Data Warehouse Vs Data Lake Vs Data Lakehouse: Navigating the Modern Data Storage Landscape
Curious about Data Warehouse, Data Lake, and Data Lakehouse? This article breaks down their key differences and how they impact decisions on managing big data. Learn how these solutions shape industries and drive smarter data strategies.

13 Sep, 2024. 16 minutes read

Introduction
Driven by the exponential growth of data and the evolving needs of modern businesses, the landscape of data storage has undergone a significant transformation in recent years. As organizations grapple with vast amounts of structured and unstructured data, choosing the right storage solution has become crucial for maintaining competitive advantage and extracting valuable insights. Data warehouses, the traditional stalwarts of structured data storage, have been joined by data lakes, which offer flexibility for storing diverse data types. This has evolved to data lakehouses, a hybrid solution that combines the best of both worlds. Each technology serves distinct purposes and offers unique advantages in data management, analytics, and business intelligence.
For engineers and data professionals, a deep understanding of these concepts is essential to architect robust, scalable, and efficient data ecosystems that can adapt to the ever-changing demands of the digital age.
The Foundations of Modern Data Storage
Data Warehouse: The Structured Stalwart
The concept of a data warehouse was pioneered by Bill Inmon in the 1990s. Inmon, often referred to as the "father of data warehousing". Before data warehouses, traditional databases were primarily used for operational purposes like transaction processing, but they struggled to handle complex queries, reporting, and analysis efficiently. The limitations of databases, such as their focus on current transactional data and lack of historical data tracking, led to the development of data warehouses.
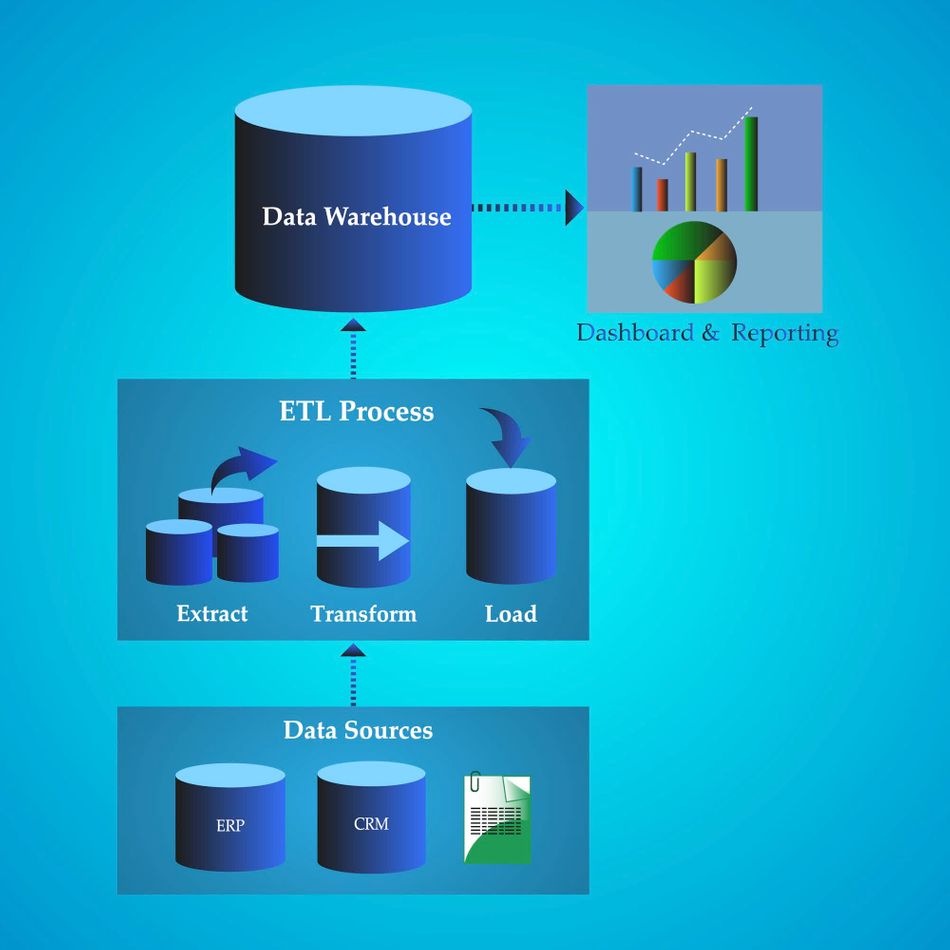
A data warehouse is designed to store, process, and manage large volumes of structured data from various sources within an organization. It can be likened to a water tank personalized as per your local use. Its primary purpose is to support business intelligence activities, decision-making processes, and analytical queries. Data warehouses are characterized by their highly structured and schema-on-write approach, where data is cleaned, transformed, and organized into predefined schemas before being loaded into the warehouse. This approach is known as the ETL approach, which stands for:
- Extract
- Transform
- Load
The ETL process can also be translated as - a “First think, then load” approach, i.e. it only works with structured data. For this, the raw data is first transformed into structured data before being loaded.
Characteristics of a Data Warehouse
Below are the outstanding characteristics of Data Warehouse:
- Integrated: Data warehouses consolidate data from multiple sources, ensuring uniformity in naming conventions, formats, and data structures. This integration helps in providing a consistent view of the organization’s data, irrespective of where the data originated.
- Time-Variant: Unlike operational databases that store only the current data, data warehouses store historical data. This characteristic allows organizations to track changes over time, enabling trend analysis and forecasting.
- Non-Volatile: Once data is entered into a data warehouse, it is not altered or deleted. This ensures the stability and integrity of the data, making it reliable for long-term analysis without concerns about updates affecting historical records.
- Subject-Oriented: Data warehouses are organized around key business subjects such as customers, sales, or products, rather than specific applications or functions. This orientation helps in analyzing data across different facets of the business for more in-depth insights.
The structured nature of data warehouses is one of their defining features. Data is typically organized in a dimensional model, often using star or snowflake schemas. This structure allows for efficient querying and analysis of complex relationships between different data elements. The rigid schema ensures data consistency and enables fast retrieval of information for reporting and analysis purposes.
Traditionally, data warehouses have been used for a variety of business-critical functions. These include financial reporting, sales analysis, customer behavior tracking, and performance monitoring. They excel in scenarios where organizations need to perform complex queries on historical data to identify trends, patterns, and insights that can drive strategic decision-making.
The advantages of data warehouses for business intelligence and reporting are numerous:
- They provide a single source of truth for an organization's data, ensuring consistency across different departments and systems.
- Data warehouses are optimized for read-heavy workloads, allowing for fast query performance on large datasets.
- They also support OLAP (Online Analytical Processing) operations, enabling multidimensional analysis of data from various perspectives [1].
The disadvantages of data warehouse include:
- High Costs: Implementing and maintaining a data warehouse can be expensive, involving hardware, software, and skilled personnel.
- Complexity: Integrating data from various sources and ensuring data quality can be complex and time-consuming.
- Limited Real-Time Data: Data warehouses often struggle to provide real-time data, as they are designed for batch processing rather than continuous updates.
Here's a table comparing key characteristics of data warehouses to other data storage solutions:
| Characteristic | Data Warehouse | Data Lake | Data Lakehouse |
| Data Structure | Structured data | Supports both structured and unstructured data | Supports both structured and unstructured data |
| Schema | Schema-on-write | Schema-on-read | Flexible schema |
| Data Processing | ETL (Extract, Transform, Load) | ELT (Extract, Load, Transform) | Supports both ETL and ELT |
| Query Performance | Optimized for complex queries | Can be slower for complex queries | Balanced performance |
| Data Quality | High (due to pre-processing) | Variable | High (with proper governance) |
| Scalability | Limited | Highly scalable | Highly scalable |
| Use Cases | Business intelligence, reporting. (Business analysts, data analysts) | Big data analytics (advanced), machine learning. (Data Scientist, big data engineers) | Combines BI and big data analytics. (Data engineers, data scientists, and business analysts) |
| Cost | Higher upfront cost | Lower initial cost | Moderate cost |
Data warehouses continue to play a crucial role in modern data architectures, particularly for organizations that rely heavily on structured data analysis and require consistent, high-performance querying capabilities for their business intelligence needs.
Data Lake: The Flexible Reservoir
The concept of the data lake was first introduced by James Dixon, the CTO of Pentaho, around 2010. He coined the term to describe a new approach to data storage that could handle the rising needs brought by the 3 Vs of big data—Volume, Velocity, and Variety. Traditional data warehouses, while efficient for structured data, struggled to manage the large, fast-moving, and diverse data generated by modern businesses, especially with the rise of IoT, social media, and web analytics. Data lakes emerged as a solution, allowing for the storage of massive amounts of raw, unstructured data that could be processed and analyzed later as needed.
A data lake is a centralized repository that allows you to store all your structured and unstructured data at any scale. It can be likened to a lake repository, where multiple water bodies from different sources combine, as compared to the water tank analogy of the data warehouse.
The core concept of a data lake is to have a single store for all of an organization's data, in its raw format, ready to be analyzed as needed. Unlike traditional data warehouses, data lakes do not require the data to be processed or transformed before storage. As compared to the data warehouse’s ETL, data lake utilizes ELT, where data is loaded first, and transformed later. This approach is often called as “Load first, think later”. It’s a central reservoir where data is centrally stored without analysis. This is easily understood byunderstanding the data lake architecture [2].
Characteristics of Data Lake
- Schema-on-read: The unstructured or semi-structured nature of data lakes is one of their key features. They can ingest data from various sources in its native format, without the need for predefined schemas or structures. This approach, often referred to as "schema-on-read," allows for greater flexibility in data storage and analysis. Data can be stored in its raw form and only structured when it's time to use it, enabling organizations to store data even when they're not sure how it will be used.
- High Agility and Flexibility: Data lakes offer unparalleled flexibility and scalability. They can accommodate massive volumes of diverse data types, from structured database tables to unstructured text files, images, and videos. This flexibility allows organizations to store data from multiple sources without worrying about compatibility issues. In terms of scalability, data lakes can grow to petabyte or even exabyte scale, leveraging distributed file systems and cloud storage technologies to expand seamlessly as data volumes increase.
- Data Variety: A data lake can ingest and store a wide range of data types, including structured data from relational databases, semi-structured data like JSON or XML, and unstructured data such as images, videos, and log files. This characteristic is key for data lakes, as they are designed to support diverse data formats for analytics and machine learning.
The use cases for data lakes in big data analytics and machine learning are extensive. They serve as a foundation for advanced analytics, allowing data scientists and analysts to explore vast datasets to uncover hidden patterns and insights. Data lakes provide the large, diverse datasets in machine learning applications necessary for training complex models. They support real-time analytics, enabling organizations to process and analyze streaming data for immediate insights. Data lakes also facilitate data discovery, allowing users to find and utilize relevant data for various analytical purposes.
Common data types stored in data lakes include:
- Structured data (e.g., relational database tables, CSV files)
- Semi-structured data (e.g., JSON, XML files)
- Unstructured data (e.g., text documents, emails)
- Binary large objects (BLOBs) such as images, audio files, and videos
- Log files from IT systems and web servers
- Social media data (e.g., tweets, posts, user profiles)
- IoT sensor data
- Geospatial data
- Time-series data
Below are a few advantages of data lake:
- Flexibility and Scalability: Data lakes can store a variety of data types, including structured, semi-structured, and unstructured data, without predefined schemas. This flexibility enables organizations to ingest data in its raw form, facilitating exploratory data analysis and machine learning.
- Supports Advanced Analytics: Since data lakes store raw, unprocessed data, they are ideal for advanced analytics, such as predictive modeling, real-time analytics, and artificial intelligence applications. Data scientists can access all forms of data, including logs, images, and documents, to perform in-depth analysis and build sophisticated models that leverage both structured and unstructured data.
- Cost-Effective Storage: Data lakes often rely on low-cost storage solutions, such as cloud-based or distributed systems like Hadoop. This makes them a more economical option than traditional data warehouses.
Along with the advantages, there are also a few disadvantages that data lake has:
- Complex Data Management: Managing a data lake can be complex, especially when dealing with large volumes of unstructured data. Without proper data governance, metadata management, and a clear strategy for organizing data, a data lake can become a "data swamp" where finding, understanding, and using data becomes inefficient and difficult, hampering its value.
- Slower Query Performance: Since data in a lake is stored in its raw form, without predefined schemas, querying can be slower and more resource-intensive compared to structured databases like data warehouses. The absence of indexing and optimized storage formats can lead to performance bottlenecks when running complex queries, especially in real-time analytics use cases.
- Security and Compliance Challenges: Storing diverse and often sensitive data types in a centralized repository raises significant security and compliance concerns. Ensuring proper access controls, encryption, and regulatory compliance (such as GDPR or CCPA) is challenging in a data lake environment.
Let’s compare the use-cases of data warehouse and data lake with simple examples:
Suppose the company’s management wants to view a monthly sales summary by region or product category. In that case, the structured nature of a data warehouse allows for fast, reliable querying of this information. On the other hand, a media company could use a data lake to store and analyze user interaction data, including viewing habits, preferences, and engagement metrics.
Data lakes have become an essential component of modern data architectures, enabling organizations to harness the full potential of their data assets for advanced analytics and machine learning initiatives. Their ability to store vast amounts of diverse data types in a cost-effective manner makes them invaluable for businesses seeking to become more data-driven and innovative in their decision-making processes. WIth the help of popular data lake platforms that power its architecture, this has become possible [3].
Recommended Readings: Big Data: The 3 V's of Data
Data Lakehouse: The Hybrid Powerhouse
The Data Lakehouse concept emerged in 2019, primarily championed by Databricks, a company founded by Ali Ghodsi and other creators of Apache Spark. The lakehouse architecture was introduced to address the challenges of managing separated data lakes and data warehouses. Traditionally, organizations used data lakes for storing raw, diverse data and data warehouses for running structured analytics. However, this separation often resulted in data duplication, inconsistent data governance, and the high costs of moving data between the two environments. The data lakehouse integrates the benefits of both architectures, combining the flexibility and scalability of a data lake with the data management features and high-performance queries of a data warehouse. This hybrid approach enables unified data management and advanced analytics on a single platform.
Characteristics of Data Lakehouse
- ACID transaction: They help in ensuring that all data operations are consistent, reliable, and fault-tolerant. This feature, traditionally found in data warehouses, allows users to safely update, delete, or insert data without worrying about corruption or incomplete operations.
- Unified Governance and Security: A data lakehouse provides integrated governance, ensuring consistent data security and access controls across both raw and processed data, addressing the data governance gaps in traditional data lakes.
- Support for Advanced Analytics and BI: The architecture is optimized for both BI workloads and advanced analytics, enabling organizations to perform batch and real-time analytics, machine learning, and complex queries from the same platform.
- Cost Efficiency: By combining the capabilities of data lakes and warehouses, organizations can avoid costly data duplication and expensive ETL (Extract, Transform, Load) processes. This results in lower storage and operational costs while still supporting both large-scale data storage and advanced analytics.
- Real-Time Analytics on Raw Data: The data lakehouse supports real-time querying and analytics on raw data directly from the lake. This removes the need for extensive preprocessing, allowing for faster decision-making and enabling advanced use cases like machine learning and predictive analytics on live data.
Data lakehouses integrate the schema enforcement and ACID transactions typically associated with data warehouses into the data lake environment. This combination allows organizations to maintain data quality and consistency while still benefiting from the ability to store and process large volumes of raw, diverse data. The lakehouse architecture typically implements a metadata layer on top of low-cost object storage, enabling efficient data management and querying capabilities.
The benefits of this hybrid approach are numerous:
- Unified data platform: Lakehouses eliminate data silos by providing a single repository for all data types and workloads.
- Cost-effectiveness: By leveraging cheap object storage and open formats, lakehouses can significantly reduce storage and computation costs.
- Improved data quality: The implementation of schema enforcement and ACID transactions ensures data consistency and reliability.
- Flexibility: Lakehouses support a wide range of data types and can adapt to changing business needs.
- Performance: Advanced indexing and caching techniques enable fast query performance on large datasets.
- Support for diverse workloads: From SQL analytics to machine learning, lakehouses can handle various data processing requirements.
However, below are a few drawbacks associated with data lake warehouse:
- Complex Implementation: Although a lakehouse offers unified data management, implementing it requires advanced expertise in big data technologies. Transitioning from separate data lakes and warehouses to a lakehouse can be technically challenging and time-consuming.
- Immature Technology: The lakehouse architecture is still relatively new, and some tools and technologies supporting it are not as mature as traditional data warehouse solutions. This can lead to limited tool support or stability issues in large-scale production environments.
- Data Governance Complexity: Managing consistent governance in a lakehouse can be challenging due to the variety of data types (structured and unstructured) and the need to apply robust governance policies across the entire system. Without proper tools and processes, organizations risk facing issues like data swamps or regulatory non-compliance.
Technical Deep Dive: Architectures and Technologies
Data Warehouse Architecture
Data warehouse architecture is designed to optimize the storage, retrieval, and analysis of large volumes of structured data. At its core, a data warehouse consists of several key components: data sources, staging area, ETL processes, central data repository, metadata repository, and data marts.
The central data repository is typically organized into three layers:
- Staging Layer: Raw data is loaded here for initial processing.
- Integration Layer: Data is cleaned, transformed, and integrated.
- Access Layer: Optimized for query performance and analysis.
ETL (Extract, Transform, Load) processes are crucial in data warehousing. They involve:
- Extraction: Pulling data from various sources.
- Transformation: Cleaning, validating, and restructuring data.
- Loading: Inserting processed data into the warehouse.
Two common schema designs in data warehousing are star schema and snowflake schema.
Star Schema:
- Central fact table surrounded by dimension tables
- Simple and fast for querying
Snowflake Schema:
- Extension of star schema with normalized dimension tables
- Reduces data redundancy but increases join complexity
Here's a comparison of popular data warehouse technologies:
| Feature | Teradata | Amazon Redshift | Google BigQuery |
| Scalability | High | High | Virtually unlimited |
| Performance | Excellent for complex queries | Very good | Excellent for large datasets |
| Data Loading | Parallel loading | Bulk and streaming | Streaming and batch |
| Pricing Model | Capacity-based | Pay-per-node | Pay-per-query |
| Maintenance | High | Medium | Low (fully managed) |
| Integration | Strong with enterprise systems | Strong with AWS services | Strong with Google Cloud |
Each technology has its strengths, and the choice depends on specific organizational needs, existing infrastructure, and scalability requirements.
Suggested Readings: What is an Edge Data Center: A Comprehensive Guide for Engineering Professionals
Data Lake Architecture
Data Lake Architecture is designed to store vast amounts of structured, semi-structured, and unstructured data in its raw form. Unlike data warehouses, data lakes offer flexible storage that can handle diverse data types without requiring predefined schema structures. Here's a breakdown of the architecture:
- Data Sources: Data lakes ingest data from a wide variety of sources, encompassing structured, semi-structured, and unstructured data. These sources include relational databases like MySQL or PostgreSQL, non-relational databases such as NoSQL systems, and streaming data from sensors or social media. The flexibility of a data lake allows it to accommodate diverse file types and formats, including CSV, JSON, images, and videos. This ability to handle different types of data without needing to enforce a predefined schema is a core strength of the data lake.
- Ingestion Layer: The ingestion layer is responsible for gathering and importing data into the lake. Data can be ingested in both batch and real-time modes, depending on the use case. Batch ingestion processes large volumes of data periodically, while real-time ingestion supports continuous streams from sources like IoT devices or web applications. This layer kicks off the data pipelining process, moving raw data from different sources into the data lake for further processing or storage.
- Storage Layer: The storage layer in a data lake uses object storage, which is scalable and cost-efficient. This layer allows for the storage of both structured and unstructured data in its native format. Data is often stored in zones—raw, processed, and curated—depending on its level of refinement. Raw data remains untouched, while processed and curated data undergo transformations for specific uses. Object storage systems like Amazon S3 or Azure Blob Storage are commonly employed in this layer, providing immense scalability at low costs.
- Metadata Layer: A robust metadata layer is crucial for organizing and managing data in a data lake. This layer tracks data attributes, schema, partitions, and lineage, ensuring efficient data retrieval. Metadata catalogs such as AWS Glue or Apache Hive Metastore allow users to search, index, and categorize data within the lake. This is essential for maintaining a clear understanding of the data, especially in an environment where various types of raw data are stored and managed without predefined structure.
- Data Processing Layer: The data processing layer is where raw data is transformed into usable information. This step typically involves ELT (Extract, Load, Transform) processes, where data is cleaned, validated, and transformed after ingestion. The processing layer is a crucial part of the data pipelining process, where frameworks such as Apache Spark, Hadoop, or Presto are used to handle large-scale data transformations and analytics. The transformed data can then be moved to more refined storage zones, enabling easier access and analysis.
- Analytics and Machine Learning Layer: The data lake supports complex analytics and machine learning (ML) workloads through its integration with powerful processing frameworks. This layer allows users to run batch processing for historical data analysis or stream processing for real-time insights. It is especially useful for data scientists who can extract, clean, and model large datasets for predictive analytics. Machine learning models can be trained directly on the lake’s data, facilitating advanced use cases like AI-powered decision-making and forecasting.
Data Lakehouse Architecture
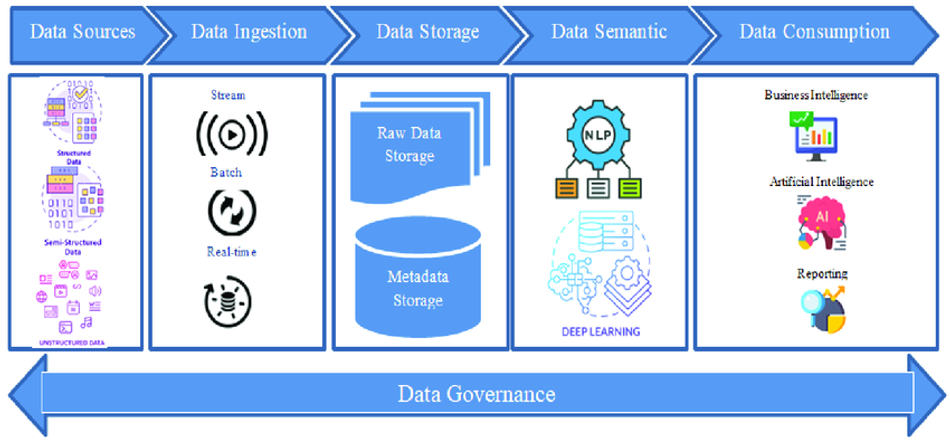
Data lakehouse architecture combines the best features of data warehouses and data lakes, creating a layered structure that supports both structured and unstructured data. The architecture typically consists of the following layers:
- Data Ingestion Layer: Handles data from various sources and formats.
- Storage Layer: Utilizes object storage for cost-effective, scalable data storage.
- Metadata Layer: Manages schema, partitioning, and transaction information.
- Query Engine: Optimizes data retrieval and processing for analytics.
- Data Access Layer: Provides interfaces for various data consumption patterns.
Technologies like Delta Lake, Apache Hudi, and Apache Iceberg play crucial roles in implementing the data lakehouse concept:
- Delta Lake: An open-source storage layer that brings ACID transactions to Apache Spark and big data workloads. It provides optimized layout and compaction for fast queries.
- Apache Hudi: Brings transactions and record-level updates and deletes to data lakes, enabling incremental data processing and streaming ingestion.
- Apache Iceberg: A table format for huge analytic datasets that brings the reliability and simplicity of SQL tables to big data, while making it possible for engines like Spark, Trino, Flink, Presto, and Hive to safely work with the same tables.
These technologies implement ACID transactions on data lakes by:
- Versioning data files to ensure atomicity and isolation.
- Using transaction logs to maintain consistency.
- Implementing optimistic concurrency control for managing concurrent operations.
- Providing snapshot isolation to ensure data consistency across queries.
Flowchart of data processing in a data lakehouse:
- Data Sources → Ingestion Layer
- Ingestion Layer → Raw Data Storage (Data Lake)
- Raw Data Storage → Data Processing (ETL/ELT)
- Data Processing → Refined Data Storage (Data Lakehouse)
- Refined Data Storage → Query Engine
- Query Engine → Data Access Layer (BI Tools, ML Models, etc.)
This architecture enables data lakehouses to provide the flexibility of data lakes with the performance and ACID guarantees of traditional data warehouses, making them suitable for a wide range of analytical workloads and data science applications.
Conclusion
Data warehouses, data lakes, and data lakehouses represent distinct approaches to enterprise data storage and analytics. Data warehouses excel in structured data management and complex query performance, making them ideal for business intelligence and reporting. Data lakes offer unparalleled flexibility in storing vast amounts of raw, unstructured data, supporting big data analytics and machine learning workflows. Data lakehouses emerge as a hybrid solution, combining the structured data management capabilities of warehouses with the scalability and flexibility of lakes.
Choosing the right solution depends on an organization's specific data needs, existing infrastructure, and analytical requirements. Factors such as data volume, variety, velocity, and intended use cases should guide this decision. As data ecosystems continue to evolve, it's crucial for organizations to stay informed about emerging technologies and best practices in data storage and management.
The future of enterprise data storage is likely to see further convergence of technologies, with solutions becoming more adaptable and capable of handling diverse data types and workloads. Cloud-native architectures and AI-driven data management will play increasingly important roles in shaping the next generation of data storage solutions.
Frequently Asked Questions
What is the main difference between a data warehouse and a data lake?
A data warehouse stores structured, processed data optimized for SQL queries and business intelligence, while a data lake stores raw, unstructured data in its native format, supporting a wide range of analytics use cases.
Can a data lakehouse replace both a data warehouse and a data lake?
While a data lakehouse combines features of both, it may not fully replace specialized data warehouses or lakes in all scenarios. It's best suited for organizations seeking a unified platform for diverse data workloads.
How do data lakehouses address the challenge of data silos?
Data lakehouses provide a unified architecture that can store and process both structured and unstructured data, reducing the need for separate systems and facilitating easier data integration and access across the organization.
What are the key considerations for migrating from a traditional data warehouse to a data lake or lakehouse?
Key considerations include data volume and variety, existing analytics workflows, required query performance, data governance needs, and the skills of your data team. A phased migration approach is often recommended.
How do data lakehouses handle data governance and security?
Data lakehouses typically offer features like ACID transactions, schema enforcement, and fine-grained access controls, combining the governance strengths of data warehouses with the flexibility of data lakes.
What role does cloud computing play in modern data storage solutions?
Cloud platforms offer scalability, elasticity, and managed services for data warehouses, lakes, and lakehouses, reducing infrastructure management overhead and enabling global data access and collaboration.
How do data lakehouses support real-time analytics compared to traditional data warehouses?
Data lakehouses often incorporate streaming data processing capabilities and support for low-latency queries, enabling real-time analytics on both historical and incoming data, which can be more challenging in traditional data warehouse architectures.
References
[1] IBM. OLAP vs. OLTP: What’s the difference? Link.
[2] Altexsoft. Data lake architecture: Link.
[3] Altexsoft. Popular data lake platforms: Link.
[4] Montecarlodata. 5 Key layers of Data Lakehouse Architecture. Link.