Audio edge processors deliver sublime context-aware communication experiences
Dedicated audio edge processors with machine learning will deliver increasingly natural communication experiences.
03 Mar, 2021. 6 minutes read

This article was co-authored by Raj Senguttuvan and Vikram Shrivastava.
Introduction
The last decade, but particularly 2020, saw a massive increase in video calling and engagement with voice-enabled devices primarily through the work-from-home trend created by the pandemic. However, our use of video calls isn’t restricted to just work Zoom meetings. We are now using video calling for teaching, exercise classes, to experience live music, as a tool for interacting at conferences, and even to go to restaurants. This virtual engagement occurs via laptops, smartphones, tablets, and other IoT devices such as Amazon Echo Show, Facebook Portal, Peloton, Tempo Studio, etc. We have also embraced the use of voice-controlled devices such as home assistants and wireless earphones, and other smart home applications.
The core point that limits enjoyable and engaging interactive audio, video call, or home assistant experiences is consistent sound quality in the presence of noise and other distractors. The ability of your device to intelligently manage sound is what makes or breaks your ability to communicate.
Increasing audio expectations
Dubbed ‘smart sound’ by product makers, audio intelligence is the ability of a device to process sound to deliver the best user experience. As the increase in voice-led device use for communication, entertainment, and health management increases, so does the demand for a seamless, low-barrier experience with increased functionality. Users now expect devices to understand more than simple wake or keywords (such as Alexa) and seek the ability to move between devices and applications with superior sound quality to enable an immersive and seamless experience, whether for professional conferencing or personal entertainment.
Devices should be able to combine your voice and/or voice command with your personal preferences and environmental data to adapt sound processing to your specific context. This is known as contextual awareness.
What is Contextual Awareness?
Contextual-aware devices combine user-specific information, such as location, preferences, and ambient sensor data, to better understand what the user is asking for and more accurately execute functions in response to a certain command or trigger.
Always-listening devices use signal processing technology combined with machine learning to differentiate between sound types such as natural sounds, voices, background interference, etc. These sounds are often divided into “scenes'' and “events”. A scene is the users setting such as a noisy airport terminal or a quiet working space. The events are someone speaking, a glass breaking, or a dog barking. A context-aware device can process these groups of sounds to ensure the intent of the action, whether it is a video call or a voice command, and is processed for optimal experience.
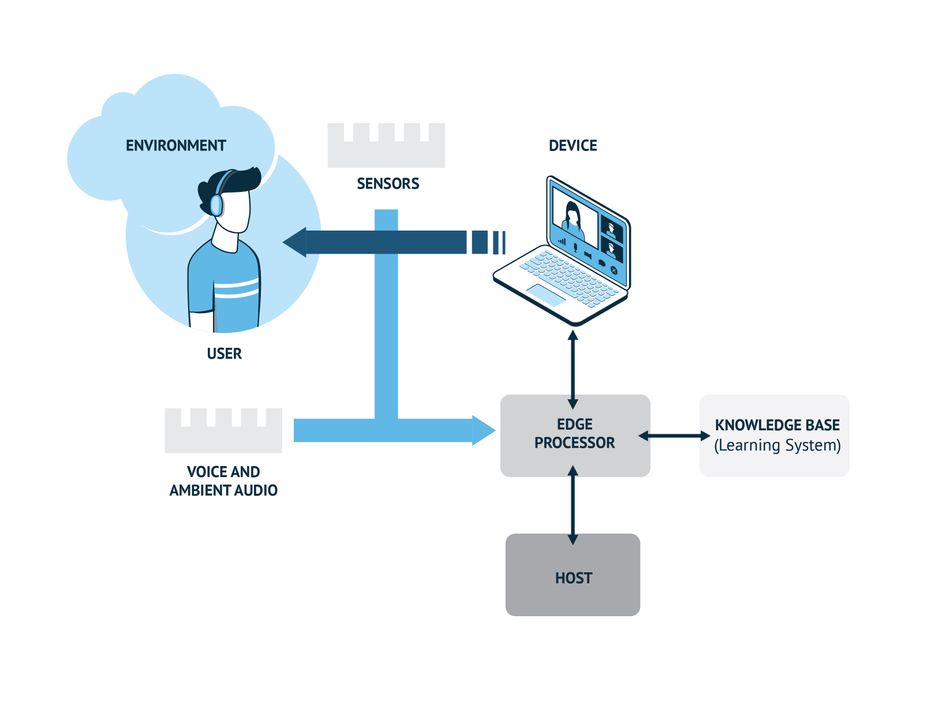
Dedicated audio edge processors with a focus on audio fidelity and with machine learning optimized cores are the key to contextually aware and high-quality audio communication devices. These processors can deliver enough compute power to process complex audio using just a small percentage of the energy of a generic Digital Signal Processing (DSP) implementation. These audio edge processors use ML algorithms for superior sound processing in addition to providing a more contextual audio experience.
“I think you are on mute”
Video conference calls have been a focal point in 2020 and continue to dominate work and social lives in 2021. The gaps in technology are revealed quickly when devices, people, and environments fail to keep up with the demands of the calls - to the point where the phrase ‘I think you're on mute’ was dubbed the most used business term in 2020. Dedicated audio processors with ML is the necessary approach to solve some of the common video conferencing pain points.
ML on dedicated audio processors are already addressing some common video conference pain points:
- Selective noise canceling. By understanding a range of scenes and action noises, certain background elements such as a fan, heater, or street noise can be removed, thereby, improving overall call quality and the ability to work in a wider variety of environments.
- Hi-fi audio reconstruction. Analogous to the way budget smartphones use smart software to increase the image quality from low-quality cameras, ML in real-time audio processing can improve the audio quality from low-quality microphones.
- Spatial audio for improved user experience. Already available on advanced gaming headphones and some TWS devices, advanced digital sound optimization techniques provide users a spatial audio experience. Spatial audio can create a natural listening experience for the user, which can help mitigate “Zoom Fatigue”.
In the future, ML on audio processors will have even more advanced capabilities such as real-time speech processing that would enable automatic language translations. Additionally, ML can solve the ‘on mute’ problem by becoming more aware of the user’s context and offer prompts to unmute.
A look at specialized audio edge processors
There are several areas audio edge processors get right to deliver exceptional audio and voice command experiences.
Noise and Distance
Beamforming is the process where the device can engage its ability to focus the listening or output sound in a particular direction. Noise suppression makes conversations in everyday scenarios possible. A listening device determines the direction(s) of the voice source(s) and that of noise sources. ML classification techniques are then used to determine which beams have voice or noise in them. The DSP then focuses on beams with voice content only for further voice UI processing. For example, in a conferencing system, the device must identify the direction of arrival of sound, and multiple speakers must be tracked at all times in a 360-degree fashion. Noise sources can also be classified further for audio event detection like glass break, fire alarms, and gunshots, etc for further expanding the role into audio aware smart home systems.
Proximity detection is also essential for dynamic listening and speaking experience. The device detects user proximity to the microphone and adjusts the microphone’s gain. This feature enables active video conferencing for presentations, workouts, and learning environments. These features are central to the design of advanced video conferencing devices such as the new Amazon Show which features a screen that rotates to where it senses the user.
Latency
Humans can generally tolerate up to 200ms of end-to-end latency on a call before we begin to talk over each other. Low latency processing in edge processors is, therefore, a critical requirement for ensuring high-quality voice communication.
Power consumption
Audio edge processors designed with proprietary architectures, hardware accelerators, and special instruction sets can optimally run audio and ML algorithms. These optimizations help with reducing power consumption in audio-heavy use cases such as video conferencing.
Integration
Audio edge processors that open up their architectures and development environments accelerate innovation by providing audio application developers the tools and support to create new devices and applications. Future audio devices will be a collaborative effort.
Security
Edge processing can minimize the need for cloud processing providing many benefits, including increased data security. For example, most consumers are not comfortable with data from personal smart home devices being transferred continuously to the cloud for processing. These fears have proven true with several major breaches by leading device manufacturers in the last years. Peace of mind can be achieved when personal data is processed for analysis or inference at the device. An excellent example of this is a smart home security device that has been trained to hear certain event sounds, such as glass breaking, that act as a trigger to alert the homeowner. As the processing of the sound and the alert occurs on the device, it does not need to be in continuous connection to the cloud, which enhances the security of the system.
Delivering Audio Intelligence at the Edge
Knowles AISonic™ IA8201: Dual Core is an audio edge processor specifically designed for advanced audio and machine learning applications, enabling power-efficient intelligence and privacy at the edge. It offers robust voice activation and multi-microphone audio processing with sufficient compute power to perform advanced voice processing and audio output, context awareness, and gesture control for today’s most advanced consumer electronics. Processing voice and audio voice with an audio edge processor like IA8201 can keep the power-hungry host processor off as long as possible to extend battery life.
In addition, it also enables new use cases for enhanced user experience by having the capability to run ML algorithms on multiple sensor inputs to deliver a more natural and contextual user experience.
Audio edge processors like IA8201 have a place in a variety of audio and voice-enabled applications including smart speakers, video conferencing devices, tablets, Bluetooth headphones, and smart home devices.
Recommended reading: Enhancing the utility of Audio AI in everyday devices using Audio Source Classification
Conclusion
Dedicated audio edge processors will define the next generation of audio and voice-enabled devices creating more context-aware, immersive, and seamless audio communication experiences. Their ability to enable efficient processing for low power and low latency voice communications, noise reduction, context awareness, and accelerated ML inferencing of sensor inputs opens the possibilities to an explosion of new user experiences for the human-machine interfaces.
References and further reading:
Antonini, Mattia & Vecchio, Massimo & Antonelli, Fabio & Ducange, Pietro & Perera, Charith. (2018). Smart Audio Sensors in the Internet of Things Edge for Anomaly Detection. IEEE Access. PP. 1-1. 10.1109/ACCESS.2018.2877523.
Do, Ha & Sheng, Weihua & Liu, Meiqin & Zhang, Senlin. (2016). Context-aware sound event recognition for home service robots. 739-744. 10.1109/COASE.2016.7743476.