How Integrated Photonics Could Redefine Machine Learning Efficiency
What if electrons aren't the future of AI computation? What if photons could shoulder the load?

22 Jul, 2025. 5 minutes read

Artificial intelligence is advancing at a faster rate than the hardware designed to support it. Every leap in model complexity and training scale pushes GPUs and TPUs closer to their physical and thermal limits.
As data centres expand and edge devices become more powerful, the question is no longer how to build bigger AI systems; it’s how to run them efficiently. The current bottleneck? Power consumption, latency, and heat. But what if electrons aren’t the future of AI computation? What if photons could shoulder the load?
That’s the provocative challenge being answered by NeuroCore, one of the standout entrants in the recently completed PhotonDelta Global Photonics Engineering Contest. Their concept: a photonic neural network accelerator built on a hybrid photonic integrated circuit. By performing matrix operations using light, not charge, the design aims to deliver high-speed, low-power computation for AI workloads that are outpacing traditional silicon. It doesn’t enter as a direct GPU replacement. It’s a rethink of what AI acceleration should be.
The Growing Bottleneck in AI Hardware
As AI models continue to scale, from GPT-class language models to real-time vision systems in autonomous vehicles, the hardware load grows exponentially. The root cause is a single operation repeated billions of times per second: the multiply-accumulate (MAC). These operations form the core of matrix multiplication, the heart of neural network inference and training.
GPUs and TPUs are designed to execute these operations in parallel. However, parallelism in the electrical domain comes at a cost: high clock rates, resistive heating, and substantial energy consumption. In large-scale data centres, this results in mounting electricity bills and substantial cooling demands. For edge devices, thermal ceilings and battery constraints limit performance.
Even with advanced lithography and architectural enhancements, conventional chips are reaching a limit. More transistors mean more heat. Higher clock speed means higher power consumption. AI's needs are rising faster than Moore's Law can keep pace with.
This growing mismatch between computational demand and electronic capability is fuelling interest in a different class of hardware: photonic accelerators.
Spotlighting the NeuroCore Concept: Photonic Neural Network Acceleration
NeuroCore's approach begins by abandoning charge carriers in favour of photons. Their proposed accelerator utilizes light to perform core neural network operations, specifically matrix multiplication, through optical interference.
At the centre of this design are Mach-Zehnder interferometers (MZIs), which control the phase and amplitude of light traveling through waveguides. When configured in a mesh, these MZIs can encode weights and simulate the behaviour of a neural network layer. Instead of moving electrons, the system splits and combines coherent light beams, with interference patterns effectively performing the mathematical operations.
This technique, known as interference-based computing, offers two critical advantages: parallelism and speed. Light can travel along multiple paths simultaneously without interference (in the disruptive sense), and does so at, well, the speed of light. As a result, the NeuroCore mesh can handle multiple MAC operations simultaneously, with no clock overhead.
The system doesn’t go fully optical—electronics still play a crucial supporting role. Hybrid control circuits manage calibration, feedback, and the non-linear activation functions that follow optical matrix operations. Moreover, because most downstream systems and interfaces remain electronic, the processed optical signals must eventually be converted back into the electrical domain. This hybrid architecture—optical compute with electronic oversight—blends the speed and parallelism of light with the precision, tunability, and interoperability of electronics.
System Architecture and Technical Design
The NeuroCore system is built on a tri-material stack consisting of silicon photonics (SiPh), silicon nitride (SiN), and indium phosphide (InP). Each material serves a specific role, chosen for performance and manufacturability.
The light source originates from an InP laser diode. InP is the only one of the three with a direct bandgap, making it ideal for efficient light generation. The laser couples into the waveguide mesh through an optimized interface designed to minimize insertion loss.
From there, the light enters the heart of the system: a configurable mesh built from SiN and SiPh waveguides and couplers. The SiN component is critical for maintaining signal strength. Its ultra-low propagation loss enables long path lengths without degrading optical power, essential when light must pass through dozens or hundreds of interferometers.
The SiPh layer brings dynamic functionality. Silicon’s electro-optic properties enable phase shifting via electrical signals, allowing network weights to be programmed and updated in real-time. Phase shifters on each MZI arm allow real-time reconfiguration of the optical matrix.
At the output, integrated photodiodes convert the optical signals back into electrical form. This stage closes the loop, feeding processed data into external systems or storage. Alongside the mesh are control electronics, including drivers, calibration feedback systems, thermal stabilizers, and readout modules, that ensure consistent and accurate behavior under real-world conditions.
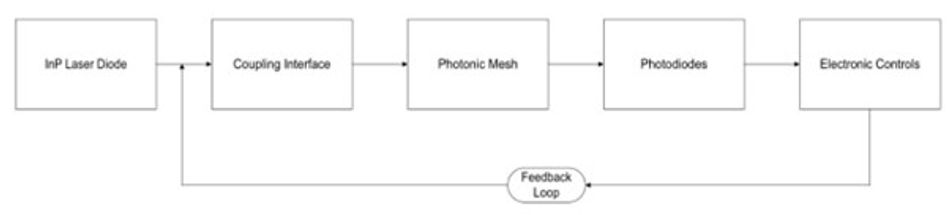
In short, it’s a complete optical MAC engine, backed by precision electrical tuning, modular, programmable, and ready to scale.
Applications in AI, ML, and High-Performance Systems
The immediate applications for this technology are in environments where AI inference needs to be fast, power-efficient, and scalable. Data centres are the obvious starting point. By offloading key layers of a deep neural network to photonic meshes, server clusters can reduce heat output and energy draw without compromising throughput.
Edge AI is another compelling use case. In self-driving cars, for example, photonic inference engines can process lidar or camera data in real-time without overheating the system or draining the battery. Similarly, in medical diagnostics, where speed and accuracy are crucial, optical neural networks could enable faster and more responsive cancer detection tools.
Photonic acceleration also aligns with broader sustainability goals. As AI becomes a baseline utility, the energy costs of computation matter more than ever. Reducing per-inference energy use at scale could significantly decrease the carbon footprint of machine learning.
And because the design is modular, the system can scale with model size. Larger networks can be mapped to larger meshes. Photonic layers can be stacked or tiled. Unlike traditional chip designs, this mesh doesn’t require rethinking the architecture with every increase in model parameter count.
Feasibility and Roadmap Ahead
NeuroCore’s project is currently in its research and planning phase. The team has completed a rigorous evaluation of photonic neural network design principles, material compatibility, and system architecture. The focus is now on simulation: modelling mesh behaviour, optimizing phase control circuits, and evaluating insertion losses across key paths.
One of the early challenges is the fabrication process. Integrating SiN, SiPh, and InP on a single chip requires precise alignment and bonding techniques to ensure optimal performance. This hybrid integration is achievable but demands advanced packaging workflows. Another challenge is stability. Optical systems are sensitive to temperature variations, so maintaining phase coherence requires real-time feedback and thermal compensation.
Fortunately, ecosystems like PhotonDelta are built to accelerate this kind of development. Access to fabrication pipelines, design support, and industry mentoring will be crucial in transforming NeuroCore’s early-stage design into a functional prototype. With the right partnerships, the accelerator could transition from concept to chip far quicker than most standalone efforts.
Conclusion: Lighting the Path to Scalable AI
AI isn’t slowing down, but our current hardware might. As neural networks grow deeper and data volumes balloon, the pressure on electrical systems to keep pace is becoming unsustainable. Photonic computing is becoming a necessity, not an alternative.
NeuroCore’s submission to the PhotonDelta Global Photonics Engineering Contest outlines a compelling future: scalable, energy-efficient, high-speed AI acceleration built on the principles of light physics. The designed hybrid photonic chip reimagines how and where computation happens.
As AI capabilities expand, the supporting infrastructure must also evolve. Innovations like this suggest that the future of artificial intelligence may rely not only on traditional silicon, but also on the integration of photonic technologies.