Data Annotation for Computer Vision
5 Questions to Ask Before Getting Started with Data Annotation: What is data annotation? Why is it essential? What are common label types for models? How do AI-powered data annotation tools help with the computer vision labeling process? What’s the best way to get started?
01 Mar, 2022. 4 minutes read
Data annotation for object detection with Plainsight AI
This article was first published on
plainsight.aiWhat is Data Annotation for Computer Vision?
Data annotation, also called data labeling, is the process of adding labels or other information to a collection of data. A labeled dataset is often needed to train machine learning models. Most computer vision models need many annotated images or videos to learn patterns.
Data annotation can be quite a time-consuming process, especially when done manually. A rise in AI-powered labeling tools is revolutionizing how data annotation is being approached by providing features such as auto labeling, smart polygon selection, and tracking labeled objects from frame to frame.

What Are Common Label Types of Computer Vision Data Annotation?
Currently, most computer vision applications use a form of supervised machine learning, which means we need to label datasets to train the applications.
Choosing the correct label type for an application depends on what the computer vision model needs to learn. Below are four common types of computer vision models and annotations.
Object Detection:
Object detection models can learn to detect objects and estimate their location within a frame. These models are often used for counting and tracking objects in images or videos.
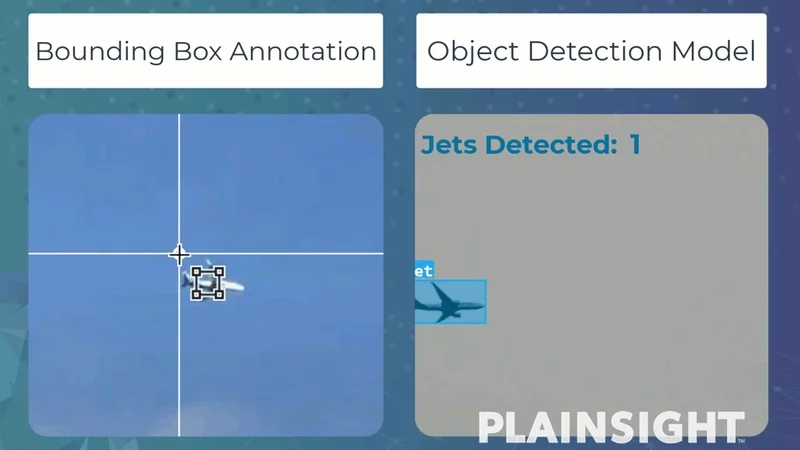
Object detection models usually require rectangle labels, also known as bounding boxes, to annotate objects inside the frames.

Labeling jets with a bounding box for object detection
Instance Segmentation:
Instance segmentation models learn to detect objects, identify each object’s location in the frame, and estimate the exact pixels of each object. These models can be useful if you need more precise pixel estimates for object interactions and higher accuracy.
These types of models require polygon labels to annotate the distinct pixels belonging to an object. Labeling polygons manually is known to be tedious and time-consuming, which is where Plainsight’s AI-powered polygon labeling tool, SmartPoly, can really shine.

Using Plainsight’s SmartPoly tool to build an instance segmentation model
Classification:
Classification models learn to predict if a defined object appears within an image or video but do not estimate its location or how many instances appear.
These models use classification or multi-classification labels that are applied to the entire image signaling if the frame contains a specific class.

Classification labeling and classification model example with Plainsight
Keypoint Estimation:
Body pose estimation, hand gestures recognition, and face keypoint models are typical examples of keypoint estimation models. These models learn from labeled points of specific features, such as the joints of a body.

Keypoint labeling and pose estimation model example with Plainsight
Why is Accurate Data Annotation Important?
When creating robust datasets for computer vision, many factors are essential to consider, such as data bias, source quality, project scope, and sample quantity. We’ll cover these topics in future posts. But for now, let’s focus on some common data annotation problems that may affect computer vision projects.
Drawing labels incorrectly around objects:
When labeling bounding boxes and polygons, it’s important to draw the lines just outside the object, but not too far outside and not inside the outline.
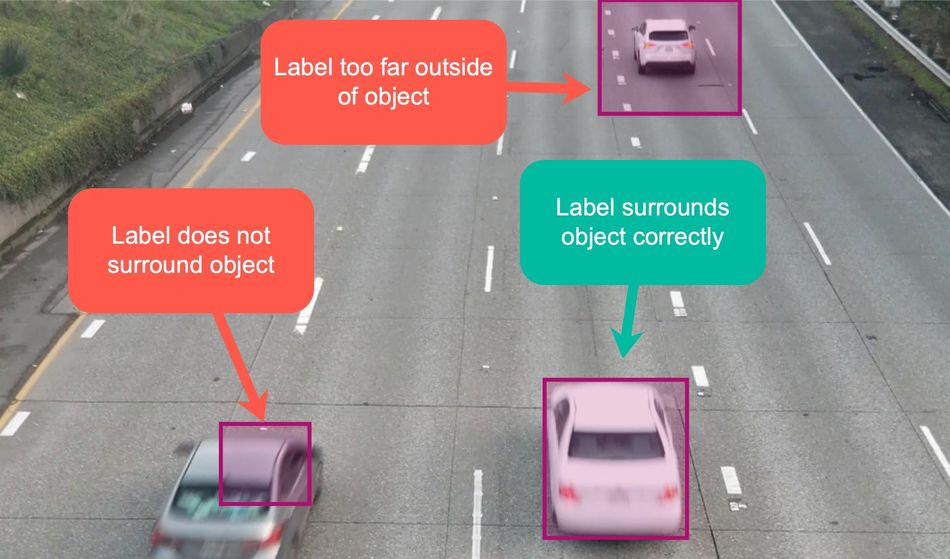
Example of improper and proper labels for object detection
Not labeling all object instances:
If an instance of an object type is not labeled while performing data annotation, the machine learning model may not learn the correct patterns needed for detection.

An example of skipping an instance of an object while performing data annotation
Unclear or no labeling instructions:
It’s essential to have precise data annotation instructions for every project, especially when handing off the task to a separate data labeling team or service. Embedding good and bad examples of labeled objects can help ensure the data annotation is performed correctly.
What is the Most Efficient Way to Get Started with Data Annotation?
The most efficient way to annotate video and images for computer vision is to use an end-to-end toolset like Plainsight’s vision AI platform. Plainsight allows team collaboration, labeling instructions, dataset version control, AI-powered data annotation, and even no-code model training, and deployment.
Having all these features in a single platform makes every step of the computer vision process faster and simpler–all the way from labeling, through model training, and model deployment.
How can AI-Powered Annotation Tools Save You Time?
AI-powered data annotation methods can drastically reduce time and resources spent on the labeling process. With Plainsight, these methods are now accessible to everyone.
Use AutoLabel to annotate images automatically:
Train custom models or select from pre-trained objects for recognition, and Plainsight will automatically apply data annotations to images. All data annotations are easily adjustable if needed as you QA the project.

Use SmartPoly for smart polygon selection:
Save time labeling polygons for segmentation by enabling the SmartPoly tool and drawing a simple rectangle to return a segmented object. Easily adjust the polygon if needed by clicking on it.

Use TrackForward to track labeled objects frame to frame:
Track annotated objects from image to image to automatically apply polygons or bounding boxes to segmented video sequences. This feature is great for objects not yet available for AutoLabel models.

Key Takeaways
- Data Annotation for computer vision is the process of adding labels to images or video frames.
- Choosing the right type of label depends on the type of computer vision model you want to build.
- Without the use of an AI-powered data annotation tool, data annotation can be time-consuming and tedious.
- Using an end-to-end platform like Plainsight makes every step of the computer vision process, from labeling, model training, and model deployment, simpler and easier.
Alternatively, if you are looking to partner with a team of computer vision experts to tackle an upcoming vision AI project, make sure to reach out to our team and schedule a demo. Contact Plainsight to learn more.
About the Author and Plainsight:
Sage Elliott — Lead Developer Evangelist. Helping Plainsight make AI approachable for everyone.
Plainsight’s vision AI platform streamlines the end-to-end machine learning process. From data annotation through deployment, customers quickly create and successfully operationalize their own vision AI applications to solve highly diverse business challenges.