Making TinyML Even Tinier with Neuton.AI and Nordic
How a no-code TinyML platform and a leading low-power wireless chipset maker joined forces to push AI into the edge in just a few kilobytes.

16 Sep, 2025. 7 minutes read

Introduction
What if your microcontroller could host a neural network smaller than a tweet?
That size is enough to unlock gesture recognition, health monitoring, or predictive maintenance on the smallest devices. These are the kinds of tasks that have long seemed out of reach for highly constrained hardware. For developers and product designers, the main barrier has been the trade-off between size and performance in TinyML.
TinyML promises intelligence everywhere, but most frameworks still produce models too large for 8-bit or 16-bit microcontrollers (MCU) or too inaccurate once compressed. On top of that, building and optimizing such models requires deep machine learning (ML) expertise. Even with tools like pruning, quantization, or TensorFlow Lite, developers still face steep complexity and limited results.
Neuton.AI approaches this problem differently. The company built a patented novel framework that grows deep learning models neuron by neuron, automatically organizing the network for minimal size without losing accuracy. In practice, the models can be up to 1,000 times smaller, require fewer coefficients, and run inference much faster than those built with common frameworks like TensorFlow. The result is an automated, no-code TinyML platform that produces models small enough to run on nearly any microcontroller. In 2025, Nordic Semiconductor acquired Neuton.AI to bring this capability into its wider ecosystem of ultra-low-power wireless solutions. The acquisition marks a step forward in making AI deployment at the very edge practical, efficient, and scalable.
Neuton.AI and the Future of TinyML
TinyML has long promised to make edge devices smarter. Neuton.AI delivers on that promise by proving that models measured in kilobytes can still deliver real accuracy and performance.
It provides an end-to-end automated pipeline that transforms raw data into ultra-compact, high-performance AI models. Developers upload data, often in simple formats like CSV. Neuton handles preprocessing, feature extraction, and model building automatically. The output is a compiled C library that can be embedded directly into a microcontroller or sensor.
Because the process is automated, developers do not need expertise in data science or neural network design. Feature extraction – another important pillar of any successful edge-ai use-case is completely automated. There is no need to manually adjust hyperparameters, design architectures, or apply model compression. Neuton’s framework self-organizes, selecting features and building a network that is already tuned for efficiency. Built-in quantization enables 16-bit and even 8-bit deployment with minimal overhead.
For developers, this means significant time and effort saved. Building and tuning models by hand can take weeks or months. Neuton reduces this process to a single iteration, often within hours. In other words, models are ready to deploy directly on hardware, and the platform supports 8-, 16-, and 32-bit MCUs, giving teams flexibility across device classes.
Neuton also provides access tiers. A free tier allows individuals and smaller teams to experiment with tutorials and reference projects. A premium tier supports organizations with production-ready requirements, including custom AI services, SLA-backed support, and on-premise deployment. The result is a platform that makes TinyML accessible to a much wider audience of developers.
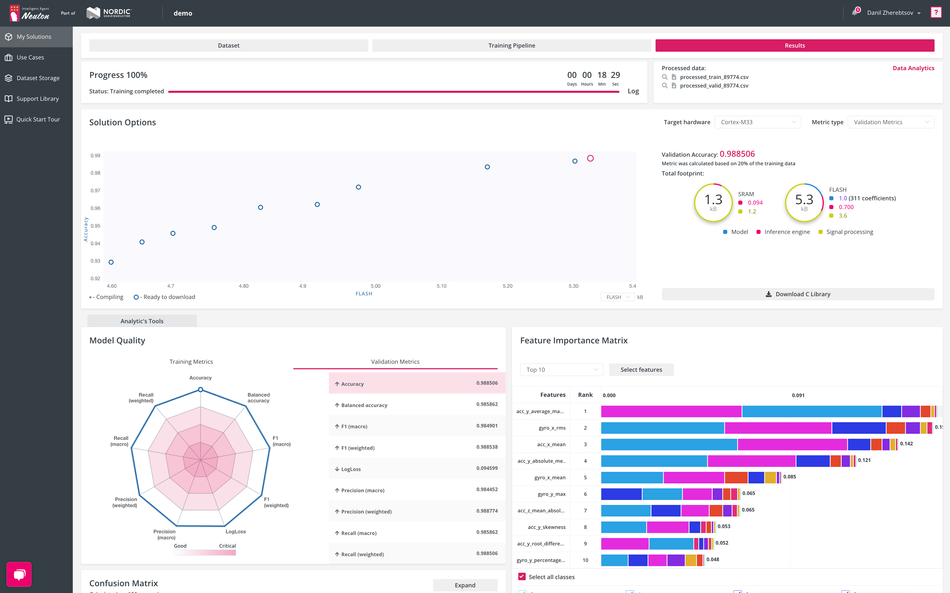
Tiny Models, Real Results
Size has always been the barrier to running machine learning at the edge. Only models that fit within a few kilobytes can run on small microcontrollers, yet shrinking models has usually meant giving up accuracy. Tests have shown that Neuton’s models can be hundreds to even a thousand times smaller than those produced by common frameworks, while also using fewer coefficients and achieving faster inference. This level of compactness turns tasks once thought impractical on small microcontrollers into deployable features.
Compact by Design
The average Neuton model size is less than 5 KB, including the network, processing code, and inference engine. By comparison, frameworks like TensorFlow Lite often produce models many times larger, even after compression.
This efficiency comes from a patented neural framework that builds networks differently. Instead of starting with a large structure and trying to shrink it later, Neuton grows the network in a controlled way, only adding what is necessary. Several design features make this possible:
Adding neurons one by one based on constant validation
Using global optimization instead of backpropagation to avoid training pitfalls
Employing sparse connections to reduce weights and parameters
Self-tuning activation functions, allowing fewer layers with the same performance
Together, these methods produce models that are small by design rather than by compression, which is why they can stay accurate while fitting into just a few kilobytes.
Benchmarks as Proof
The advantages of Neuton’s design become clear in benchmark testing across various application areas.
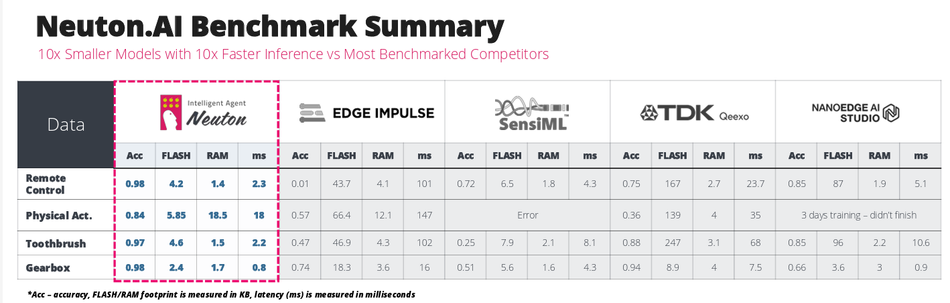
In gesture recognition, Neuton models were measured against TensorFlow Lite equivalents. The outcome showed models 10 to 14 times smaller and ran inference 19 to 44 times faster. Despite the size reduction, accuracy held steady. This matters for wearables or rings with limited memory and processing power. A model that efficient can make gesture-based control practical without draining the device battery.
In industrial fault detection, a gearbox monitoring model reached 98 percent accuracy while staying under a 3 KB footprint. Inference took less than a millisecond (up to 20 times faster). This enables equipment to monitor its own health in real time, spotting early signs of failure before they become costly breakdowns.
In healthcare monitoring, arrhythmia detection models achieved 96 to 98 percent accuracy while fitting into roughly 4 KB. This means even small medical devices, like patches or portable monitors, could run reliable heart monitoring locally, reducing the need for constant connectivity to the cloud.
These results, validated across open-source and proprietary datasets, show that Neuton’s models are both compact and production-ready. This combination of efficiency and reliability is what drew Nordic Semiconductor to integrate the technology into its portfolio.
Why Nordic Acquired Neuton
Nordic Semiconductor is widely recognized for its leadership in ultra-low-power wireless and embedded SoCs. Its chips form the backbone of many Bluetooth Low Energy devices, wearables, and IoT systems. By acquiring Neuton.AI, Nordic extends its capabilities beyond connectivity and into intelligence at the very edge. The addition of Neuton’s TinyML platform makes it possible to run always-on neural networks directly on microcontrollers, even in devices that must operate for years on a single battery. This aligns closely with Nordic’s focus on efficiency and resource-constrained design.
“Embedded AI will now become more accessible and scalable than ever. Neuton’s advanced ML technology enables effortless integration and trusted intelligence for next-generation edge AI devices.” — Oyvind Strom, EVP Short-Range at Nordic Semiconductor |
For developers, the acquisition means a smoother path to building intelligent devices. Neuton models are being integrated into Nordic’s edge AI ecosystem, supported by reference implementations and example projects. This lowers the barrier to adoption, allowing engineers to move from prototype to production with fewer steps and less risk. In practice, it shortens development cycles and makes advanced functionality more accessible to teams of all sizes.
The strategic move also positions Nordic to capture a growing market. TinyML chipset shipments are projected to reach nearly six billion dollars by 2030, and demand for solutions that combine connectivity with local intelligence will only accelerate. With Neuton’s technology, Nordic can offer a differentiated platform that blends low-power hardware with automated model creation.
Looking ahead, the acquisition supports Nordic’s long-term vision of becoming more than a chip supplier. By bringing together hardware, AI tooling, and ecosystem support, the company is building an end-to-end enablement strategy for edge AI and IoT. This vision places Nordic at the center of a future where intelligence is not confined to the cloud but embedded into everyday devices at the smallest scale.
Solving Core TinyML Problems
TinyML teams consistently run into three barriers: complexity, the accuracy–footprint trade-off, and deployment friction. Neuton’s approach lowers these hurdles in ways that matter for developers.
The Complexity Problem
Building models for constrained hardware involves careful preprocessing, feature selection, and long cycles of hyperparameter tuning. On MCUs, the constraints start with memory hierarchy and tool support. Typical devices juggle tight SRAM and flash budgets, so even intermediate activations can exceed available memory unless the model and runtime are co-designed.
Surveys note that common TinyML toolchains still demand hardware-aware choices and nontrivial integration work, especially when you leave well-trodden paths. Neuton removes this burden by automating preprocessing, feature selection, and topology growth. You upload data and receive an optimized, MCU-ready library, which reduces the need for architecture design and hand-tuning.
The Accuracy vs Footprint Problem
Research frames “accuracy versus footprint” as the field’s most persistent challenge. Larger models tend to perform better, yet MCUs cap both memory and compute; transformer-style attention only sharpens this tension. The practical result is a trade that often cuts accuracy to meet a kilobyte-scale target.
Neuton addresses the problem at construction time rather than after the fact; it grows networks neuron by neuron, uses sparse connectivity, and stops when further capacity no longer improves results. That process yields inherently compact graphs that preserve accuracy within strict footprint and latency budgets.
The Deployment Problem
After training, many frameworks still require conversion, quantization, and hardware-specific tweaks to reach a runnable binary. Surveys also highlight portability gaps across heterogeneous MCU families and the lack of uniform evaluation beyond accuracy alone.
Neuton closes this gap by emitting ready-to-run C code with built-in 16- and 8-bit quantization so that teams can deploy on common 8/16/32-bit MCUs without extra post-processing or per-target rework.
By removing complexity, preserving accuracy in compact footprints, and simplifying deployment, Neuton clears the primary hurdles that have long hindered TinyML projects. What once required expert teams and long optimization cycles can now move from dataset to on-device inference in a fraction of the time.
Conclusion
Neuton addresses three of the biggest barriers in TinyML. Its models are compact enough for the smallest microcontrollers yet accurate enough for real applications. With Nordic’s ecosystem and reach, these capabilities can scale across industries, bringing intelligence to more devices at the very edge.
The next wave of TinyML will be built on models that fit in kilobytes and run anywhere. Neuton and Nordic are making that possible, and it starts with experimenting today.
Try building an ultra-tiny model with your own data at lab.neuton.ai or connect with the Neuton team to explore how edge AI can power your next project.
Check out Nordic Semiconductor at CES 2026: Venetian Expo, Halls A-D 52039 – Smart Home.