Vision-based learning technique for robots during training
Human-robot interaction focuses on teaching robots from third-person observations of demonstrations to make it invariant and robust to the embodiment differences.

02 Mar, 2022. 4 minutes read
![Real-world-demo cross-embodiment setting [Image Source: Research Paper]](https://image.wevolver.com/eyJidWNrZXQiOiJ3ZXZvbHZlci1wcm9qZWN0LWltYWdlcyIsImtleSI6IjAuNm15YzdqZ2x0bW1SZWFsLXdvcmxkLWRlbW9jcm9zcy1lbWJvZGltZW50c2V0dGluZy5wbmciLCJlZGl0cyI6eyJyZXNpemUiOnsid2lkdGgiOjgwMCwiaGVpZ2h0Ijo0NTAsImZpdCI6ImNvdmVyIn0sIndlYnAiOnsicXVhbGl0eSI6ODV9fX0=)
Training robots to learn new skills has been a complex process restricting the work for programmers and roboticists. Scientists who study human-robot interaction often focus on easing the robot training process for it to learn new tasks in an unstructured environment. Today, most of the techniques for teaching robots are limited to the use of remote hardware or imitating pre-recorded demonstrations. The idea of teaching robots through a self-learning mechanism by watching humans do the task— allows the deployment of these robots in a new setting. As fancy as it sounds, there are certain challenges faced by the vision-based learning process as there exists a clear embodiment gap between the human demonstrator and the robotic hardware that executes the task.
As reported by the existing research [1,2], even though humans and robots are capable of performing the same task, the differences in the physique can make easy tasks complex or even impossible to do. A team of researchers from Stanford University, Robotics at Google and the University of California at Berkeley collaborated to apply well-established reporting of human-robot interaction to focus on teaching robots from third-person observations of demonstrations [3]. The researchers identified the opportunity to investigate the scope of self-supervised methods for vision-based learning techniques while considering the differences in human-robot embodiments, like shape, action and end-effector dynamics.
Robots See, Robots Do
In the paper, “XIRL: Cross-embodiment Inverse Reinforcement Learning,” the researchers carried out work to solve the challenges of embodiment through self-supervised mechanisms of high-level task objectives from videos. Rather than focusing on the way humans perform tasks and relating it to robot training, the proposition summarizes the knowledge in the form of a reward function that is invariant to the embodiment differences. This means it is now possible to learn vision-based reward functions from cross-embodiment demonstration videos that are robust to the differences mentioned earlier.

“The learned rewards can be used together with reinforcement learning (RL) to teach the task to agents with new physical embodiments through trial and error,” the team explains in a Google AI blog post. “Our approach is general and scales autonomously with data — the more embodiment diversity presented in the videos, the more invariant and robust the reward functions become.”
Even in the presence of embodiment differences, there still exist visual cues that indicate the task objective. The fundamental idea behind the XIRL is to discover the key moments in the videos of different lengths and clusters to encode task progression. The work carried out in XIRL leverages the Temporal Cycle Consistency (TCC) [4] that aligns the video accurately while learning the visual cues for understanding the task objective without requiring any ground-truth correspondences. The reward function in the learning process is the negative Euclidean distance between the current observation and the goal observation in the learned embedding space. This reward function is then fed into a standard Markov decision process and uses a reinforcement learning algorithm to learn the third-person demonstrated behavior.
Transfer policies from humans to robots in simulation
Along with the cross-embodiment inverse reinforcement learning label-free framework, the team proposes a cross-embodiment imitation learning benchmark, X-MAGICAL that features several tried agents with different embodiments performing the same defined task including one thousand expert demonstrations for a single agent. “The goal of X-MAGICAL is to test how well imitation or reward learning techniques can adapt to systematic embodiment gaps between the demonstrator and the learner,” the team notes. “These differences in execution speeds and state-action trajectories pose challenges for current LfD techniques, and the ability to generalize across embodiments is precisely what this benchmark evaluates.
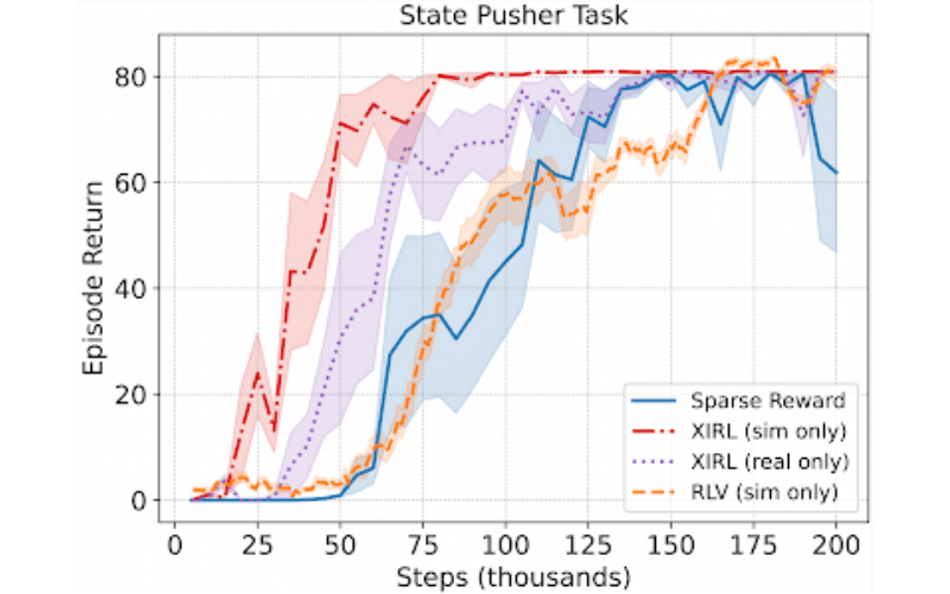
The results show that the XIRL significantly outperforms the alternative methods on both the X-MAGICAL benchmarks and the human-to-robot transfer benchmark. The team demonstrates the effectiveness of the proposed methodology by using third-person demonstrations on the State Pusher [5] setting where the reward function is first learned on real-world human demonstration and then used to teach a Sawyer arm to perform the task in simulation. The XIRL methodology trained on real-world demonstration (purple) reaches 80% of the total performance around 85% faster than the reinforcement learning with videos (RLV) as baseline (orange).
Conclusion on XIRL be used for learning RL policies
In the proposed approach to tackle the cross-embodiment imitation problems, the XIRL learns an embodiment invariant reward function technique using a temporal cycle consistency objective. Compared to baseline alternatives, XIRL reward functions are significantly more efficient. While the experimental results are quite promising, the team plans to show policy learning on a real robot post-COVID pandemic.
This research article was published on Cornell University’s research sharing platform, arXiv under open access terms.
References
[1] Abhishek Gupta, Coline Devin, YuXuan Liu, Pieter Abbeel, Sergey Levine: Learning Invariant Feature Spaces to Transfer Skills with Reinforcement Learning. DOI arXiv:1703.02949 [cs.AI].
[2] Pierre Sermanet, Corey Lynch, Yevgen Chebotar, Jasmine Hsu, Eric Jang, Stefan Schaal, Sergey Levine: Time-Contrastive Networks: Self-Supervised Learning from Video. DOI arXiv:1704.06888 [cs.CV].
[3] Kevin Zakka, Andy Zeng, Pete Florence, Jonathan Tompson, Jeannette Bohg, Debidatta Dwibedi: XIRL: Cross-embodiment Inverse Reinforcement Learning. DOI arXiv:2106.03911 [cs.RO].
[4] D. Dwibedi, Y. Aytar, J. Tompson, P. Sermanet, and A. Zisserman. Temporal cycle-consistency learning. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2019.
[5] K. Schmeckpeper, O. Rybkin, K. Daniilidis, S. Levine, and C. Finn. Reinforcement learning with videos: Combining offline observations with interaction, 2020