One-short learning approach, inspired by human intuition, works with just one training image
Designed to dramatically reduce the amount of training data needed for an image recognition system, this one-shot approach "inspired by nativism" takes a leaf from humans' ability to intuit and abstract.

04 Feb, 2022. 4 minutes read

By placing images on a virtual "rubber sheet," this ML approach needs little training.
The human ability to generalize information, using abstraction to recognize everything from the shapes of letters and numbers to abstract doodles based on very limited experience, may be within reach of machine learning systems thanks to work by researchers at the Universities of Chicago and Illinois at Urbana-Champaign.
In a paper dubbed “Learning from One and One One Shot,” the research team details an approach “inspired by nativism” which allows a character recognition system to achieve human-like accuracy based on as little as one example image per class — by imagining the images, suitably processed and simplified, as being printed on a rubber sheet which can be stretched, squeezed, and bent into a range of shapes.
Abstracted learning
Machine learning systems are powerful, but suffer from one major drawback: The need for extensive training, expensive both computationally and in the datasets they ingest. A leading object recognition model may, for example, be trained on tens or even hundreds of thousands of images which have to be sourced and processed.
Approaches which look to dramatically reduce the size of training datasets are commonly referred to as “few-shot learning;” those, like this work from Haizi Yu, Igor Mineyev, Lav R. Varshney, and James Evans, which go still further to being able to generalize a single example of a given class are thus “one-shot.”
It’s a powerful idea, and one which draws inspiration from the human brain — specifically, its capacity for abstraction. “Our mind freely conceives more equivalent examples,” the researchers explain, “ignoring low-level variations in between. Babies can differentiate things quickly based on general appearance, i.e., how things ‘look in general’ (topologically, geometrically, structurally, etc.) recognizing that they may be translated, rotated, scaled, or deformed.”
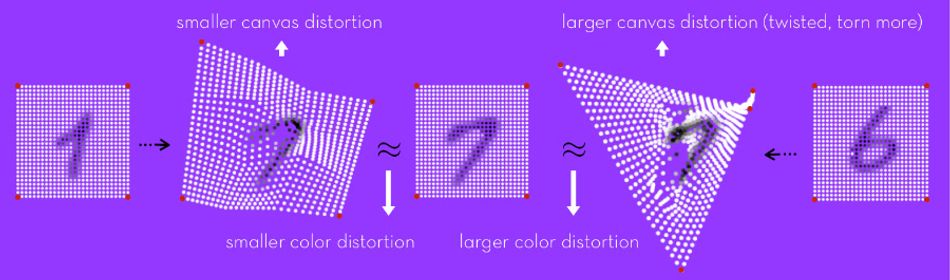
Giving a machine the ability to do the same, though, is a challenge. The team’s approach: Applying an image to be recognized to a deformable canvas, effectively a virtual rubber sheet, which can be transformed in a variety of ways. The less the virtual rubber sheet needs to be deformed to make a match, the closer the two images must be — giving the system an equivalent to human intuition.
Combined with two processing steps to lift gradient descent — an optimization algorithm designed to find the local minimum of a differentiable function — to multiple levels of abstraction, using multi-scale canvas lattices and color blurring on the source image, the result is something which is designed to excel at “mimicking human abstraction ability.”
Promising performance
The approach would appear to pay dividends. Used for few- and one-shot learning on the MNIST, EMNIST-letters, and Omniglot benchmarks — the latter requiring recognition of a range of alphabets, including the fictional script used in the sci-fi cartoon series Futurama — the intuitive model “outperforms both neural-network based and classical ML [Machine Learning] in the ‘tiny data’ or single-datum regime,” the researchers report.
Notably, the researchers say this is achieved without pre-training with additional background data — giving their approach the advantage of simplicity over the few-shot rivals against which it was tested. For the MNIST benchmark, the one-shot approach — using only a single training image per class — offered an impressive 80 per cent accuracy, rising to 90 per cent with just four images per class.
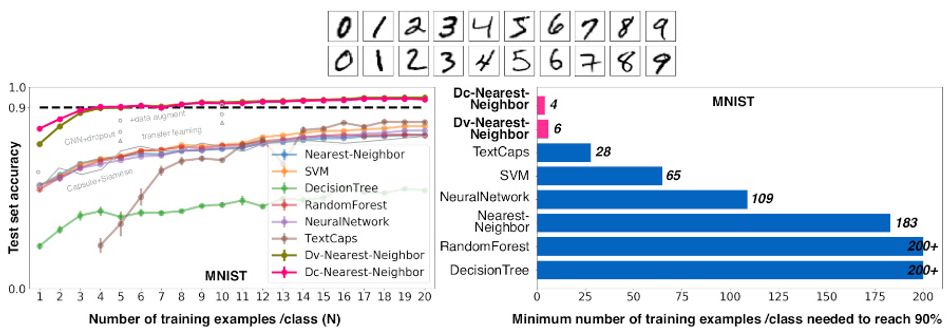
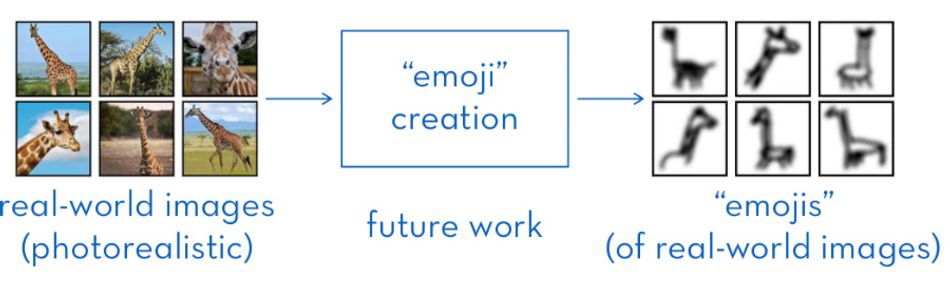
The team’s approach has other advantages. Transformation of the image on its virtual rubber sheet can be visualized as an animation, a great asset when it comes to helping humans figure out how the system draws its conclusions. It also offers potential for unsupervised learning, while the team proposes that the approach — tested only on character-like imagery — could be extended to support recognition of real-world images by simplifying photo-realistic imagery into “emojis.”
There are caveats, however. The team admits that the dominance exhibited in the paper “diminishes when training size increases,” showing that what may be a great approach for one- and few-shot learning on relatively simple tasks may not be able to compete as the complexity rises.
In a review of the paper following its submission to the Tenth International Conference on Learning Representations (ICLR 2022), one reviewer noted that the approach detailed in the paper “is [only] suitable for images with simple topological structure, such as the character images” while others warned of “fundamental aspects of the approach that might prevent it from scaling.”
Despite the paper’s rejection from the conference, the team behind it appears upbeat about its potential. “This paper is a first step towards a general theory of a comprehensive, human-like framework for human-level performance in diverse applications,” the researchers optimistically conclude.
A copy of the latest revision of the paper is available on Cornell’s arXiv.org preprint server.
Reference
Haizi Yu, Igor Mineyev, Lav R. Varshney, James A. Evans: Learning from One and Only One Shot. DOI arXiv:2201.08815v1 [cs.CV]