Meta AI Introduces Data2vec Open-Source Framework for Self-Supervised Learning in NLP, Speech and Vision Processing
A holistic open-source framework to improve the performance of multiple modalities and outperform the existing single-modality algorithms.

28 Jan, 2022. 4 minutes read

Meta AI's Data2vec Open-Source Framework
The recent breakthroughs in AI research came due to the growing demand for improved architecture, offering high performance and less complexity. Self-supervised learning has been the key to several AI challenges in speech, NLP and computer vision data-intensive workloads. These challenges refer to the changing environment and different input parameters requiring the AI model to learn by directly observing the surroundings. However, to keep up with the technological advancements, self-supervised learning differs at various levels of the algorithm when applied for a single modality. Even though the idea behind the implementation remains the same, there are performance issues when using the same algorithm across.
To make it easy for the researchers and AI developers, Meta AI, previously known as Facebook AI, has introduced a novel methodology, data2vec, through a generalized framework of self-supervised learning for speech, vision and language processing. Rather than predicting modality-specific features such as words, tokens or units in speech processing, the proposed idea of the generalized framework is to predict the latent representation of the input data. Continuing, Meta AI’s data2vec claims to be the first high-performance, self-supervised AI algorithm that works efficiently and effectively across multiple modalities.
Executing the data2vec general framework separately on different modalities like speech, image and text, the new method outperformed the existing single-purpose algorithms. This shows holistic self-supervised learning that improves the performance of multiple modalities rather than a single task by not relying on contrastive learning. The Meta AI’s data2vec has brought machines closer to actual self-learning by analyzing different aspects in the surrounding. The adaptability of AI algorithms is the future for several real-life applications with exceptional results like never before.
“In an effort to get closer to machines that learn in more general ways about the environment, we designed data2vec, a framework for general self-supervised learning that works for images, speech and text where the learning objective is identical in each modality,” researchers explain. “We hope that a single algorithm will make future multi-modal learning simpler, more effective and lead to models that understand the world better through multiple modalities.”
Inside the Meta AI’s Data2vec Framework
The current research focused more on improving the performance for a single modality which changed the approach towards building a robust framework for other modalities. In data2vec, the training models are made to predict the input data through its own representation irrespective of the modality. Instead of predicting a specific set of features, a single algorithm can work with different types of inputs, like speech, vision, and text.
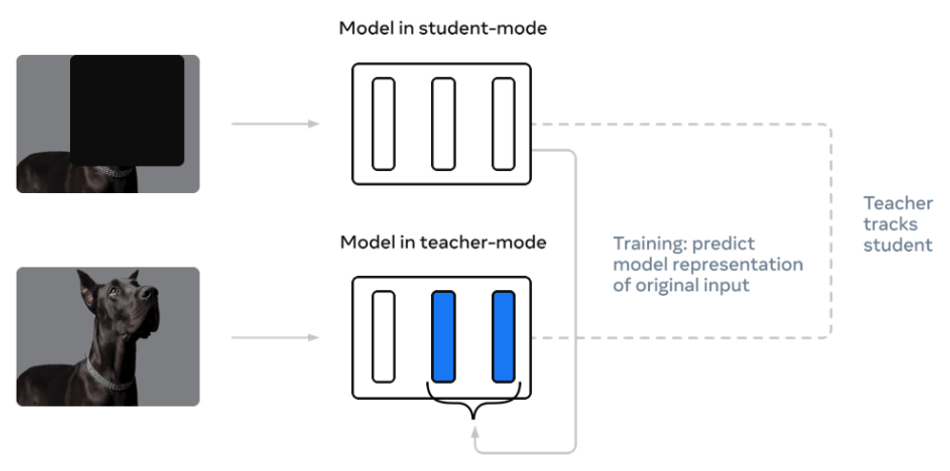
The proposed model of teacher and student network makes it easy to understand such algorithm training. Primarily, the teacher network goes through the computation for target representation of image, text or speech. Once this is performed, the same input is masked and the process is repeated in the student network. The latter predicts the latent representation of the teacher network. Even though the input data is not clearly visible to the training model, the student network has to predict the representation of the full input data. The weights of the teacher network are the exponentially decaying average of the student. With different modalities in the picture, the framework uses modality-specific feature encoders and masking strategies.
The framework uses the standard transformer architecture that comes with the modality-specific encoding of the input data. Researchers decided to use ViT-strategy for computer vision, a multi-layer 1-D convolutional neural network for speech data, and text input is pre-processed to obtain sub-word units.
Did Data2vec Framework Outperform Existing Methods?
These are the results and the experimental setup employed in the new generalized framework for self-supervised machine learning in speech, vision and text processing.
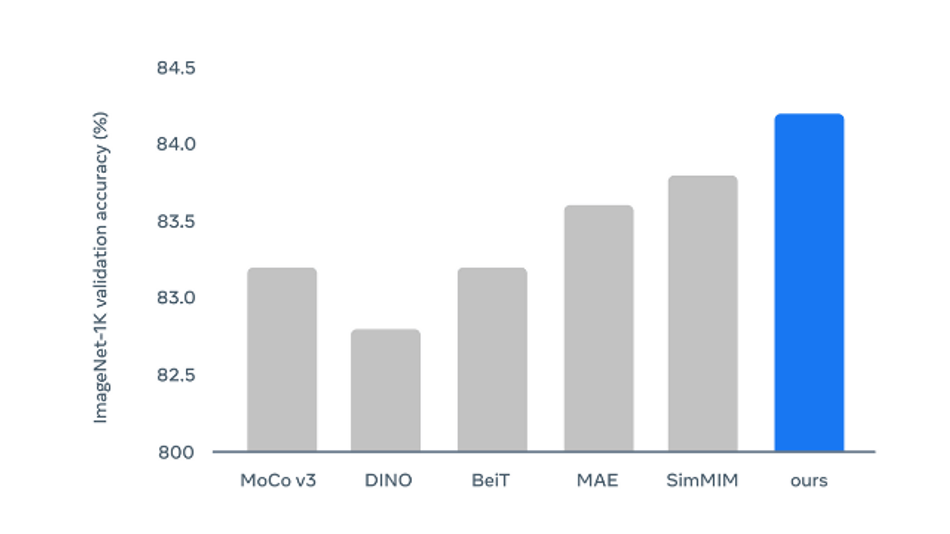
- For computer vision: The framework was pre-trained on the images of the ImageNet-1K training set. The Data2vec performance for computer vision on the popular ImageNet benchmark for ViT-B models compared with other recent methods seems to significantly outperform with an accuracy improvement of 1.5% over DINO.
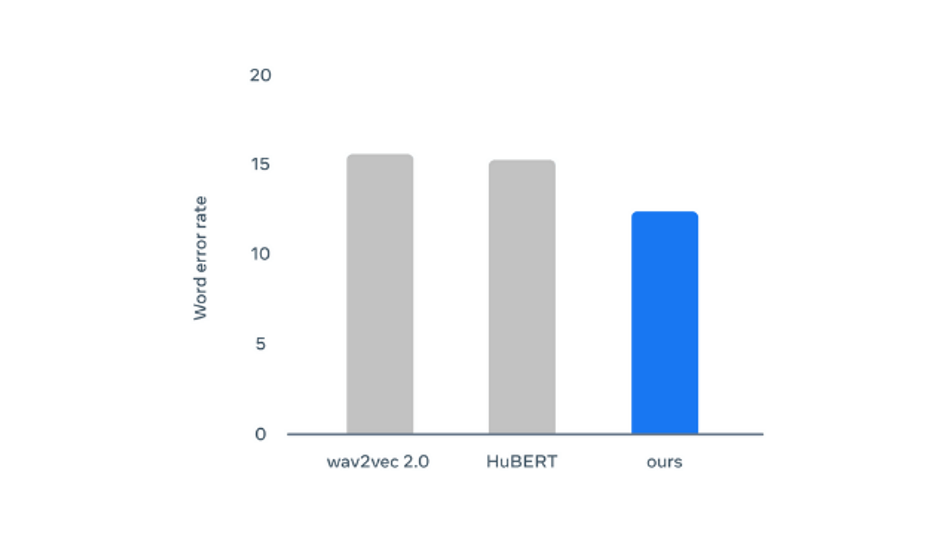
- For speech processing: For the evaluation, the speech processing was done through pre-training of Data2vec on 960 hours of speech audio input data from LS-960. Due to its clean speech audio and standard used in the industry, the results are easier to compare. The performance of the base model on the LibriSpeech benchmark with 10 hours of labeled data compared with other methods seems to show improved performance as the WER goes down.
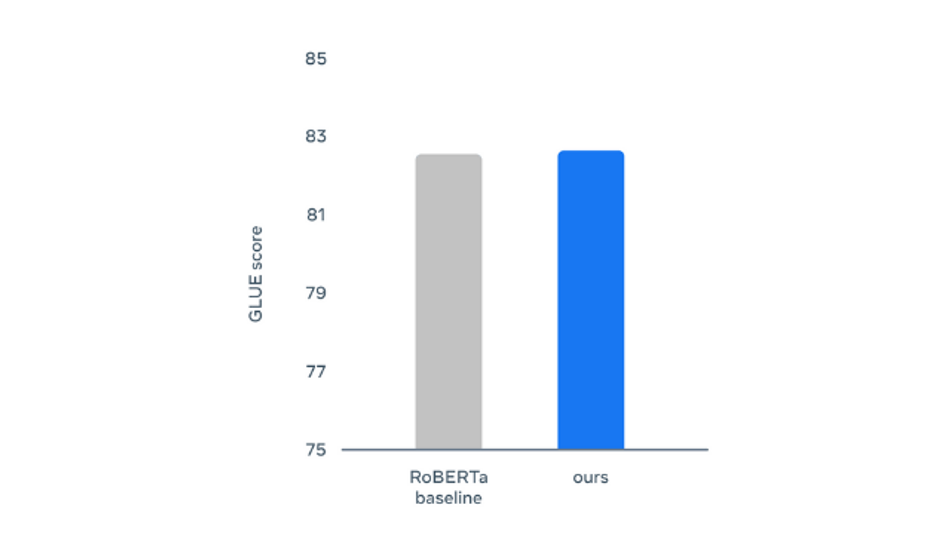
- For NLP: For language processing, General Language Understanding Evaluation (GLUE) benchmark has been used that includes tasks for natural language inference, sentence similarity, grammaticality, and sentiment analysis. The performance for the base model has once again outperformed (but with a slight margin) the RoBERTa baseline when retrained with the original BERT setting.
Summary of Data2vec Framework for Self-Supervised Learning
Summarizing the innovation brought in through the generalized framework for Self-Supervised learning for speech, vision and language processing:
- Uniform model architecture for multiple modalities without reducing the performance.
- Data2vec framework outperforms existing self-supervised algorithms on ImageNet-1K for ViT-B and ViT-L models.
- Improvement on speech recognition for low-resource setup of Libri-light and NLP’s competitive performance against RoBERTa on GLUE.
For more details on the methodology of the research, check out the open-sourced research paper.