Industry 4.0 Deep Dive. Part 2: Data-Driven Intelligent Production
How big data, advanced analytics, and AI are changing manufacturing.

Last updated on 09 Jun, 2020. 16 minutes read

Image: KUKA
This series investigates the current changes in the way we work and manufacture. It’s sponsored by KUKA, developer of industrial robots and solutions for factory automation. As a sponsor for this series on Industry 4.0, KUKA supports the spreading of knowledge about the technologies that create our factories of the future.
The Industry 4.0 series is written as a collaborative effort from experts in the field. After we at Wevolver wrote an outline of the articles we made a call-out in the Wevolver community for contributors. With their wide range of background and deep expertise these contributors crafted this and other articles in this series and we are grateful for their dedication.
The first article introduced the topic and gave an overview of what exactly Industry 4.0 is composed of. This second article will show you how greater intelligence can revolutionize manufacturing.
Download the entire e-book here.
About the contributors
Athens, Greece
Honorary Research Fellow, IIoT, University of Glasgow.
Adjunct Professor, University of Sheffield, Athens Tech Campus.
Adjunct Professor, Information Networking Institute, Carnegie Mellon University.
Rodrigo Teles
Strasbourg, France
Ph.D. in Computer Science at the University of Strasbourg, focus on IoT.
Member of the Network Research Team of the ICube Laboratory.
Anish Jindal
Lancaster, United Kingdom
Senior Research Associate, IoT and Smart Grid, Lancaster University, UK.
Ph.D. Computer Science and Engineering, Thapar University.
Adriaan Schiphorst
Amsterdam, the Netherlands
Technology journalist.
MSc Advanced Matter & Energy Physics at University of Amsterdam and the California Institute of Technology.
Previously editor at Amsterdam Science Journal.
Sydney, Austrlia
CEO and Co-founder Medulla
Research Associate, IoT and Smart Grid, Lancaster University.
Ph.D. in Physics, on Nonlinear Optics, at the University of Sydney.
Bachelor, Engineering Physics & Management at McMaster University.
Andreas Bihlmaier
Karlruhe, Germany
Co-founder and CTO of Robodev
Previously leader of the Cognitive Medical Technologies group in the Institute for Anthropomatics and Robotics - Intelligent Process Control and Robotics Lab (IAR-IPR).
Ph.D. in Robotics from Karlsruhe Institute of Technology (KIT).
Sophie Laurenson
Zurch, Switzerland
Ph.D. in Biochemistry, Biophysics and Molecular Biology, from the University of Cambridge.
Executive MBA, Business Administration and Management, the Smartly Institute.
Previously Senior scientist and innovation manager at The New Technology Group of Abbott.
Intro
The term Industrie 4.0 originated in Germany and describes the influence of the Internet of Things on industry and the digitization of industrial processes. The same concept is also described by the terms ‘Industrial Internet of Things’ (IIoT) and Smart Manufacturing, but for simplicity in this series we’ll use the international term ‘Industry 4.0.’
In this second installment in the series of five, we’ll guide you through the developments in (big) data acquisition and analytics relevant for the manufacturing industry. We’ll show how companies are adapting to optimally use artificial intelligence and what challenges arise.
Analytics in manufacturing: historical perspective
Data analytics encompass a range of approaches with the ultimate goal of extracting knowledge and applying it to anticipate and solve problems. The large volumes of data that can be collected from manufacturing processes in real-time enables advanced algorithms to be applied for decision-making.
Data must be collected, organized and cleaned before analysis, and each step affects the precision of the algorithm used. Data analytics for industrial processes has traditionally relied on conventional statistical modelling approaches. Companies in manufacturing industries successfully integrated engineering, science, and statistical modelling tools to develop large-scale process automation platforms. These systems are often known as 'Advanced-Process-Control' (APC) systems. They enable companies to optimize the efficiencies of their machines and processes.
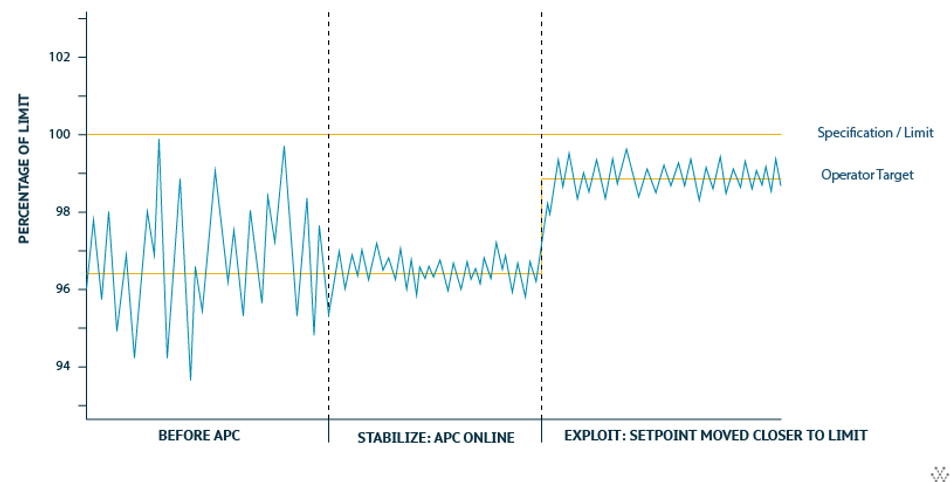
For example, an inspection tool in a semiconductor factory might measure inspection points on a silicon wafer, and store the data in associated databases. The APC system, analyzing these output parameters, decides whether the building recipe (the input parameters) needs to be altered to adjust for errors.[1] This is nothing new, however, as more industrial IoT devices and metrics become embedded within automated processes, different types of structured and unstructured data including sensor data, images, videos, audios, and log files are being collected. In order to process the increasingly larger, heterogeneous datasets that are associated with Big Data, more advanced approaches are required.
Manufacturers can leverage their data to inform decision-making and identify new or un(der)-used opportunities to improve productivity and efficiency.[2] While they expect that successful implementation of Industry 4.0 concepts will lead to a reduction in manufacturing costs, about a quarter also believe that the most critical outcome of the fourth industrial revolution for their business is increasing agility in operations. Still, implementation is a challenge[3]: Data integration and security, process flexibility, and the strict performance requirements for systems contribute to under-utilization of data in manufacturing settings.
Furthermore, the implementation of process automation through APCs has often been restricted to large-scale processes, primarily due to the large capital expenses associated with equipment purchases and installation, and the return on investment (ROI) is rarely favorable for small-scale processes. In addition, the manufacturing sector has lagged behind other sectors in investing in IT systems that enable them to capitalize on their data to increase efficiencies in small scale processes.
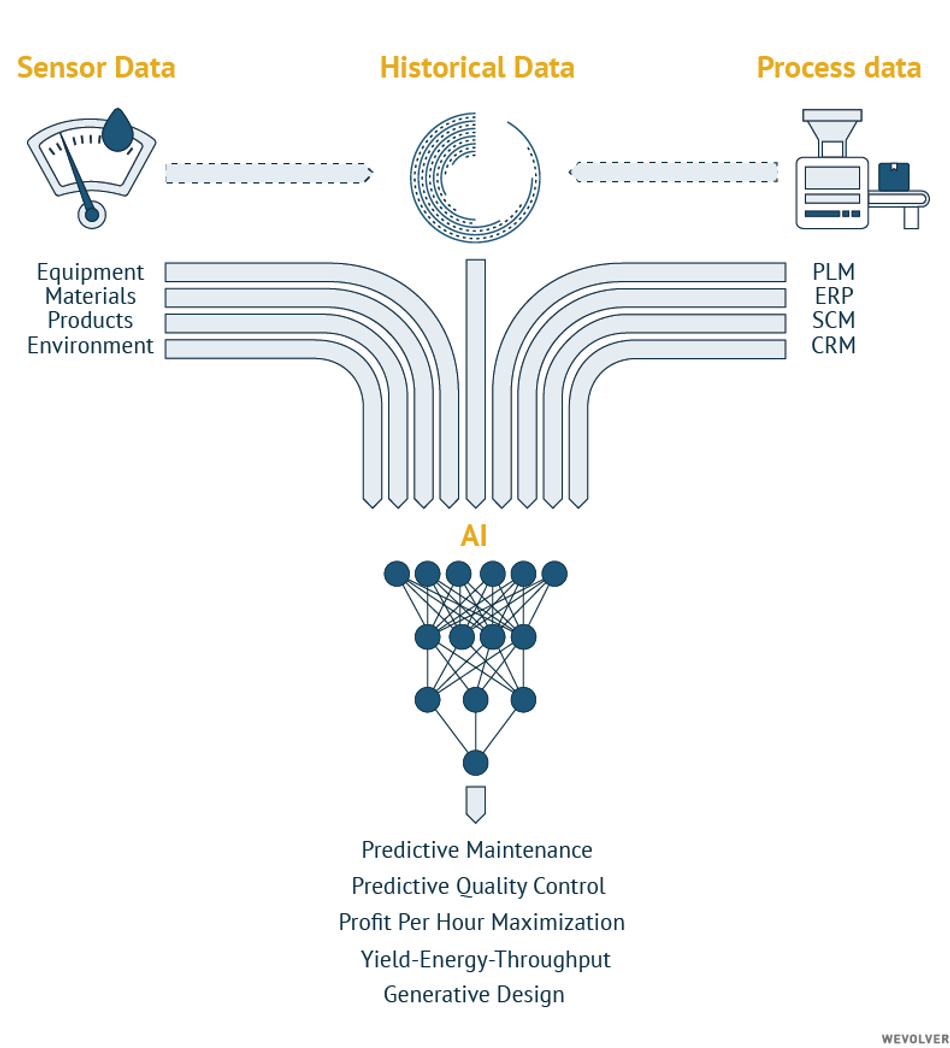
Fortunately, that is changing. Several technological advances have changed this pattern of lacking IT investment in the manufacturing sector. Advances in computational infrastructure, particularly cloud-based platforms, have enabled efficient storage and management of large data volumes.[4] Enterprise Resource Planning (ERP) systems, which were traditionally used to manage back office functions, have become web-based, enabling the integration of main business processes with collaborative functions such as Supply Chain Management (SCM), Product Lifecycle Management (PLM) and Customer Relationship Management (CRM).
Low-cost and long-lasting sensors can now be connected through wireless networks, enabling large amounts of data from the factory floor to be collected in a scalable and cost-effective manner. Information from IoT devices in the factory can be combined with wider enterprise datasets to optimize productivity and efficiency in a highly flexible manner in response to demand. The reduced cost of intelligent sensors, accessible software, and advances in analytical tools has made room for a more bottom up approach to manufacturing automation. Insights and intelligence can now be achieved on much smaller scales, opening up the concepts of Industry 4.0 to smaller enterprises.
Onwards to Big Data and advanced analytics
The main difference in data analytics between the third and fourth industrial revolution is the shift to a more proactive approach that anticipates problems before they occur and promotes corrective actions ahead of time. Algorithms can be descriptive ("what has happened"), diagnostic ("why an event has happened"), predictive ("what will happen"), or prescriptive (suggesting a course of action). That shift in paradigm, from reactive to proactive, can be seen in many industry practices.
Big Data
This has been made possible by the rise of big data. As defined in our previous introduction article, big data is characterized across four properties: volume, velocity, variety and value. Volume represents the generation and storage of large amounts of data, velocity refers to the renewal rate of data points and their timely analysis. Variety indicates the types of structured and unstructured data gathered from different sources. Last, value refers to the hidden information stored in these datasets. Stored, because data is essentially worthless without data management and analytics.
Of the general population of big data, most sets are unstructured (about 95%[5]), text, images, audio and video are all common examples. In order to prove value, there is a need to organize and structure datasets, to homogenize the data that reside in different systems and sources (e.g., sensors, automation devices, business information systems). Or, to improve the algorithms to better adapt to heterogeneity. These are the challenges for more advanced analytics. Due to high volume, the size of big data sets can create the opportunity to study data from heterogeneous sources. But due to the massive samples, conventional statistical methods can be outdated. Furthermore, computational methods, that have worked fine on smaller samples, might fall short in efficiency on these new, larger datasets.[6]

Advanced Analytics
The process of identifying factors that drop efficiency, or cause defects or quality deviations in the manufactured product is called root cause analysis (RCA). Traditionally manufacturers rely on on-site expert knowledge for this. And while experience is valuable, production lines are often so complex that awareness of every component and sub-process and their relationships is humanly impossible.
In Industry 4.0 automated root cause analysis can be implemented to evolve from reactive and preventive to predictive practices. Beyond increasing accuracy and shortening investigation times for problems, automating root cause analysis can inform predictive maintenance and predictive quality control. We’ll first explain these concepts and then show examples of how automation and artificial intelligence can help optimize these processes.
Identifying process causality in fault detection can be difficult when relying solely on process knowledge or experience. Predictive maintenance analyzes big data of the historical performance of equipment or production lines to forecast future failures and limit downtime. Here, big data, is the field that treats ways to analyze and extract information from data sets that are too large or complex to be dealt with by traditional data-processing techniques. This type of structural monitoring replaces manual inspections that require human intervention otherwise needed to prevent equipment failure.
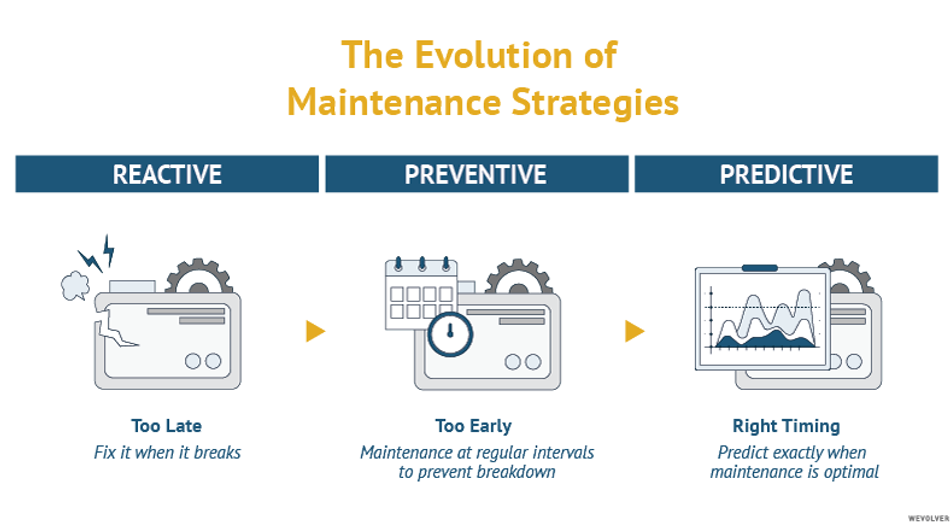
Predictive quality control aims to improve production quality and reduce costs through predictive alerts and automated anomaly detection. Advanced analytics may also aid in determining the variables that have the highest impact on quality issues, helping to prioritize issues. Real time operational visibility enables engineers to drill down into any individual machine and its sensors, to determine its impact of overall quality levels. Predictive quality alerts may be formulated based on business rules combined with automated anomaly detection, again to reduce human error and downtime.
Data can be incorporated into automated data analytics pipelines to enable simultaneous analysis and visualization in real time. There are several advantages to building automated data analytics capabilities. Having greater visibility of processes in real time enables engineers to manage systems more effectively by detecting when key performance indicators (KPIs) deviate.[7] In these cases, corrective action can be implemented faster to resolve issues and improve productivity. Operational reporting, using descriptive and diagnostic analytics is widely used across many manufacturing industries.
There are many examples of predictive maintenance, root cause analysis and optimization. Exemplary systems used in industry are Profit-per-Hour (PPH) maximization tools, Yield, Energy, and Throughput (YET) analytics and zero defect manufacturing.
- Profit-per-hour (PPH) maximization tools analyze all the relevant variables that impact the total profitability of a manufacturing company. They can take thousands of parameters within an integrated supply chain and manufacturing environment and provide intelligence on how best to capitalize on the conditions.[8] Data is combined from multiple sources that track incoming raw materials, inventory, automated processes performed by cyber-physical systems, and factory outputs. Analyzing these variables from across diverse parts of the organization can diagnose specific problems and aid in root cause analysis or find bottlenecks in production lines.
- By analyzing individual processes and process inter-dependencies, supply chains can be optimized for transportation times, assembly line flow rates, and fluctuations in demand. Such YET analytics ensure the most efficient operation of individual production units during operation, helping to increase their yields and throughput or to reduce the amount of energy they consume. These insights can help to build factory-wide flexibility by forecasting the impact of disruptions or optimizing energy consumption per individual unit.
- Lastly, zero defect manufacturing is a trend towards eliminating defects from manufacturing processes and may take several approaches including detection, repair, prediction, and prevention.[9]
A practical example of applying AI solutions to predict and prevent process inefficiencies comes from a semiconductor producer that had problems with broken wafers: by analyzing live and historical data from the wafer production line they were able to pinpoint the issue to the baking temperature. Then, correlations between statistical deviations in temperature and statistical deviations in the speed of the cooling conveyor belt were identified, enabling the company to solve the problem.[10] The power of such an AI solution lies in the ability to leverage unstructured data, like humans can.
Artificial Intelligence technology in manufacturing
Artificial Intelligence (AI) has been a topic of interest in the manufacturing sector since the 1980s. Early work in AI applied first-order logic (a statement may be true or false depending on the values of its variables, also called 'predicate logic') to the operational management of computerized production processes.[4] This approach permits a descriptive and non-procedural representation of knowledge related to the operation of a production line. The user only had to specify what to do and not how to do it. Many of the early examples of AI were characterized by structured contents (data that adheres to a relational model that can be analyzed) and centralized control structures.
To mimic human-like behavior in an automatized process, AI must be able to adapt to, and extract intelligence from the widest sources of data possible.[11] Whether it be text-based, visual, auditory or anything else that might hold information suitable for processing. Manufacturing environments are dynamic and decision problems are often unstructured. As the systems continuously change, logic operations for manipulating processes must be continuously reviewed. Fortunately, current AI tools have reached the inherent capability to respond to dynamic conditions within manufacturing settings.
Modern implementations of AI in manufacturing leverage a variety of techniques including Machine Learning (ML), and its subsets: Deep Learning (DL) and Reinforcement Learning (RL). These different subsets of AI all involve the construction of algorithms that learn from and make predictions on data. They may be distinguished based on their respective approaches to solving problems. ML algorithms can be classified according to the broad approaches employed in algorithm development: unsupervised learning, supervised learning and semi-supervised learning. The first, unsupervised learning, looks for previously undetected patterns in a data set with no pre-existing labels and with a minimum of human supervision, the second maps an input to an output based on example input-output pairs, while the last combines a small amount of labeled data with a large amount of unlabeled data during training.
Application of these models has been made possible by the availability of large datasets and the required computation infrastructure for training and deployment. Unsupervised and supervised ML approaches are widely implemented in process industries, accounting for between 90%-95% of existing applications.[12] ML can be used as a predictive modeling tool for both process and quality control. Different ML algorithms are suitable for different processes: For example, dynamic relationships between process data are particularly useful for process optimization. Hierarchical multilevel models may be used to describe the relationships between different key performance indicators (KPIs). Lastly, distributed ML can be leveraged to analyze metrics across diverse machines and processes with different data types and sampling frequencies.
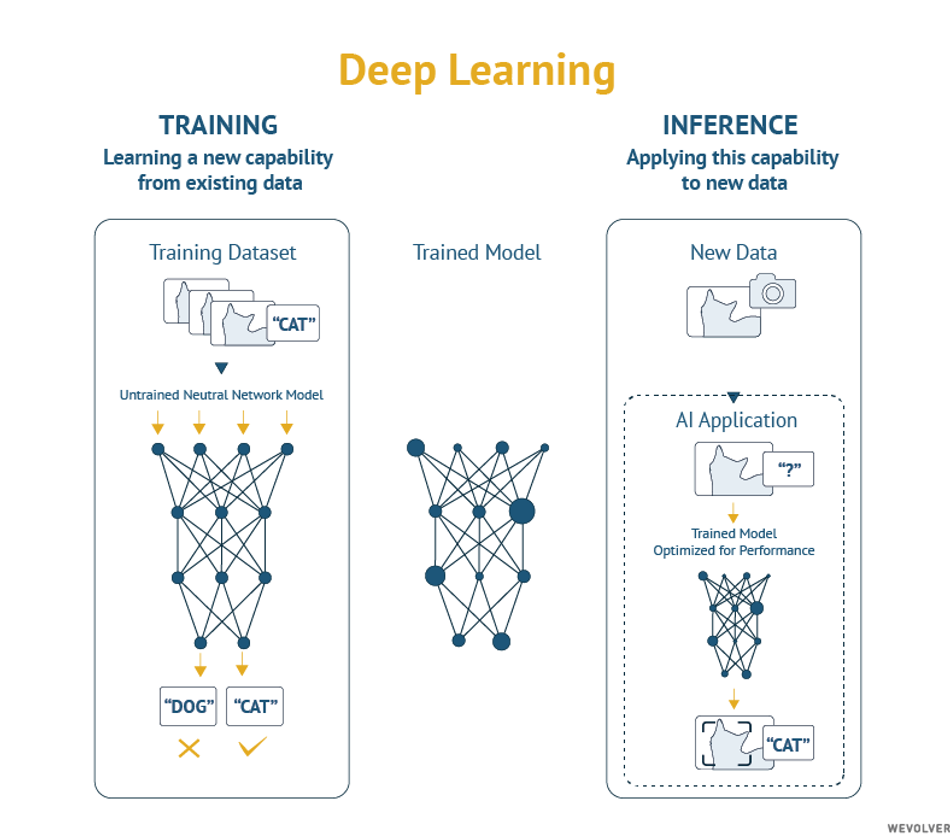
Both ML and DL derive their models from training datasets and apply that learning to new data. DL is a subset of machine learning, but contrary to basic machine learning, deep learning networks often rely on multiple layers of artificial neural networks (ANN), each contributing to different interpretations of a dataset. While basic machine learning models often need guidance from an engineer, a deep learning model can determine on its own whether a prediction is accurate or not.
DL has been effectively used in domains with complex data such as image classification. In contrast, RL approaches learn dynamically by adjusting actions based on continuous feedback mechanisms to optimize a desired output.[13] AI methods can be employed in isolation to specific processes or in combination by applying multiple methods sequentially or simultaneously.
Deep learning classification models have been used to improve data collection and organization, leading to the identification of possible defective products over multiple assembly lines.
A different AI subset, active learning, uses Natural Language Processing (NLP) to enable knowledge transfer directly from humans to collaborative robots (cobots).[14] Human-robot collaboration has recently gained traction in many manufacturing settings where they offer advantages in flexibility and can lower production costs. Unlike traditional manufacturing robots which are designed to work autonomously, cobots are intended to interact with humans.[15] For these interactions to succeed, the robot must recognize human intentions. A recent study implemented a recurrent convolutional neural network (RCNN)-based system that provides early recognition of specific human activities.[16] It has been employed to enable cobots to perform quality inspection cases without the assistance of a human. In a later article in this series we will dive more deeply in cobots and human-robot collaboration.

AI is influencing all aspects of Product Lifecycle Management (PLM), including the design phase. Increasingly Generative Design tools are used. These algorithms automatically generate optimized design options in 3D CAM modeling programs for achieving a set of design goals. Multiple iterations of a product can be designed and compared using different metrics and constraints. This enables engineers to quickly generate a range of design options to filter and select the ones that best meet their goals and constraints.
Another example of applying AI in the manufacturing industry is the automation of visual inspections.[17] We’ll return to a semiconductor production line once more: During the manufacturing process damages such as scratches or cracks can make the product unusable for further processing or end up in the final product. By combining a deep learning algorithm with computer vision techniques, defects can be detected in milliseconds, by quickly selecting a faulty area, and then using DL to assist in interpretation using heat maps.[18]
Implementing artificial intelligence in manufacturing
Data quality
High quality, curated datasets are essential for training ML models for specific scenarios, especially for neural networks. However, the availability and scope of datasets with appropriate quality standards is often limited. Data must also be cleaned, and its quality evaluated prior to applying the ML algorithms for model development. Missing data, outliers, and any differences between sample variables must be identified and addressed appropriately.[19] Because the use of AI systems depend on the precision of their models, this data preprocessing is an important and time-consuming step, requiring significant computational and storage capabilities.
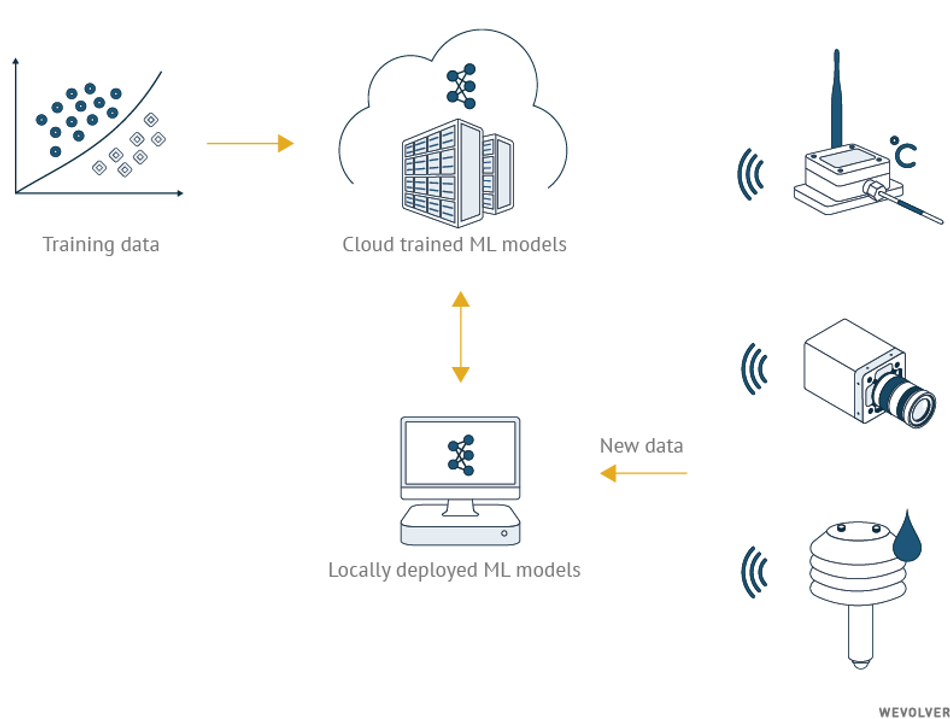
Cloud and Edge Computing
In Industry 4.0 applications, algorithms must be very adaptable in order to guarantee performance in real world settings. Both the training and scaling of ML models is challenging because large models can involve millions of parameters and large datasets. It requires the scalable storage, distributed processing, and powerful computing capabilities that cloud infrastructures provide.
Clearly, the amount of data and computations required to make manufacturing more intelligent comes at a price. Firstly, there are the literal costs of bandwidth usage, data storage, and computing. Secondly, the large amount of data can overwhelm a company’s networks and IT systems. A third problem is long and unpredictable latency, resulting from sending data to a cloud datacenter and performing computations there before sending information and commands back to the factory floor. This is especially problematic for time-sensitive use-cases.
A solution comes in the form of edge computing, and the concept of “AI at the Edge.” In such a computing environment edge devices (e.g. smart sensors or other industrial IoT devices) carry out a substantial amount of computation, storage, and communication locally. The edge nodes either preprocess data before transmitting it to the cloud, or execute the whole AI application locally from input to output, enabling efficient real-time intelligence at the point of need.[20]
Prototyping and Explainable AI
Current plug-and-play AI solutions are often developed to address only specific problems. Therefore, in most instances, companies must employ experimental and agile approaches to implementing AI tools more widely. Rapid prototyping and small-scale deployment are useful in determining the optimal analytical approach prior to rolling out operational AI systems.[21] This also reflects the role of smaller enterprises, and their possibilities in Industry 4.0.
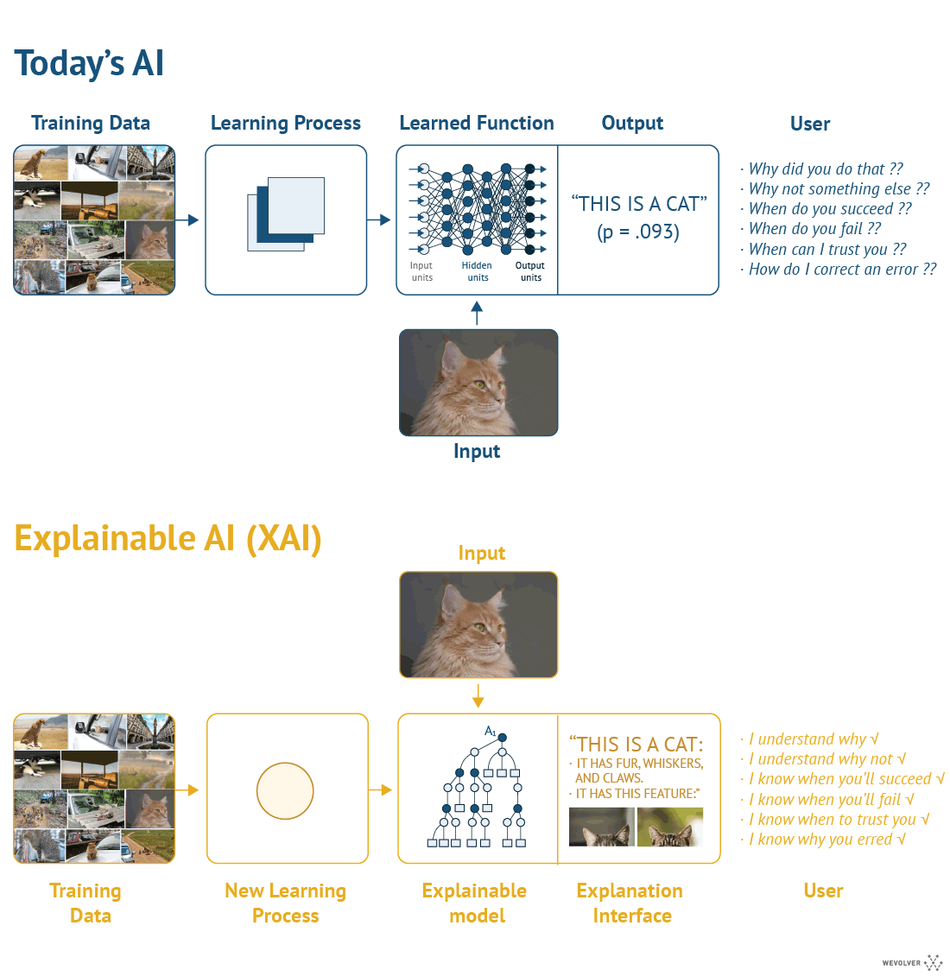
Furthermore, to realize the potential of advanced analytics, manufacturers must focus on developing capabilities and skills across the organization. To assist the development of AI-based models, it is imperative to build trust and transparency. One of those attempts is Explainable AI (XAI), referring to methods and techniques that apply AI such that its results can be understood by human experts. This is in contrast to the “black box” element of model design.[22,23] In machine learning, even model designers cannot explain why the AI arrived at a specific decision. XAI aims to make algorithms self-explanatory.
Conclusion: Combining data, analytics and AI to transform manufacturing.
Many companies have become interested in implementing advanced analytics, including AI-based approaches in manufacturing settings. Fast adopters can create a competitive technological advantage by using new tools to improve their production systems and resource allocation.[24]
Big data, advanced analytics, and artificial intelligence tools have the potential to transform the manufacturing sector. Advanced analytics can aid manufacturers in solving complex problems as well as revealing hidden bottlenecks or unprofitable processes. The exponential increase in the volume of data available for analysis has prompted the adoption of more sophisticated models, leveraging advances in AI and computational infrastructure. These technologies provide the link between machine automation, information automation and knowledge automation. Ultimately, the conversion of data to insights will drive manufacturing productivity, efficiency and sustainability in the near future.
Interested in learning more? Follow this five part series on Industry 4.0: Next week's article deep dives into the essence of connectivity and sensors that enable the future production environment.
About the sponsor: KUKA
KUKA is a global supplier of intelligent automation solutions. They offer everything from individual components to fully automated systems. KUKA was founded in 1898 in Ausburg, Germany, and currently has roughly 14,000 employees and sales of around 3.2 billion euro. Their mission is "making life and work easier."

On their website, KUKA provides more resources and a brochure about their vision on Industry 4.0 and the solutions they offer.
References
- Advanced Process Control in Semiconductor Manufacturing | LTI Blogs [Internet]. LTI2017 [cited 2020 Apr 9];
https://www.lntinfotech.com/blogs/advanced-process-control-semiconductor-manufacturing/ - Khan A, Turowski K. A Survey of Current Challenges in Manufacturing Industry and Preparation for Industry 4.0 [Internet]. In: Proceedings of the First International Scientific Conference “Intelligent Information Technologies for Industry” (IITI’16). Springer International Publishing; 2016. page 15–26.
http://dx.doi.org/10.1007/978-3-319-33609-1_2 - Unlocking the potential of the Internet of Things [Internet]. [cited 2020 Apr 10];
https://www.mckinsey.com/business-functions/mckinsey-digital/our-insights/the-internet-of-things-the-value-of-digitizing-the-physical-world - Zand P, Chatterjea S, Das K, Havinga P. Wireless Industrial Monitoring and Control Networks: The Journey So Far and the Road Ahead. Journal of Sensor and Actuator Networks 2012 [cited 2020 Apr 10];1(3).
https://www.researchgate.net/publication/238054328_Wireless_Industrial_Monitoring_and_Control_Networks_The_Journey_So_Far_and_the_Road_Ahead - The Economist. Data, data everywhere [Internet]. The Economist 2010 [cited 2020 Apr 10];
https://www.economist.com/special-report/2010/02/27/data-data-everywhere - Gandomi A, Haider M. Beyond the hype: Big data concepts, methods, and analytics. Int J Inf Manage [Internet] 2015;35(2):137–44.
http://www.sciencedirect.com/science/article/pii/S0268401214001066 - Li J, E. Blumenfeld D, Huang N, M. Alden J. Throughput analysis of production systems: recent advances and future topics. Int J Prod Res [Internet] 2009;47(14):3823–51.
https://doi.org/10.1080/00207540701829752 - Hammer M, Somers K, Karre H, Ramsauer C. Profit Per Hour as a Target Process Control Parameter for Manufacturing Systems Enabled by Big Data Analytics and Industry 4.0 Infrastructure. Procedia CIRP [Internet] 2017;63:715–20.
http://www.sciencedirect.com/science/article/pii/S2212827117302408 - Psarommatis F, May G, Dreyfus P-A, Kiritsis D. Zero defect manufacturing: state-of-the-art review, shortcomings and future directions in research. Int J Prod Res [Internet] 2020;58(1):1–17.
https://doi.org/10.1080/00207543.2019.1605228 - SEEBO. Root cause analysis.
https://www.seebo.com/root-cause-analysis-examples-in-manufacturing/ - Yao X, Zhou J, Zhang J, Boer CR. From Intelligent Manufacturing to Smart Manufacturing for Industry 4.0 Driven by Next Generation Artificial Intelligence and Further On [Internet]. In: 2017 5th International Conference on Enterprise Systems (ES). unknown; 2017 [cited 2020 Apr 10]. page 311–8.
https://www.researchgate.net/publication/321260252_From_Intelligent_Manufacturing_to_Smart_Manufacturing_for_Industry_40_Driven_by_Next_Generation_Artificial_Intelligence_and_Further_On - Ge Z, Song Z, Ding SX, Huang B. Data Mining and Analytics in the Process Industry: The Role of Machine Learning. IEEE Access [Internet] 2017;5:20590–616.
http://dx.doi.org/10.1109/ACCESS.2017.2756872 - Albertetti F, Ghorbel H. Workload Prediction of Business Processes -- An Approach Based on Process Mining and Recurrent Neural Networks [Internet]. arXiv [cs.DB]2020;
http://arxiv.org/abs/2002.11675 - Pazienza A, Macchiarulo N, Vitulano F, Fiorentini A, Trevisi A. A Novel Integrated Industrial Approach with Cobots in the Age of Industry 4.0 through Conversational Interaction and Computer Vision [Internet]. In: Italian Conference on Computational Linguistics. unknown; 2019 [cited 2020 Apr 10].
https://www.researchgate.net/publication/337077799_A_Novel_Integrated_Industrial_Approach_with_Cobots_in_the_Age_of_Industry_40_through_Conversational_Interaction_and_Computer_Vision - Matheson E, Minto R, Zampieri EGG, Faccio M, Rosati G. Human–Robot Collaboration in Manufacturing Applications: A Review. Robotics [Internet] 2019 [cited 2020 Apr 10];8(4):100.
https://www.mdpi.com/2218-6581/8/4/100/htm - Wang Z, Wang B, Liu H, Kong Z. Recurrent convolutional networks based intention recognition for human-robot collaboration tasks [Internet]. In: 2017 IEEE International Conference on Systems, Man, and Cybernetics (SMC). 2017. page 1675–80.
http://dx.doi.org/10.1109/SMC.2017.8122856 - Nalbach O, Linn C, Derouet M, Werth D. Predictive Quality: Towards a New Understanding of Quality Assurance Using Machine Learning Tools [Internet]. In: Business Information Systems. Springer International Publishing; 2018. page 30–42.
http://dx.doi.org/10.1007/978-3-319-93931-5_3 - Deka P. Quality inspection in manufacturing using deep learning based computer vision [Internet]. Medium2018 [cited 2020 Apr 9];
https://towardsdatascience.com/quality-inspection-in-manufacturing-using-deep-learning-based-computer-vision-daa3f8f74f45 - Xu S, Lu B, Baldea M, Edgar TF, Wojsznis W, Blevins TL, et al. Data cleaning in the process industries. 2015 [cited 2020 Apr 10];
https://www.semanticscholar.org/paper/5f238002da98d82ee09d9220c5aa950f2b81b541 - Li L, Ota K, Dong M. Deep Learning for Smart Industry: Efficient Manufacture Inspection System With Fog Computing. IEEE Trans Ind Inf [Internet] 2018 [cited 2020 Apr 10];PP(99):1–1.
https://www.researchgate.net/publication/325516518_Deep_Learning_for_Smart_Industry_Efficient_Manufacture_Inspection_System_With_Fog_Computing - Pöttner W-B, Seidel H, Brown J, Roedig U, Wolf L. Constructing Schedules for Time-Critical Data Delivery in Wireless Sensor Networks [Internet]. 2014;
https://doi.org/10.1145/2494528 - Sheh RK-M. “Why Did You Do That?” Explainable Intelligent Robots [Internet]. In: Workshops at the Thirty-First AAAI Conference on Artificial Intelligence. 2017 [cited 2020 Apr 10].
https://www.aaai.org/ocs/index.php/WS/AAAIW17/paper/viewPaper/15162 - Ribeiro MT, Singh S, Guestrin C. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier [Internet]. arXiv [cs.LG]2016;
http://arxiv.org/abs/1602.04938 - Manufacturing: Analytics unleashes productivity and profitability [Internet]. [cited 2020 Apr 10];
https://www.mckinsey.com/business-functions/operations/our-insights/manufacturing-analytics-unleashes-productivity-and-profitability