How to Build Computer Vision Models with Small Data Set?
Unsupervised domain adaptation is the solution to overcome the challenge of limited training data effectively.
22 Mar, 2023. 4 minutes read

Conventional computer vision development requires a vast amount of data
Typically, Computer vision AI models rely on vast amounts of training data to learn and improve their ability to recognize and interpret visual information. These models are trained using labelled data, which means that the data is annotated with information about what objects or features are present in the image. The more diverse and comprehensive the training data is, the better the model can generalize to new, unseen data. Without sufficient training data, computer vision models could not accurately recognize objects, understand scenes, and perform other visual recognition tasks. Therefore, gathering and labelling high-quality training data is a critical step in building effective computer vision AI models.
It is not always easy to get a huge amount of training data
However, not every industry has easy and affordable access to sufficient training data. This can be particularly challenging for industries where the data is proprietary or sensitive, such as security and defence, healthcare, or for niche industries where the available data may be limited.
For instance, in a defence use case such as detecting illegal swimmers across a strait using cameras, collecting tens of thousands of swimmer images to train the detection model can be a daunting task.

In such cases, current solutions include generating synthetic data, turning to third-party data providers or crowdsourcing platforms to gather or label training data, which can be time-consuming and costly.
Unsupervised domain adaptation makes the neural network smarter
In such situations, one solution to overcome the challenge of limited training data effectively is unsupervised domain adaptation (UDA). This technique can help build custom computer vision models with as little as 10% of the training data required for conventional methods.
To put it briefly, UDA is a technique to make the neural network smarter. It allows a model trained on a source domain to be adapted to perform well on a target domain with no labelled data available in the target domain.
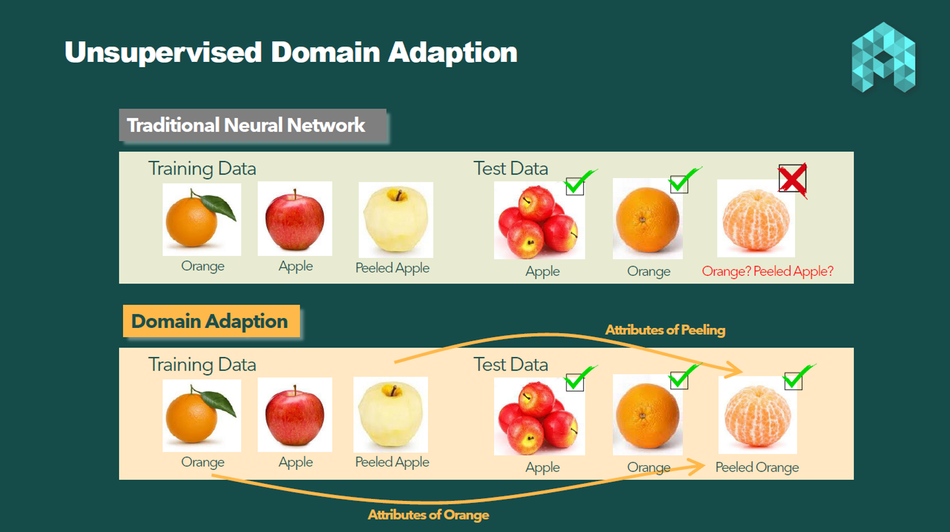
Here is a simple example of the UDA power in fruit classification.
Suppose we train an image classification model to recognize "orange (unpeeled)," "apple (unpeeled)," and "a peeled apple," and we assume its accuracy to be 100%. The model will work perfectly when the test data belongs to one of those three classes. However, it will fail to classify "peeled orange" because it was not part of the training set. To address this issue, we need to collect training data for this class.
Here's where UDA can save the day. By using UDA, the model can automatically and without supervision learn the features of "peeling" and "unpeeling" by comparing "apple (unpeeled)" and "peeled apple." Then it can generalize these features to "orange" and deduce the class of "peeled orange" without any additional annotation.
Mechanism of unsupervised domain adaptation
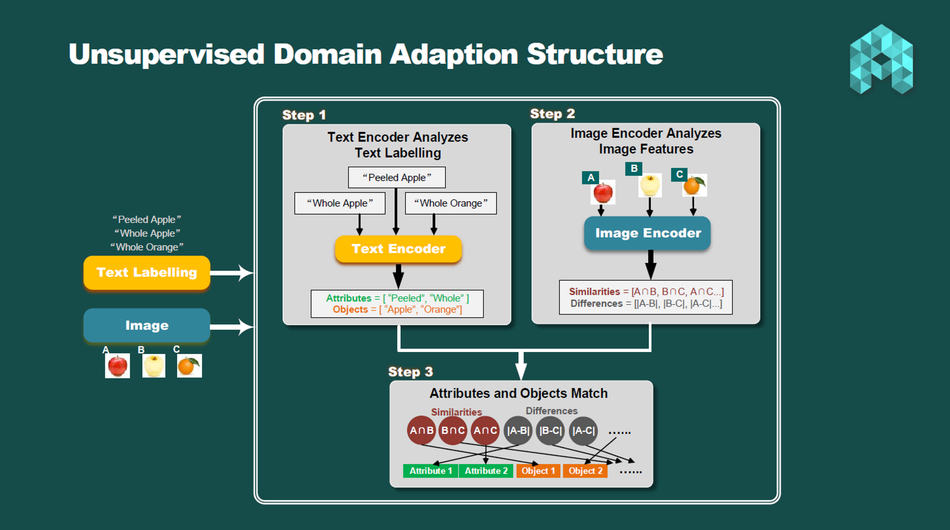
So, what is the secret mechanism behind UDA?
To put it simply, UDA needs two types of inputs to function.
- The images of all classes.
- The text labelling for each class.
After that, there are generally 3 steps to perform UDA.
Step 1: The text encoder analyzes text labelling.
The text encoder analyzes the text labelling by breaking it down into two groups - attribute group and object group. For instance, a text label like "blue jacket" would be broken down into [Attribute = "blue"] and [Object = "jacket"].
Step 2: The image encoder analyzes image features.
The image encoder finds similarities and differences among all image inputs. These insights are analyzed in the third step, along with the insights obtained by the text encoder in Step 1.
Step 3: Attribute and object match
The output of Steps 1 and 2 is combined and processed. This step matches the detected attributes and objects by the text encoder with the detected similarities and differences by the image encoder. That's how UDA can recognize "peeling" as an attribute in the fruit classification example mentioned earlier.
After this process, UDA gains more knowledge about different attributes and objects compared to traditional neural networks. When it applies these attributes and objects to new data, it exhibits stronger performance without annotations of new classes.
Benchmark on image segmentation task
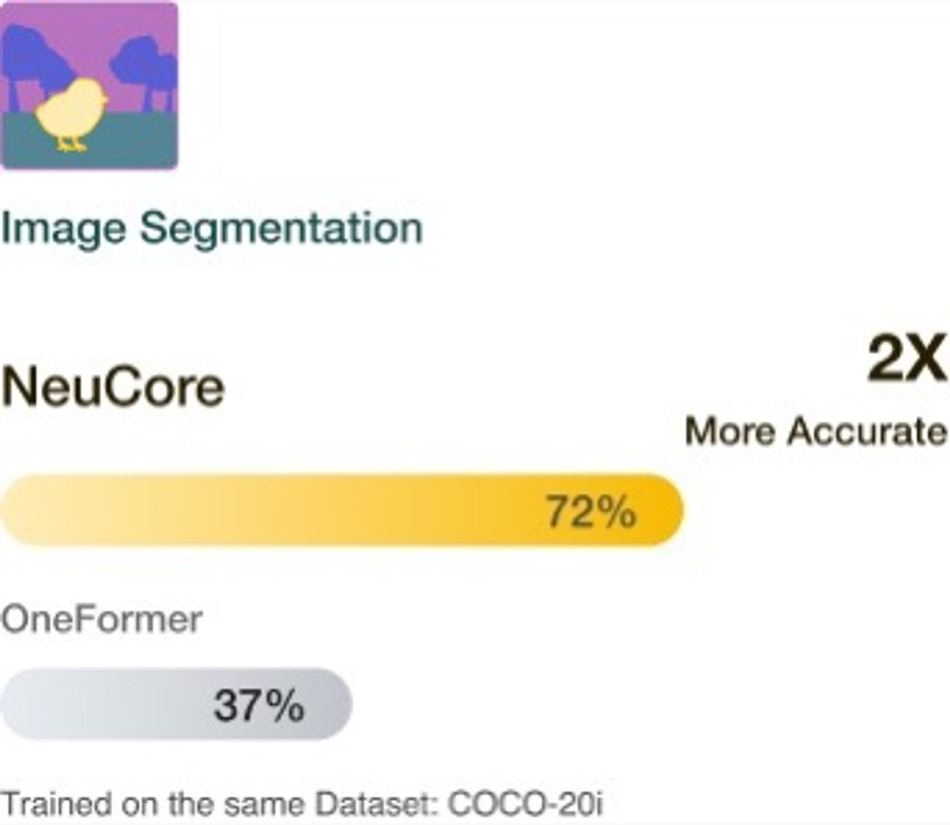
Let's take the image segmentation task as an example. NeuCore is a model that's empowered by UDA, while OneFomer is a state-of-the-art model commonly used for image segmentation.
When trained on the exact same dataset, NeuCore outperforms OneFomer by 2X. This also implies that NeuCore requires much less training data to achieve the same level of accuracy as OneFomer.
Future Trend of AI Development
While making neural networks larger with more data has been a popular trend in AI development, it's important to note that this approach is not the only way to improve their performance. Unsupervised Domain Adaptation (UDA) is a promising technique that could offer new opportunities for advancement.