our model can be used in other cross-modal search scenarios (i.e. text to image) and, being end to end, can learn how to optimally combine the different pieces of information.
We evaluated our approach and compared it to other state-of-the-art methods (8) on two datasets, i.e. the MediaEval 2017 dataset (9) and a proprietary NAVER Search dataset. The datasets include hundreds of queries and a collection of images whose relevance with respect to the queries is manually annotated. For these, our method achieved an improvement of around 2% in both Precision@20 and mean average precision (mAP) metrics, which in practice can lead to a significant increase in click-through rate (10). In more recent experiments with a larger NAVER Image Web Search dataset (corresponding to a sample of 1000 queries), the improvement is even larger: 12% in mAP. This leads us to conclude that the gain is much higher when we use refined visual similarities and web-based data. For more details, please see our ECIR20 paper (11) and code (12).
Summary and future work
The fundamental challenges we face when designing a multimodal search engine root from the semantic and intent gaps, or what a user can express in words as a text query and the difficulty in surmising the visual content that they’re expecting to receive as a result.
Our approach seeks to combine the strength of three well-known methods (i.e. text as proxy, joint embeddings and the wisdom of the crowd) by modelling the whole set of image results as a graph whose nodes are the images with their associated text and whose edges encode the visual similarity between end points. Expressing the inputs of our problem as a graph with some weak relevance signals associated to each node of the graph enables us to benefit from recent advances in GNNs—namely a set of signal propagation mechanisms that are learned from the data itself. These mechanisms allow us to go from a set of unrelated, incomplete and noisy pieces of relevant information into a globally consistent set of strong relevance signals by considering all of these pieces synergistically.
Our approach opens up new avenues for solving cross- or multimodal problems, as the methods and techniques that we describe can be easily extended to compare other mixtures of media beyond text and image, such as speech, video and motion.
References
- VQA: Visual Question Answering. Stanslaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C. Lawrence Zitnick and Devi Parikh. Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), 11–18 December 2015, pp. 2425–2433.
- The PageRank Citation Ranking: Bringing Order to the Web. Lawrence Page, Sergey Brin, Rajeev Motwani and Terry Winograd. Technical Report, Stanford InfoLab, 1999.
- Deep Residual Learning for Image Recognition. Kaiming He, Xiangyu Zhang, Shaoqing Ren and Jian Sun. Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 7–12 June 2016, pp. 770–778.
- Graph Neural Networks: A Review of Methods and Applications. Jie Zhou, Ganqu Cui, Zhengyan Zhang, Cheng Yang, Zhiyuan Liu, Lifeng Wang, Changcheng Li and Maosong Sun. arXiv:1812.08434v4 [cs.LG], 2019.
- Precision at K in Multilingual Information Retrieval. Pothula Sujatha and P. Dhavachelvan. International Journal of Computer Applications, vol. 24, no. 9, 2011, pp. 40–43.
- A Theoretical Analysis of NDCG Type Ranking Measures. Yining Wang, Liwei Wang, Yuanzhi Li, Di He, Tie-Yan Liu and Wei Chen. Journal of Machine Learning Research, vol. 30, 2013, pp. 25–54.
- Pseudo Relevance Feedback. Christopher D. Manning, Prabhakar Raghavan and Hinrich Schütze. Introduction to Information Retrieval. Cambridge University Press, 2008, p. 187.
- NLE @ MediaEval’17: Combining Cross-Media Similarity and Embeddings for Retrieving Diverse Social Images. Jean-Michel Renders and Gabriela Csurka. MediaEval’17, 13–15 September 2017.
- The 2017 Retrieving Diverse Social Images Task. MediaEval Benchmarking Initiative for Multimedia Evaluation, 2017.
- Expected Reciprocal Rank for Graded Relevance. Olivier Chapelle, Donald Metlzer, Ya Zhang and Pierre Grinspan. Proceedings of the 18th ACM Conference on Information and Knowledge Management (CIKM ’09), November 2009, pp. 621–630.
- Learning to Rank Images with Cross-Modal Graph Convolutions. Thibault Formal, Stéphane Clinchant, Jean-Michel Renders, Sooyeol Lee and Geun Hee Cho. European Conference on Information Retrieval (ECIR 2020), 14–17 April 2020, pp. 589–604.
- Differentiable Cross Modal Model (DCMM) Repository. Thibault Formal, Stéphane Clinchant, Jean-Michel Renders, Sooyeol L