Advanced Split Computing Strategy to Achieve High Accuracy under Strong Compression Rates
BottleFit framework applied DNN models in image classification achieves 77.1% data compression with up to 0.6% accuracy loss on the ImageNet dataset.

02 Feb, 2022. 4 minutes read
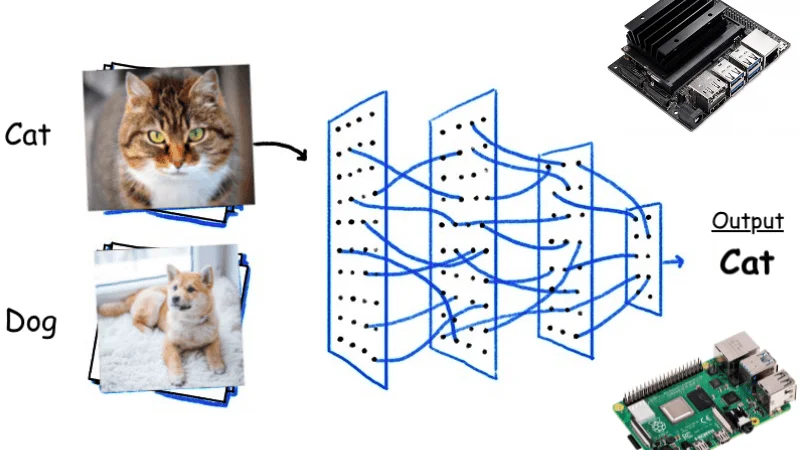
BottleFit Image Classification through Advanced Split Computing Strategy with Jetson Nano and Raspberry Pi 4
Deep neural networks have always been at the forefront of the implementation of computer vision applications. However, the increase in ML computation from cloud to edge introduces new challenges in a resource-constrained environment. For DNN, there are multiple layers between the input and output as the information from the input is represented through nonlinear functions. The existing challenges of increasing energy consumption due to continuous computation of the incoming data and reduction in accuracy with latency constraints have led the researchers from the University of California at Irvine and Northeastern University to develop a robust framework to overcome these issues.
Before jumping to the new BottleFit framework’s proposition, let us look at the existing design flow approach. The recent developments for solving the computation requirements focused on reducing model complexity and designing lightweight models like MobileNet and MnasNet. But these innovations came at the cost of significant accuracy loss of up to 6.4% compared to the large CNN models ResNet-152.
In this paper, the innovators have introduced a holistic approach and alternative solution to edge computing wherein, through split computing, a larger DNN is divided into head and tail models to be executed at the mobile device and edge server, respectively. The BottleFit framework not only aims to not only reduce power consumption and latency but achieves high accuracy even with strong compression rates. The critical aspect while designing the framework is to maintain the tradeoff between head model compression and tail model accuracy. Usually, with high compression rates, there comes a severe decrease in accuracy; however, this novel architecture and custom design flow of improved strategies goals towards maintaining high accuracy and bottleneck compression.
Effective and Efficient Split Computing in DNN
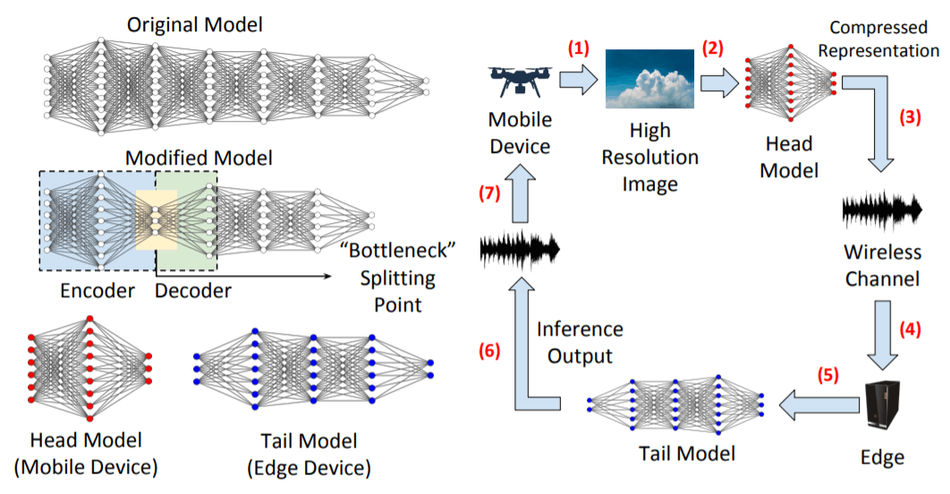
Understanding the split computing model used in this experimentation setup: the mobile edge device captures a high-resolution image given to the head model that performs compression and sends it to the edge server through wireless channels. The results are received at the edge server, which is fed to the tail model to provide inference output and transmitted wirelessly to the mobile device.
In split computing, the training process is not split but done offline. A bottleneck is defined to split the original model into head and tail sections. The bottleneck is introduced through encoder and decoder structures within the original model in the new proposed methodology. The layers are operated in the encoder-decoder approach of mapping the model input to the intermediate output and training to execute the downstream task without significant loss in accuracy. Through this approach, the researchers could influence the tradeoff between computing load on the mobile device and complexity and compression gains. All these factors substantially affect the overall performance of energy consumption, low latency and improved accuracy.
“Thus, when introducing bottlenecks, we need to carefully design the encoder and decoder; choose the bottleneck placement in the head model, and preserve the accuracy of the unaltered original model as much as possible,” the researchers explain.
Performance of BottleFit Framework– Outperforming Existing Design Flow Approaches
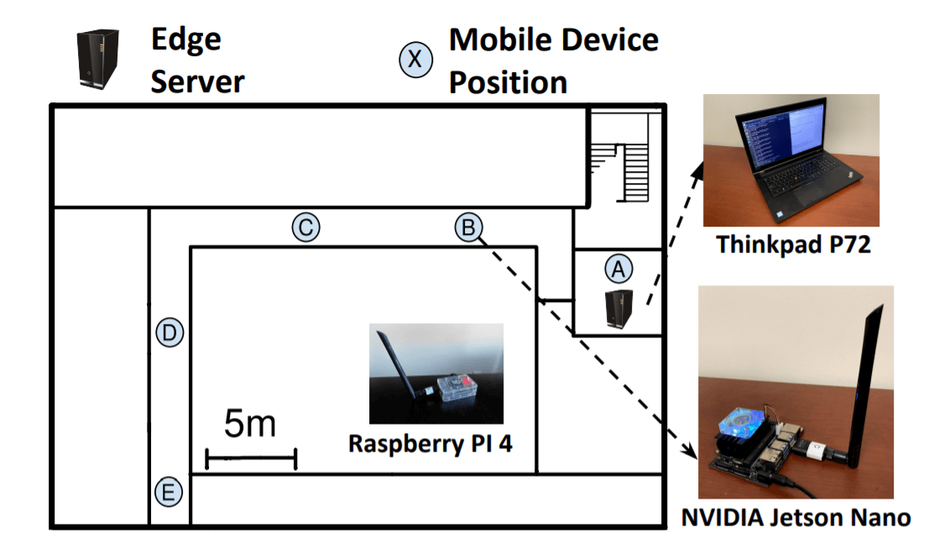
The experimentation of the framework is carried out on one of the most widely used TinyML applications, image classification, showing the BottleFit framework achieving over 70% data compression while only losing 0.6% on the accuracy front on the ImageNet dataset. The existing state-of-the-art design flow approaches, such as SPINN lose up to 6% in the accuracy for high compression rates. These evaluations were done on two famous embedded electronic devices, one popular for edge AI applications and the other known for its general-purpose tasks, NVIDIA Jetson Nano (GPU-based) and Raspberry Pi (GPU-less), respectively.
When we discussed improving the energy efficiency and lower latency, the BottleFit framework deployed on NVIDIA Jetson Nano shows the reduction of both parameters by up to 54% and 44%, respectively. While the exact model running on Raspberry Pi demonstrated a decrease of 40% and 62% on the power consumption and overall execution time. Along with this, it is noticed that the size of the head model executed on the mobile devices is 83 times smaller.
Summary of BottleFit Framework
Summarizing the new BottleFit framework that improves power consumption at high compression rates and maintains accuracy loss:
A novel framework of multistage training strategy that archives high accuracy with strong compression rates through properly designing the encoder and decoder structures to introduce bottlenecks in the original pre-trained model.
The evaluation of Jetson Nano board commuting with the edge server using Wi-Fi and LTE while RPi using LoRa shows considerable improvements in the overall performance.
For more details on the research methodology, check out the open-sourced research paper.
Reference
Yoshitomo Matsubara, Davide Callegaro, Sameer Singh, Marco Levorato, Francesco Restuccia: BottleFit: Learning Compressed Representations in Deep Neural Networks for Effective and Efficient Split Computing. DOI arXiv:2201.02693 [cs.LG]
M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, and L.-C. Chen, “MobileNetV2: Inverted Residuals and Linear Bottlenecks,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 4510–4520.
M. Tan, B. Chen, R. Pang, V. Vasudevan, M. Sandler, A. Howard, and Q. V. Le, “MnasNet: Platform-Aware Neural Architecture Search for Mobile,” in Proceedings of the IEEE Conf. on Computer Vision and Pattern Recognition, 2019, pp. 2820–2828.