TinyM2Net Multimodal Learning Framework for Resource-Constrained Edge Devices
A framework that uses both audio and image modality for event classification– tested on COVID-19 prescreening and battlefield object detection, later evaluated on the Raspberry Pi 4 single-board computer.

29 Mar, 2022. 4 minutes read

TinyM2Net is evaluated in battlefield object detection
Artificial intelligence and machine learning have been deployed on tiny resource-constrained edge devices for which the concern from model accuracy to model efficiency has taken place. To design and develop AI models that can operate efficiently on resource-constrained microcontrollers and microprocessor-based mobile devices and edge platforms, the researchers are employing multimodality to train machine learning models. In simple terms, modality refers to the way in which something is experienced, which can be natural languages, visual signals, and vocal signals [1]. This multimodal machine learning is aimed at building models that can process and relate information from multiple modalities, as seen in the early research on audio-visual speech recognition. We have witnessed the use of multi-modal machine learning in various fields from medical diagnosis, security, and combat fields to robotics, vision analytics, knowledge reasoning, and navigation.
Tiny edge devices are shipped with very limited resources in terms of memory and storage, with a typical SRAM of less than 512kB causing issues to deploy deep learning networks. The shift towards processing data closer to the source has made it important to develop efficient frameworks that not only increase power efficiency but also allow accuracy to be deployed on edge devices for faster processing of data. These issues add up to performing efficient multimodal learning inference with low peak memory consumption. To address the above challenges, a team of researchers affiliated with the University of Maryland at Baltimore, and the U.S. Army Research Laboratory have teamed up to present a flexible system algorithm designed with a multimodal learning framework for resource-constrained tiny edge devices [2].
Beyond hardware constraints
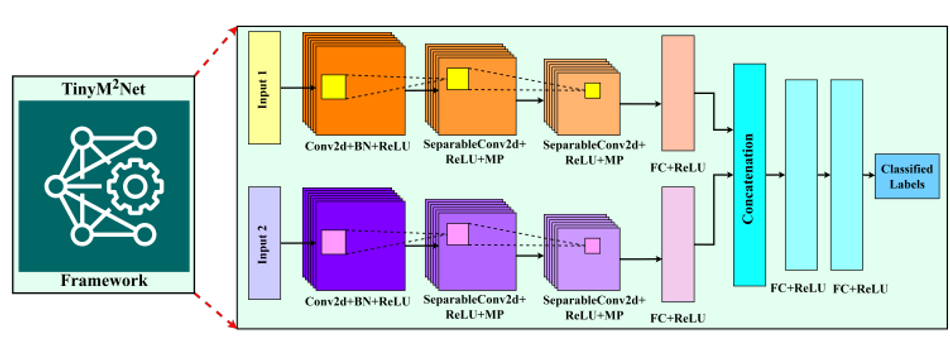
In the paper, “TinyM2Net: A Flexible System Algorithm Co-designed Multimodal Learning Framework for Tiny Devices” the researchers have recently developed a novel multimodal learning framework that can take multimodal inputs– images and audio and can be re-configured for specific application requirements. TinyM2Net also allows the system and algorithm to integrate new sensor data that is customized for several real-life scenarios. The proposed framework is based on a convolutional neural network, previously regarded as one of the promising techniques for audio and image data classification.
Traditional CNN models are bulky and are not optimized for tiny edge devices, but the TinyM2Net framework also takes care of model compression as one of the key aspects of the design. Various compression techniques were proposed to optimize the network architecture and memory requirements– one of which was Depthwise Separable CNN (DS-CNN) to reduce the computation from the traditional CNN layers. For memory requirement optimization, the framework adopts low precision and mixed-precision model quantization. However, it is important to note that the accuracy of the model significantly degrades if it is uniformly quantized to low-bit precision. To solve the problem with low-bit precision and accuracy degradation, the team chose two different bit precision settings, INT4 and INT8 for the TinyM2Net framework.
Evaluating performance
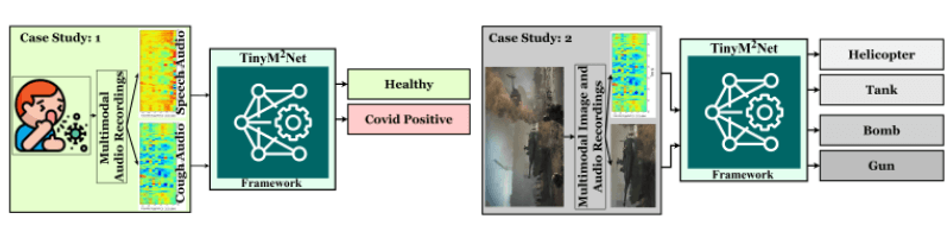
The team tested the TinyM2Net multimodal framework on two different scenarios– detecting COVID-19 signatures using two modalities of audio, cough sound and speech sound; and detecting battlefield objects using images and audio. In the first case study of COVID-19 detection, the goal was to provide COVID-19 pre-screening mobile or tiny devices using the dataset from COVID-10 cough sub-challenge (CCS) and COVID-19 speech sub-challenge (CSS) [3]. In the dataset, there are 929 cough audios from 397 participants and 893 speech recordings from 366 participants. The model achieved 90.4% classification accuracy with FP32 bit precision which was later tested on the proposed 8-bit and 4-bit precision to achieve 89.6% and 83.6% classification accuracy. “Our MP quantization technique improves the classification accuracy to 88.4%, and the best baseline accuracies for unimodal COVID-19 detection from cough audio and speech audio were 73.9% and 72.1%,” the team notes.
The second case study is for battlefield component detection that is based on image and audio modality. The team decided to add more data to the existing open-sourced dataset by adding to the list of contributions– creating a dataset for multiclass classification problems with four classes: Helicopter, Bomb, Gun, and Tank. The images were collected in .jpg format with a total of 2745 images for all four classes. In the audio samples, the sampling frequency was 2205050Hz for 1 second of audio later extracted in total 2745 MPCC spectrogram for four classes. “We achieved 98.5% classification accuracy with FP32 bit precision, and then later quantized the model to uniform 8-bit and 4-bit precision to achieve 97.9% and 88.7% classification accuracy,” the team mentions. “Our mixed-precision quantization technique improves the classification accuracy to 97.5% which is very comparable to both 8-bit and 32- bit quantized models to achieve 93.6% classification accuracy with unimodal implementation.”
The team also deployed the TinyM2Net framework on tiny devices– Raspberry Pi 4 with 2GB LPDDR4 memory. More details are available in the research work published on Cornell University’s research sharing platform, arXiv under open access terms.
References
[1] T. Baltrušaitis, C. Ahuja and L. Morency, "Multimodal Machine Learning: A Survey and Taxonomy," in IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 41, no. 2, pp. 423-443, 1 Feb. 2019, DOI: 10.1109/TPAMI.2018.2798607.
[2] Hasib-Al Rashid, Pretom Roy Ovi, Carl Busart, Aryya Gangopadhyay, Tinoosh Mohsenin: TinyM2Net: A Flexible System Algorithm Co-designed Multimodal Learning Framework for Tiny Devices. DOI arXiv: 2202.04303 [cs.LG].
[3] Björn W. Schuller, Anton Batliner, Christian Bergler, Cecilia Mascolo, et. al.: The INTERSPEECH 2021 Computational Paralinguistics Challenge: COVID-19 Cough, COVID-19 Speech, Escalation & Primates. DOI arXiv: 2102.13468 [eess.AS].