Keyword Spotting in Edge Device
Ultra-low-power MCU’s and highly efficient purpose-built chips are bringing voice to the edge.

Last updated on 28 Sep, 2020. 7 minutes read

Voice command will continue to become a natural and broadly accessible method of interacting with technology. As described in our previous article, Voice At The Edge Helps Technology Work For More People, controlling devices with speech offers a huge range of advantages to users and designers.
Devices with voice interfaces are expected to rise from 3 billion devices worldwide to 8 billion by the end of 2035. These won’t just be more sophisticated versions of the home assistants that we know today, but a whole new range of devices and applications that will offer natural voice interaction.
In this article, we dive deeper into how voice command on edge devices works, and take a look at the leading low power devices available for voice command system design by examining a recent white paper from Syntiant.
The basics of keyword spotting
Smart devices are always active - listening for the predefined “wake” up instruction, such as "Alexa," "Ok Google," etc. This action is commonly known as keyword spotting (KWS). When a keyword is detected, the device wakes up and its full-scale voice recognition is activated either on the cloud or on the device. In some devices, keywords are also used as voice commands, for example, ‘hello, start, stop’ in a voice-enabled robot vacuum.
As a KWS system is always-on, it must have very low power consumption. A KWS system also should detect the spoken keywords with high accuracy and low latency to attain the best user experience. Low power consumption is especially important for portable devices, such as smartphones and wearables.

These tough conflicting system requirements, in combination with the increasing amount of voice command applications and audiences, make KWS a hugely relevant research area.
Until recently, the only devices capable of performing KWS at edge-compatible power levels were low-power microcontroller units (MCUs) and digital signal processors (DSPs). Processor-designer, Syntiant, has recently introduced the NDP10x series of its Neural Decision Processors (NDPs), a suite of highly efficient chips purpose-built for KWS using deep neural networks that increase the options for system designers.
Introduction to microcontrollers
Microcontrollers, sometimes known as an embedded controller, are present in applications with and without voice command, such as vehicles, robots, office machines, medical devices, vending machines, and home appliances. They were first developed by Intel in the early 1970s and are now produced by many other manufacturers, including Microchip (PIC microcontrollers), Atmel ( AVR microcontrollers), Hitachi, Phillips, Maxim, NXP, Intel, etc.
The need for low power consumption for keyword spotting systems makes microcontrollers a natural choice for deploying KWS in an always-on system. However, deployment of neural network-based KWS on microcontrollers comes with the challenges of limited memory footprint and limited computer resources.
Introduction to neural decision processors
The SyntiantR NDP100TM microwatt-power Neural Decision ProcessorTM is the first and currently the only commercial silicon device designed to put machine learning processing into almost any consumer device. The custom-built chips are specialized to run TensorFlow neural networks. TensorFlow is an open-source software library developed by Google and available for free for dataflow and differentiable programming across a range of tasks.
The Syntiant NDP is specifically designed for devices that use voice commands and have ultra-low power requirements making them well-suited to devices with KWS systems.
The Syntiant NDP100 and NDP101 chips have been certified by Amazon, which enables the company’s neural processors to be used in Alexa-enabled devices, however, Syntiant NDPs are not limited to Alexa devices only.

How do they compare and what do I need for my device?
System designers are faced with a growing number of high-quality options for adding a KWS algorithm to their devices. As previously described, a voice command interface often requires the device to be ‘always on’ and listening for its wake words, thus low power consumption is essential. However, it can be difficult to compare the power consumption of different devices from different manufacturers. Datasheets may describe current consumption in uA/MHz, but it is not generally possible to convert that into the power required for a given task. Additionally, different network topologies, training procedures, etc., can affect system accuracy and power consumption.
The critical question system designers must ask is how much power consumption will be added by a solution running a KWS algorithm with sufficient accuracy to satisfy the use case?
Syntiant White Paper
Two recent research projects have compared device options for KWS. The 2018, “Hello Edge,” paper [1] performed neural network architecture evaluation and exploration for running KWS on resource-constrained microcontrollers. In 2019, Syntiant tested their NDP10x series of Neural Decision Processors against a range of MCU’s suitable for KWS which they outlined in this whitepaper [2]. The rest of this article will be dedicated to examining the results of the Syntiant test, which provides a good overview of some of the leading options for adding KWS to edge devices.
The line-up
The test compared several of the lowest-power options for KWS available, including their own NDP10x, and compared speed, accuracy, and power on a common task: the Google keyword dataset assembled by Pete Warden of Google.
Included in the test were the STM32F746 Discovery board, the STM32L476G, and its evaluation board, as well as the Ambiq Apollo 3 Blue, using the SparkFun Edge Board, a joint effort by Google, Ambiq, and SparkFun, and the Syntiant’s NDP100 solution using their own internal development board.

The test
The researchers modified the code to run a batch of 20 inference cycles on each of the platforms. For the MCU targets, the input audio was taken from a pre-recorded waveform stored in memory to avoid contaminating the measurements with microphone power. The measured power includes computation of MFCC or filter-bank energy features, but not an ADC or microphone power. The NDP measurements include decimation of PDM output from a digital microphone, as well as feature extraction and the neural inference energy.
MCUs often have several on and off-chip peripherals powered from the same supply, so the Syntiant team subtracted a baseline current measurement made with the MCU powered up but idle. The NDP results are direct measurements with nothing subtracted. The MCU experiments were performed with HW settings as set in the available open-source software linked above.
The results
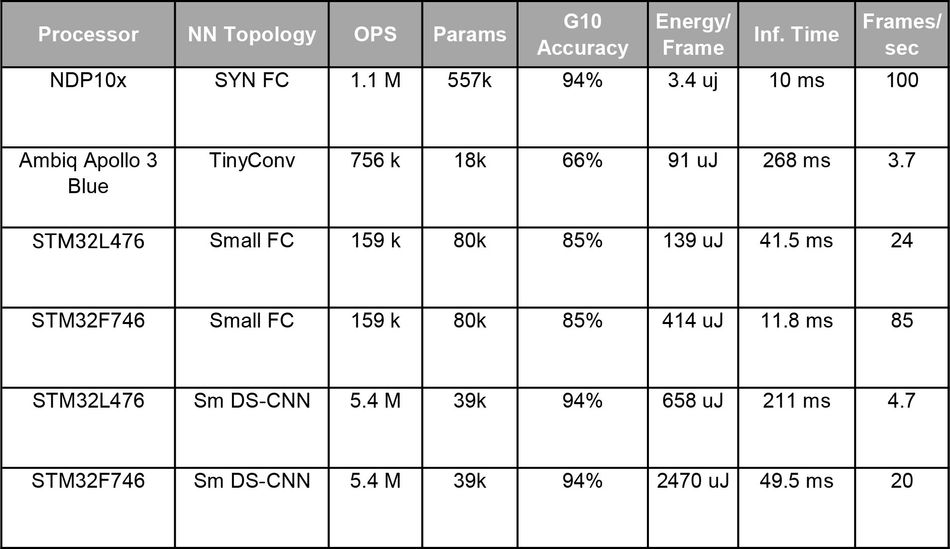
The table below summarizes the measurements. Simple ‘side by side’ comparisons are difficult due to the trade-offs between model complexity, accuracy, compute time, and energy. To make reading the results more clearly, the researchers compared across three axes:
- Energy per inference is the energy required to process one frame of audio samples and produce a label (e.g., “yes,” "no,” “hello”), including feature extraction and running inference.
- Inference time is the time required to process one frame of audio and frame rate is its inverse, indicating the maximum number of audio frames per second that the processor is capable of processing with a given network.
- G10 Accuracy is the accuracy result on the Google-10 keyword task.
Estimates for the operations and parameter counts for the Small FC and Small DS-CNN networks are taken from the “Hello Edge” paper. For the TinyConv network used on the Ambiq chip, those figures were estimated from the code in the “Speech Commands” TensorFlow example.
What does this mean?
It’s clear that the purpose-built compute path in the NDP100 provides dramatic energy savings relative to the stored-program architecture of an MCU solution. The closest result in energy, from the Ambiq Apollo 3 Blue, is 27x higher than the NDP energy, operating with a much smaller and less accurate network.
The STM32L4786 running the Small DS-CNN network had a comparable accuracy to the NDP but requires 193x the energy.
The frame rates are also critical to examine. Production KWS systems typically require at least 20 and often 100 fps in order to avoid “stepping over” a target utterance. The NDP also provides a speed advantage over low-power MCUs thanks to its parallelism and dedicated data path.
The Apollo's energy advantage comes with a speed penalty resulting in a maximum frame rate of 3.7fps, which will typically yield much lower real-world precision than the software accuracy of 66 percent (in TensorFlow on pre-aligned data) would predict.
Of the tested MCUs, only the STM32F746, from ST’s high-performance F7xx line, exceeds 20 fps, and it does so at an energy cost about 700x higher than the NDP, resulting in a power cost of about 50 mW (milliwatts), in addition to the baseline power required to power up the MCU initially.
Conclusion
This test clearly demonstrates that a purpose-built compute engine for neural inference can provide energy and speed advantages over stored-program architectures. The continued development of ultra-low-power MCU’s and highly efficient purpose-built chips will bring voice to the edge in a range of applications that have the potential to disrupt the way we interact with technology.
AI Voice Applications: Call for Projects
Are you developing devices that include a voice interface or another application of voice technology? We would love to hear from you!
Wevolver is looking to connect with exciting relevant projects to profile in an upcoming article about AI empowered voice applications. This is a great opportunity to get exposure among the engineering community!
Please leave your details via this short form. We will be in touch shortly.
About the sponsor: Syntiant
Voice at the edge
Semiconductor company Syntiant is pushing forward voice at the edge possibilities with the development of the Neural Decision Processors™ (NDP10x). These high power r devices offer highly accurate wake word, command word, and event detection in a tiny package with near-zero power consumption.
Currently, in production with Amazon’s Alexa Voice Service firmware, the NDP10x family makes Always-On Voice interfaces a reality by supporting entirely new form factors designed to wake up and respond to speech rather than touch. These processors will move voice interfaces from the cloud on to devices of all sizes and types, including ultra-portable wearables and devices.
References
1. Zhang, Y., Suda, N., Lai, L., & Chandra, V. Hello Edge: Keyword Spotting on Microcontrollers. ArXiv, abs/1711.07128. Feb 2018. Available from:https://arxiv.org/pdf/1711.07128.pdf
2. Holleman, J. The Speed and Power Advantage of a Purpose-Built Neural Compute Engine, June 2019. Available from: https://www.syntiant.com/post/keyword-spotting-power-comparison