Research suggests improvements in visual speech recognition on a multilingual dataset
A novel approach to visual speech recognition that carefully designs the VSR model rather than increasing the size of the training data.

15 Mar, 2022. 4 minutes read
![Visual Speech Recognition on a Multilingual Dataset that outperforms the state-of-the-art methods [Image Source: Research Paper]](https://image.wevolver.com/eyJidWNrZXQiOiJ3ZXZvbHZlci1wcm9qZWN0LWltYWdlcyIsImtleSI6IjAudjQ4cWlqcTczeWtWaXN1YWxTcGVlY2hSZWNvZ25pdGlvbmludGhlV2lsZC5wbmciLCJlZGl0cyI6eyJyZXNpemUiOnsid2lkdGgiOjgwMCwiaGVpZ2h0Ijo0NTAsImZpdCI6ImNvdmVyIn0sIndlYnAiOnsicXVhbGl0eSI6ODV9fX0=)
Visual Speech Recognition on a Multilingual Dataset that outperforms the state-of-the-art methods [Image Source: Research Paper]
The advancements in computer vision, pattern recognition and signal processing have made visual speech recognition possible for a variety of applications, such as human-computer interaction, speaker recognition, talking heads, sign language recognition and video surveillance. Visual speech recognition deals with several technological breakthroughs, like image processing, artificial intelligence, object detection, and statistical modeling only uses visual signals of the lip movement that produce speech without relying on the audio [1]. In the first generation of VSR, the research could not meet the high accuracy demands of the industry due to factors concerning the size of the audio-visual dataset with limited vocabulary and hand-crafted visual features that are not optimal for VSR model training.
The introduction of deep learning and neural networks has made visual speech recognition models more robust than ever before while achieving higher accuracy in unstructured real-life situations. Most recent innovations allow the models to perform much better due to the availability of larger datasets and training models with a huge amount of data. A group of researchers affiliated with the Department of Computing at Imperial College London and Meta AI proposed a novel approach to add prediction-based auxiliary tasks to the VSR model and outperform state-of-the-art methods trained on the publicly available data [2].
Looking to Listen
In the research paper, “Visual Speech Recognition for Multiple Languages in the Wild,” the team carried out work with the aim to reduce the word error rate (WER) through appropriate data augmentation and hyperparameter optimization of the existing architecture while working on the publicly available datasets that are much smaller in size. Through this, the team points out the fact that the optimization of the models can be brought in through carefully designing the models and not only increasing the size of the training data. Also, the proposed novel method for visual speech recognition not only evaluates English as a sole language but also on Mandarin, Spanish, Italian, French and Portuguese and achieves state-of-the-art performance on all the languages.
“We optimize hyperparameters and improve the language model with the aim of squeezing extra performance out of the model,” the team explains. Then, “we introduce time-masking which is a temporal augmentation method and is commonly used in ASR models. Finally, we use a VSR model with auxiliary tasks where the model jointly performs visual speech recognition and prediction of audio and visual representations extracted from pre-trained VSR and ASR models.”
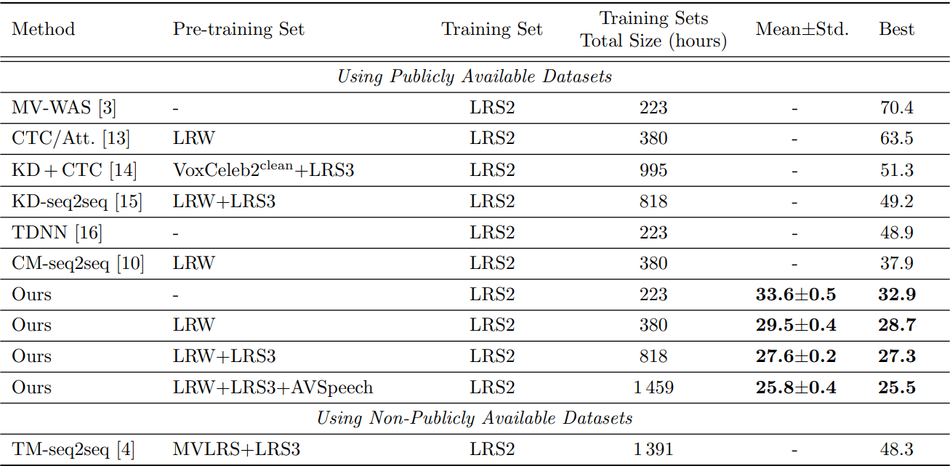
Hyperparameter optimization aims to improve the performance of the model by adjusting the values of the parameters that are employed to control the training process and the model architecture. There are several hyperparameters taken into consideration including initial learning rate, learning rate decay parameter, number of layers, size of layers, dropout rate, and the loss function that was performed on the LRS2 dataset achieving reduction in WER on the validation set. The main hyperparameter that had a significant impact on the performance and which might not have been exhaustively optimized was the batch size. The team observed that reduction WER was achieved more when the batch size increased from 8 to 16. Due to GPU memory constraints, the team recognized that certain hyperparameters could not be increased further, but they would bring down the word error rate.
State-of-the-art performance
The team decided to use all the open-source datasets available for public use, namely LRS2 (an audio-visual English dataset from BBC programs), LRS3 (an audio-visual English dataset taken from TED and TEDx talks), CMLR (a Mandarin dataset collected from Chinese news program), CMU-MOSEAS (contains multiple languages from YouTube videos), Multilingual TEDx (multilingual corpus taken from TEDx talks), and AVSpeech (dataset with over 4700 hours of video in multiple languages). To measure performance, the word error rate is a common performance metric in speech recognition, with an alternative of a character error rate that measures how close the predicted and target character sequences are.
For the multilingual TEDxSpanish dataset, the approach results in a 5.6% absolute reduction in the WER and a further reduction of 4.2% can be achieved by using additional training data. While for the Italian corpus, the approach results in an absolute drop of 5.6% in the WER, the same as that for Spanish, but a further reduction of up to 8% for additional training data. “Results on the Multilingual TEDxFrench dataset are shown as a result of a 9.4 % absolute reduction in the WER and a further reduction of 7.6 % can be achieved by using additional training data.” [More details on the additional training data are available in the research article]
The proposed novel method for visual speech recognition performs visual speech recognition and prediction of audio and visual representation on a publicly available dataset to outperform state-of-the-art methods. The research work was published on Cornell University’s research sharing platform, arXiv under open access terms. The researchers have provided pre-trained networks and testing code on the authors’ GitHub repository for community access.
References
[1] Ahmad B. A. Hassanat: Visual Speech Recognition. DOI arXiv: 1409.1411 [cs.CV].
[2] Pingchuan Ma, Stavros Petridis, Maja Pantic: Visual Speech Recognition for Multiple Languages in the Wild. DOI arXiv: 2202.13084 [cs.CV].