How to reduce power consumption in MPUs while running ML models
ML at the edge is the main target in many IoT applications today. Learn why it is important to build energy-efficient embedded devices, and how to achieve it using cutting-edge technologies.

08 Nov, 2022. 8 minutes read

In this article, we will see why it is important to have high energy efficiency in embedded ML systems and demonstrate how to achieve it using the Renesas RZ technologies.
The landscape of ML solutions in embedded systems
Years ago, when you wanted to apply machine learning (ML) to data, you had just one option available: the cloud. Nowadays, however, you can implement a wide variety of ML models in embedded systems. Applications include:
- Video surveillance: human detection, face detection, face recognition, license plate recognition, people counting, car counting, etc.
- Industrial: thermal image analysis, noise detection, vibration analysis, movement detection, etc.
- Health: patient monitoring, symptoms analysis, arrhythmia detection, etc.
- Farming: fruit counting, plague detection, crop health analysis, etc.
- Building management: spaces occupancy, human detection, parking occupancy, human identification, etc.
As you can see, there is a broad range of uses for ML in embedded systems.
Of the solutions listed above, the ones involving image and video processing are the most energy-consuming. Reducing the energy use of these devices can allow applying video analytics even in very constrained situations, like solar-panel/battery-fed cameras. On the other hand, video analytics are used not just in video surveillance systems, but also as an important part of more complex systems. Think about robots that need to move around avoiding obstacles. These robots depend on batteries, and the running of ML models can have a great impact on their operating life. Other examples are drones equipped with different types of cameras, including thermal and day/night vision. In this case, the lasting of the batteries determines the time of flight of the device.
Why is it necessary to keep power consumption low
The execution of ML models can consume a considerable amount of energy for an embedded system. This happens because the running of the model is CPU and memory intensive. However, keeping the power consumption at low levels is important, consider the following factors:
- Some IoT devices are fed using PoE (Power over Ethernet). So, there are fixed boundaries of deliverable power, according to the standard used. An IP camera with embedded analysis is a typical example of this.
- Other IoT devices could be powered using batteries or energy harvesting systems. Devices deployed in areas where there is no electrical infrastructure lay in this category. Also, it could be the case where connecting the device to the mains is difficult or impractical. In any of these cases, keeping the energy consumption low is critical.
- On the other hand, the power used by electronics produces heat. This heat can considerably increase the board's temperature; consequently, a heating extraction system should be implemented. The use of heating sinks can be impractical because of constrained space. Even worse, if heating sinks are not enough, a cooler should be used to force airflow. This, indeed, will require even more power.
Now that we have explored the reasons to implement an energy-efficient device, let’s see how you can achieve it.
Technological resources for achieving energy efficiency in embedded systems
There are two major approaches to reducing power consumption in embedded systems: hardware-related, and software-related. An efficient device will combine both strategies.
This is the case with cutting-edge microprocessors and microcontrollers.
There is a wide range of ML applications and each of them requires a different amount of processing power and memory resources. The following figure shows the type of ML applications that you can run across each family of microcontrollers from Renesas.
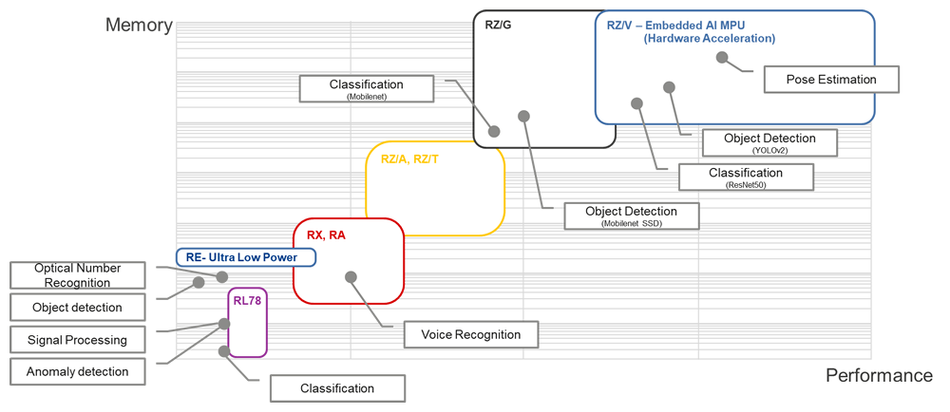
As you can see, you can deploy simple anomaly detection models to advanced video analytics. Signal processing, anomaly detection, character recognition, simple classifications, or even simple object detection require low processing power. Voice recognition is a harder task and you will have to choose at least the RX, RA, or RZ/A-T family. Then, for complex scenarios where you want to apply classification or object detection, you will have to select the RZ/G family.
Before seeing the solution for embedded video analysis developed by Renesas, let’s refresh the general procedure of implementing ML in embedded systems.
The development process of embedded ML
The pipeline of ML for embedded systems is as follows:
- Gathering data: This is normally done with sensors that acquire the data of interest. This data can be video, images, audio, or signals.
- Cleaning, filtering, and formatting: This stage involves noise filtering and removal of wrong values - for instance, defecting sensors. Also, the data must be formatted to be able to ingest it in the ML algorithm.
- Feature engineering: This process consists of selecting the best features from the data to build the ML model.
- Model training: In this stage, the model is built using a selected algorithm and the extracted features from the previous step.
- Model evaluation: the ML model is exposed to new data and the performance is evaluated.
- Steps 2 to 5 iterate until the model reaches the desired performance, according to selected outcomes. All this process is executed on a PC, a server, or a cloud because it requires a certain amount of computational power.
- The last step consists of converting the model to a format deployable to embedded devices.
The Renesas solution for video analytics at the edge
In this article, we focus on the RZ/V family and their capabilities to reduce power consumption for intense ML uses, like image and video processing and analytics. Let’s see how Renesas addresses this problem.
Renesas trains the ML models in the cloud or on your infrastructure and then deploys them to the embedded devices.
This approach allows that the devices don’t need to connect to the cloud for running the inference. This removes the delays involved with cloud communications and allows the model to run in a very fast and efficient way.
An interaction between a device and the cloud could take as long as one second, while running the inference locally only takes a few milliseconds. This is a great improvement in time and use of energy.
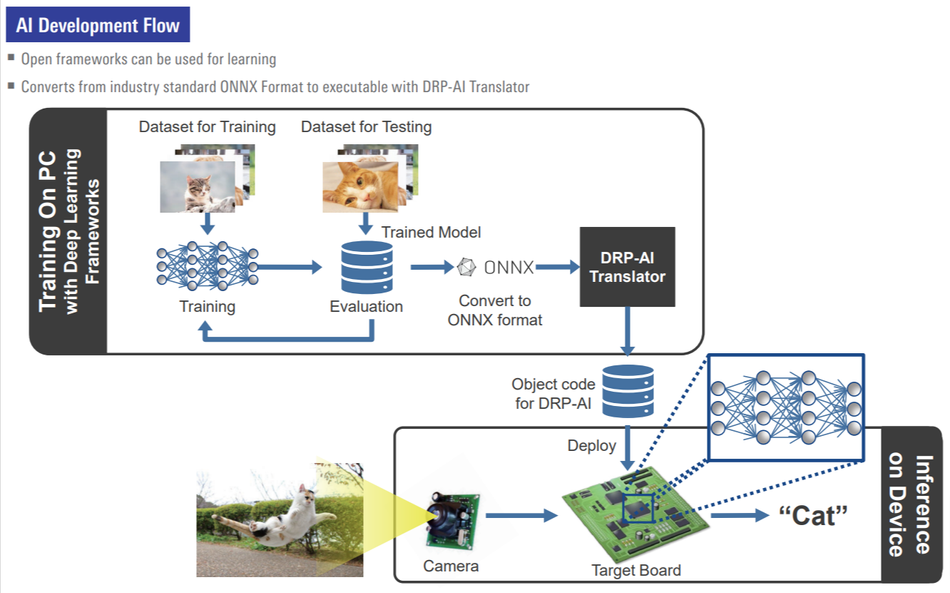
You can build your models using any of the common ML frameworks, like “PyTorch”, “Keras”, “Tensorflow”, or the 8-bit quantized model of “TensorFlow Lite”. Then you can convert it to the supported format by the hardware, as you can see in the following figure.
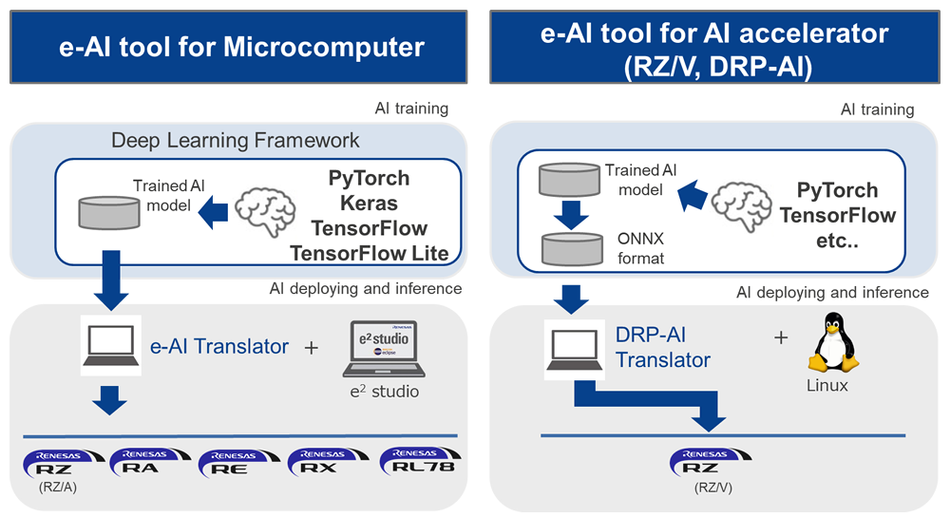
The step of deploying the models to the MPUs involves the use of the e-AI translator or the DRP-AI translator from Renesas, depending on the family of products that you are using. These translators perform very efficient programming of the devices, drastically reducing the energy consumption.
In particular, the e-AI translator lets you implement the model across many MCUs. On the other hand, the Dynamically Reconfigurable Processor for AI (DRP-AI) translator allows you to convert ONNX models by using the AI accelerator "DRP-AI" provided in RZ/V devices.
Typical applications for RZ/V with embedded AI are:
- IP camera
- Surveillance camera
- Retail
- Logistics
- Image inspection
- Robots
RZ/V uses the DRP-AI to accelerate the inference and save energy in the process. To reduce the power consumption on AI operations, RZ/V microprocessors apply the following techniques.
Reduction of external memory access
Besides the power consumed by matrix operations in the accelerator, the transactions between it and the external memory consume a considerable amount of energy. On the other hand, the process of applying ML to images is a memory-intensive process.
The embedded AI accelerator reduces the amount of memory access by reusing the data obtained from the memory. This leads to an important reduction in power consumption.In particular, the number of transactions between the accelerator and the memory is reduced by a factor of nine compared to a GPU.Also, the accelerator can use the same data as output data and weight information.
Low power control using imputed zero data
One important feature of AI models is that a high percentage - typically 50 percent - of input/output data and weights are equal to zero. The DRP-AI uses a technology that detects zeroes inputs and avoids their computation, saving processors cycles and energy.
Schedule of the operation flow
The third technique is related to the synchronization of operations. This involves the management of computation operations, external memory access, etc.
The correct schedule of tasks avoids the occurrence of waiting times, improving the efficiency of the entire process. For example, by queuing the access to the memory after the weight information has been read and stored in the buffer, the memory access latency can be optimized. The best part of it is that you don’t need to take care of it because this optimization is automatically generated by the DRP-AI translator.
In the following figure, you can see thermal images that compare the heating of a DRP-AI system and a GPU.
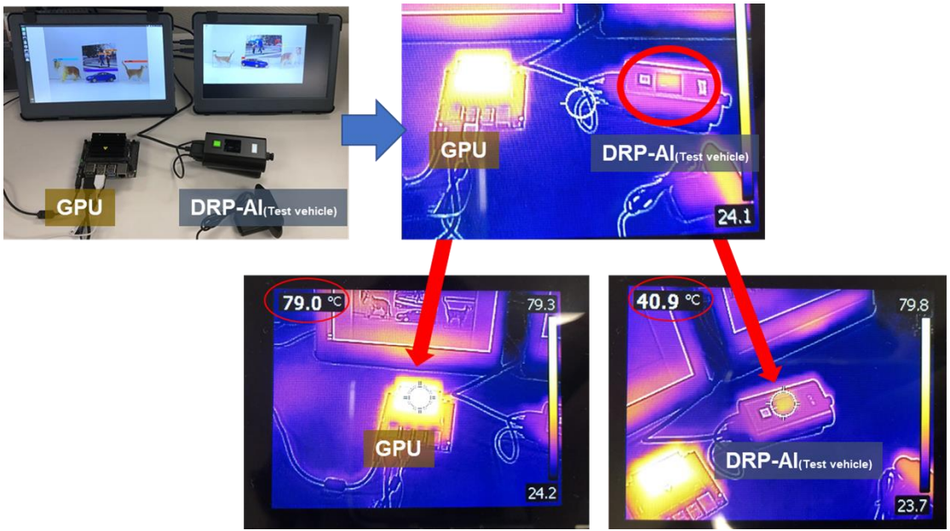
Brighter images mean more surface temperature, because of more heating. As you can see, there is a big difference between the heat dissipated by the GPU and the DRP-AI system. This is clear evidence of the outstanding performance of DRP-AI when we compare it with a typical GPU system.
Conclusions
Keeping power consumption at low levels and achieving an energy-efficient embedded ML device is a key factor because of the following reasons.
First, many embedded systems today depend on batteries and autonomous energy systems. At the same time, the execution of ML models is part of their intrinsic functionality. Some examples are video surveillance cameras with analytics, robots, and drones.
Also, the use of powering technologies like PoE requires keeping the power consumption of the devices at the levels supported by the standards.
Finally, having an energy-efficient device leads to a simpler and more compact design, avoiding big heat sinks and air-forced coolers.
To achieve the required level of efficiency you can use energy-efficient technologies, like the DRP-AI provided by Renesas.
This technology allows deploying the ML models in the embedded devices taking into consideration three key factors:
- Reducing the number of external memory access.
- Avoiding the computation of imputed zero data.
- Managing the scheduling of processing and memory access to avoid idle states.
These techniques produce an improvement in the use of energy up to a factor of nine, compared to traditional GPU systems.
About the sponsor: Renesas
At Renesas we continuously strive to drive innovation with a comprehensive portfolio of microcontrollers, analog and power devices. Our mission is to develop a safer, healthier, greener, and smarter world by providing intelligence to our four focus growth segments: Automotive, Industrial, Infrastructure, and IoT that are all vital to our daily lives, meaning our products and solutions are embedded everywhere.

References
1. https://www.renesas.com/document/whp/embedded-ai-accelerator-drp-ai