Neural Network Architectures at the Edge: Modelling for Energy Efficiency and Machine Learning Performance
A short guide to understanding the edge neural network design.

21 Sep, 2022. 12 minutes read

This article is based on two blogs by Rouzbeh Shirvani and Sean McGregor, with additions and editing by John Soldatos.
For over a decade, industrial organizations have been executing data intense and compute intense applications within cloud computing infrastructures. This is currently the core use for many Machine Learning (ML) and other Artificial Intelligence (AI) applications, which process big data and use models (set of optimized, parametrized equations that map inputs to outputs) that require heavy computational resources. There are several advantages to deploying ML applications in the cloud, which stem from the scalability, elasticity, and capacity of cloud computing. For instance, the cloud makes it easy for ML systems integrators to access the resources needed for storing and processing many data points.
However, cloud-based deployments have certain shortcomings as well. In particular, the latency caused by sending data to the cloud for processing and waiting for the results to be transmitted back can be prohibitively long for real-time applications that need to make split second decisions (e.g., autonomous vehicles, industrial robots, security applications). Moreover, cloud-based ML systems are usually associated with a considerable CO2 footprint given the need to transfer large amounts of data to the cloud and to perform numerous Input/Output (I/O) operations over various data sources.
Furthermore, reliance on cloud systems can increase cybersecurity and data protection risks, especially in cases where sensitive data are sent over the internet. Therefore, cloud-based deployments are unsuitable in certain industries that deal with private data (e.g., healthcare).
These limitations have led to the adoption of edge AI. Instead of executing ML models in the cloud, edge AI systems process data and run deep learning within edge devices such as Internet of Things (IoT) systems and embedded devices [1]. Edge AI is deployed close to the field, which makes it suitable for real-time applications. Furthermore, ML inferences at the edge offer stronger data protection, along with a much lower carbon footprint and energy cost, as edge AI applications are usually designed for low-power operation.
However, the design and development of edge AI systems are much more challenging when compared to the development of conventional cloud-based ML systems. Cloud-based systems have virtually unlimited power, space, and computational horsepower. On the other hand, edge devices are often limited in terms of the size and energy consumption that they can support. Therefore, there is a need to design high-performance and power-efficient neural network architectures, which can run on devices with limited computational power. Conventional data science methods for designing ML models and data processing pipelines are not sufficient for developing neural architectures on embedded systems.
Rather new multi-disciplinary approaches combining ML expertise with embedded systems engineering knowledge are required. Unfortunately, most ML engineers lack the knowledge and skills needed to produce highly optimized ML models over cloud/edge architectures of embedded devices.
Power Efficient Edge Devices: Basic Concepts
The advent of edge AI has given rise to the development of various tools and techniques for model training and evaluation. However, most of these tools prioritize the optimization of the model’s capacity and performance rather than the model’s energy consumption. This is a limiting factor for the development and deployment of effective edge AI solutions in areas where energy efficiency is a critical concern.
In practice, most system designs are developed based on the collaboration of machine learning experts and embedded engineers. The former thinks in terms of ML model optimization, while the latter considers the carbon footprint of edge devices. However, the cultural gap between these two groups does not always facilitate the development of an effective edge AI solution. In this context, ML modelers must gain a better understanding of the embedded systems design challenges.
As a first step, ML modelers must acquaint themselves with the concepts of energy and power: Energy is a measure of the capacity to perform a task (i.e., do "work"), while power is the rate at which energy is used over time. The following energy and power metrics are commonly used:
- The energy per inference as a metric for the operation of a network, and
- The inference per second as a means for obtaining the average power consumed over time.
To better understand these metrics, consider a 60-watt (W) lightbulb. One second is 60 joules of energy for the lightbulb i.e., 60W of power on average. Assuming that the light bulb is turned off for half the day, the average power over a 24-hour period would only be 30W. The energy per second can be calculated using the following simple equation:
Power (watts) = Energy (joules) / Time (seconds) |
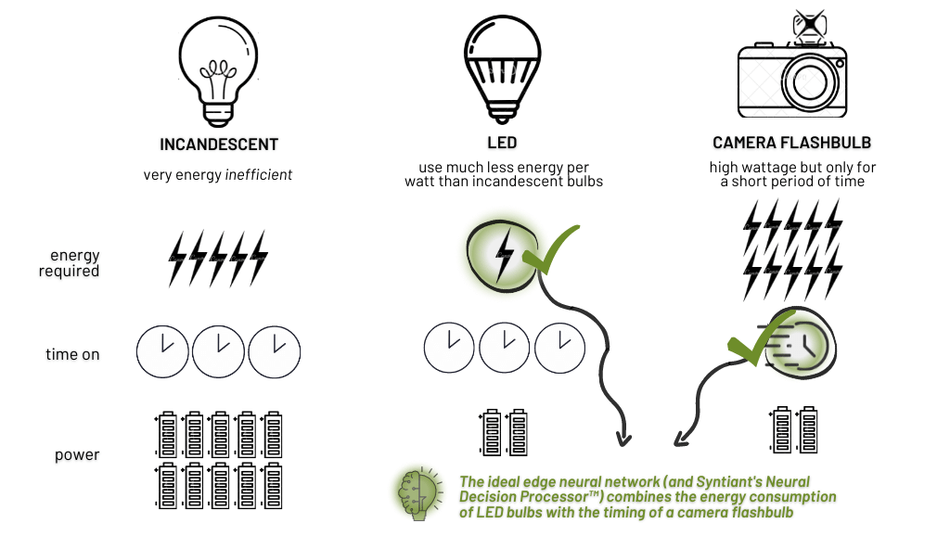
Recent lightbulb-related innovations have resulted in the wide availability of the popular LED (Light Emitting Diode) lights, which provide the same amount of light as a 60W incandescent bulb with only 6W of average power. Therefore, for the same amount of energy, LED lights provide lighting for 10 times longer than legacy lightbulbs. Alternatively, one can deploy 10 light bulbs based on the same energy consumption.
Battery powered devices provide another dimension, there is a limited amount of total energy that can be stored in a battery, and the total operating time is governed by the rate at which it is consumed. Battery capacity is typically reported at mW-hours (mWH), or sometimes in milliamp-hours (mAH) to specify how long the battery can continue to sustain an average power number. Going back to the light bulb, consider a light that could discharge 4 joules of energy over a 1 millisecond period, which is 4000W of peak power, but if you only do this 4 times a day, it is averaging 0.18W (or 180 mW) of power over the day.

Benchmarking Edge Neural Networks
An ideal neural network deployment at the edge would combine the energy efficiency of LED bulb with the timing of a camera flashbulb. This combination enables the implementation of the following strategy for power efficiency:
- Use less energy for inference tasks and
- Run inferences only when needed.
To properly implement this strategy, one must take a holistic approach to energy benchmarking, which goes beyond the quantification of peak performance i.e., operations/watt (OPs/W). This is because many solutions that claim high OPs/W cannot sustain that performance over the entire duration of full networks.
State of the art benchmarks (e.g., TinyML Perf benchmark) and related architectures (e.g., the Google-specified MobileNetV1) provide a sound basis for executing holistic benchmarking processes [3]. To use these benchmarks as part of the neural network development process, ML experts and system engineers must understand their key parameters such as:
- Supply voltage and Clock Speed: This parameter is indicative of the voltage used to achieve a certain speed for the solution. Higher voltages increase the speed of computation, yet they also result in an increase of the solution power that is proportional to the square of the voltage. Therefore, designers must strive to provide the speed needed for the computations of the neural network without necessarily increasing the supply voltage. This is one of the most important trade-offs of the solution design, which drives the selection of the chip of the solution. Likewise, when reviewing the performance benchmarks of the solution is it essential to present performance numbers at a consistent voltage and clock combination.
- Inference energy and Inference Power at Maximum Inferences Per Second: The combination of these two measures unveils a lot about the numbers the silicon vendor is presenting. Ideally the inference power at maximum inferences per second should be the outcome of the following product: Maximum Inferences Per Second ◊ Inference energy. This is because the chip should only run when it is needed i.e., designers must strive to minimize the total number of inferences. It’s worth noting that that, when the system runs very infrequently, the static power starts becoming a more important contributing factor to the total energy than the Inference Power.
- Static Power: This parameter indicates the fixed power consumption of the semiconductor device i.e., the power cost needed to keep the chip powered and clocking. It indicates the solution’s power requirements on top of the inference cost and is very important for understanding the power impact of frame rate changes. Designers can take advantage of the inference energy and Static Power parameters to estimate the solution power cost for different frame rates. Specifically, such calculations can leverage the following formula: Solution Power = Static Power + Frame Rate ◊ Inference Energy to evaluate different solution designs. The good news is that other parameters such as the sensor power cost and memory transfer cost do not typically change when different neural architectures are considered. Hence, the above-listed formula is generally sufficient for framerate-related calculations.
- Task Performance Change: This part of the benchmark illustrates the impact of execution parameters changes on the execution of the neural network architecture, such as changes on the numerical precision of activations. Without a figure for the task performance change, silicon providers will run the chip at its minimum resolution, which is not the mode at which the neural network will be run when deployed in a practical use case.
- Maximum Inferences Per Second: As already outlined, this parameter illustrates how often you can run the network. Real-time application throughput is related to task performance and depends on the number of inferences actually executed.
Design Patterns for Edge Neural Accelerators: Balancing ML Performance and Power Cost
The presented performance metrics enable modelers to compare alternative neural network architectures in terms of model performance and power optimization. They also enable the benchmarking of the task performance different edge neural networks for certain use cases. From an ML engineering perspective, they enhance conventional performance metrics (e.g., precision and recall) with measures of inference energy.
This makes ML model development and optimization extremely challenging, as modelers must balance many different trade-offs. Specifically, they must achieve a good performance in detecting relevant events and identifying them correctly, while ensuring optimal power efficiency. In this direction, modelers must employ heuristics and design principles [4] that help ensuring the best possible compromise between precision, recall, and energy consumption.
To understand the modelling challenges and ways to resolve them, let’s consider a person detection computer vision task and two alternative neural architecture options for implementing it, namely:
- Option A: Using a big network 1 time per second.
- Option B: Using a ten times (10x) smaller version of the network but 10 times per second.
Based on the earlier-presented device energy metrics both options lead to more or less the same average power consumption. Thus, it is best to use the option that yields the best precision and recall.
Option A leverages a neural network with more layers and hence provides better classification performance than Option B. On the other hand, Option B processes events ten times more frequently with shorter latencies, which lets it detect events much more accurately than Option A. Therefore, a neural network architecture that works in practice should combine the two options. It should run frequently a small model (as per Option B) and run conditionally the large model (as per Option A) whenever a relevant event is detected. This is a heuristic pattern for ensuring very good precision and recall at the same time.
This pattern is also popular in energy-efficient system design, where a best practice is to “execute only what you need to and only at times when you need to do so”. Indeed, it turns out that the combination of the two systems yields an energy-efficient network architecture. In particular:
- Assuming that the Option B network detects relevant events at a reasonable frequency, most of the energy is spent by an energy-efficient network.
- The more complex, high energy Option A network is selectively activated to classify the detected events with high accuracy.
A more realistic configuration for the person detection application can be derived by connecting and pipelining three different architectures in a cloud/edge configuration. Specifically:
- The small model is a relatively small Convolutional Neural Network (CNN) calibrated to high recall.
- The medium model is a quarter-scale MobileNetV1 architecture as configured by Google.
- The largest model comprises more layers and is deployed and executed on the cloud.
In this architecture, the small model runs more than 9 times more often than it is configured to run for person detection. However, whenever the small model believes the target class is present, it switches to the "medium model" until it either hands off to the cloud model or returns back to the small model. In this way, the impact of the medium model on the power performance is relatively low, as the model runs conditionally at selected times where relevant events are detected.
Of course, there are cases where the designer might choose to configure this cascading architecture differently. For example, when many events are present, it makes sense to run the larger model first in order to achieve high classification accuracy at a reasonably low additional power cost. As the number of positive instances per hour increases the power performance of the cascading architecture drops, which leads the designer to consider running the larger model first and abandon the cascade. Overall, in cases of rare event detection, the medium model has a minimal cost and could be as large as is supported by the hardware. However, in the case of frequent events i.e., after the medium model has higher solution power than the small model, it is good to look at increasing the solution power of the small model.
The above-listed examples illustrate the challenging nature of the tradeoffs involved in the design of cloud/edge neural network architectures. These tradeoffs entail complex choices that should balance solution power, memory, latency, and user experience. As a first step, designers must develop a cascading design that meets their base requirements. Accordingly, they must strive to iteratively optimizing the design through fine-tuning the cascading configuration and its parameters.
In this direction, they should consider different values for the parameters that affect the ML performance and the total power cost of the cascading configuration. For example, they should consider sampling combinations of frame rates, stage confirmation requirements, and model precision/recall calibrations. The alternative configurations must be confronted against the requirements of the use case and should be benchmarked and compared against each other. In this way, ML modelers and neural network architecture designers will arrive to optimal duty cycles for their edge neural accelerator solution.
About the sponsor: Syntiant
Syntiant provides world class neural accelerator solutions for cloud/edge configurations such as its NDP120 Neural Decision Processor™. The solution exhibited exceptional performance and outstanding results in the latest MLPerf benchmarking round. In fact, it was the sole solution that come with a neural processor, which makes it an excellent choice for supporting high-performance edge AI solutions for a variety of use cases in different sectors. ML system integrators can therefore integrate and use NDP to bootstrap their developments in ways that safeguard the energy efficiency and performance of their cloud/edge solutions.
Syntiant Corp. is a leader in delivering end-to-end deep learning solutions for always-on applications by combining purpose-built silicon with an edge-optimized data platform and training pipeline. The company’s advanced chip solutions merge deep learning with semiconductor design to produce ultra-low-power, high-performance, deep neural network processors for edge AI applications across a wide range of consumer and industrial use cases, from earbuds to automobiles. Syntiant’s Neural Decision Processors™ typically offer more than 100x efficiency improvement, while providing a greater than 10x increase in throughput over current low-power MCU-based solutions, and subsequently, enabling larger networks at significantly lower power.

References
1. F. Wang, M. Zhang, X. Wang, X. Ma and J. Liu, "Deep Learning for Edge Computing Applications: A State-of-the-Art Survey," in IEEE Access, vol. 8, pp. 58322-58336, 2020, doi: 10.1109/ACCESS.2020.2982411.
2. M. Shafique, T. Theocharides, V. J. Reddy and B. Murmann, "TinyML: Current Progress, Research Challenges, and Future Roadmap," 2021 58th ACM/IEEE Design Automation Conference (DAC), 2021, pp. 1303-1306, doi: 10.1109/DAC18074.2021.9586232.
3. D. Pau, M. Lattuada, F. Loro, A. De Vita and G. Domenico Licciardo, "Comparing Industry Frameworks with Deeply Quantized Neural Networks on Microcontrollers," 2021 IEEE International Conference on Consumer Electronics (ICCE), 2021, pp. 1-6, doi: 10.1109/ICCE50685.2021.9427638.
4. A. Pahlevan, X. Qu, M. Zapater and D. Atienza, "Integrating Heuristic and Machine-Learning Methods for Efficient Virtual Machine Allocation in Data Centers," in IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 37, no. 8, pp. 1667-1680, Aug. 2018, doi: 10.1109/TCAD.2017.2760517.