Low-power AI processing hardware for edge devices
Learn how Renesas is providing solutions to this urgent edge AI challenge.

24 Jul, 2023. 7 minutes read

Image credit: Skygrid
Introduction
The need for an efficient AI inference system is required to continue the explosion of AI applications. Renesas’ RZ/V2M is one of the first RZ/V2 series products to address these issues. Based on the reconfigurable processor technology Renesas has developed over many years, they have created the DRP-AI (Dynamically Reconfigurable Processor for AI), an AI accelerator with high-speed AI inference processing that delivers the low power and flexibility demanded by endpoints. This article provides a case study of this product, exploring the technology and its impact on the user.
AI Applications
To set the context, we will first explore the two main components involved in creating an AI application; Training and inference.
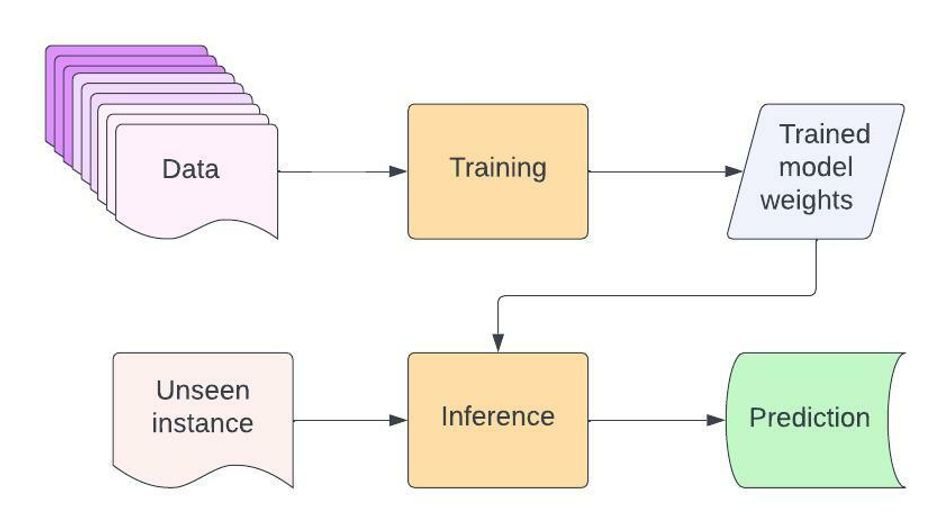
Training
Model training is a phase in the artificial intelligence development lifecycle where practitioners try to fit the best combination of weights and bias to a machine learning algorithm to minimise a loss function over the prediction range. Model training aims to build the best mathematical representation of the relationship between data features and a target label (in supervised learning) or among the features themselves (in unsupervised learning).[1]
Inference
This model can be deployed after the training to predict unseen data. This is called inference. We must be able to apply this in real-time endpoint devices to scale this solution.
Challenges in AI inference
As the user experience gets more advanced, End devices require AI models that can process inferences based on deep learning to take the place of human senses like hearing and vision. To implement AI in endpoints, the main concerns to be addressed are power consumption, size and flexibility. While cloud servers can have high computational powers equipped with high power and cooling devices, the endpoint device needs to work utilising low power consumption with minimum size. This can result in heat generation, inconsistent inference speed due to heating, shorter run times and increased cost.
So when it comes to power consumption saving, the best way to achieve that is to customise and optimise the hardware requirements to the specific AI processing. However, AI is a field evolving daily with significant impact, and thus, the hardware will become obsolete soon. Hence, the endpoint devices should be flexible enough to support newly developed AI models.
The limited cooling ability results in overheating of the processing unit, and when the unit starts emitting heat above a threshold, the memory and core frequencies of the unit are reduced to lower the heat emission. This is called `Thermal throttling`[2] and results in inconsistent inference speeds.
Immense research has been going on to make edge devices more computationally capable while utilising low power that allows real-time offline implementations of artificial intelligence solutions. According to Statista, the AI semiconductor market is expected to grow from $32 billion in 2020 to $65 billion in 2025 worldwide. It’s important to note that the market was only $17 billion in 2017[3].
Renesas, one of the leading contributors in the field of embedded systems, has created a new product, Renesas RZ/V2M, one of the first in the RZ/V series, that delivers low-power, low-heat, stable and flexible AI inference systems for edge devices.
Renesas RZ/V2M
Renesas RZ/V2M is a Microprocessing unit (MPU) optimised for image-based AI inference (Vision AI) to deliver lower power consumption and stable AI inference. The key technology that makes this product is the DRP-AI technology. While most AI accelerators specialise only in AI inference and rely on the CPU for pre- and post-processing, DRP-AI integrates pre- and post-processing and AI inference into a single DRP-AI hardware to achieve superior AI processing performance[4].

RZ/V2M is being adopted in applications such as surveillance cameras, industrial cameras, marketing cameras, gateways, robots, and medical equipment using AI inference, and these products will be shipped to the market soon[5].
The brain of the product, DRP-AI
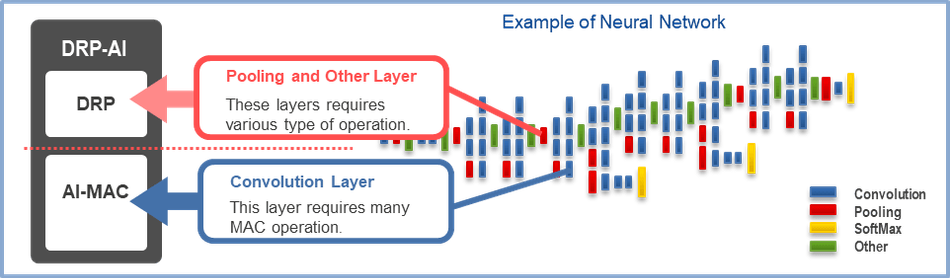
The core technology behind this MPU is the DRP-AI technology. The DRP-AI is hardware dedicated to AI inference with flexibility, high-speed processing, and power efficiency.
As the name suggests, it contains two components; the DRP (reconfigurable processor) and AI-MAC (multiply-accumulate processor). The Deep Learning network operations are split into these components. The convolution and fully connected layers are assigned to the AI-MAC, and all other operations, such as pre-processing and pooling, are assigned to the DRP.
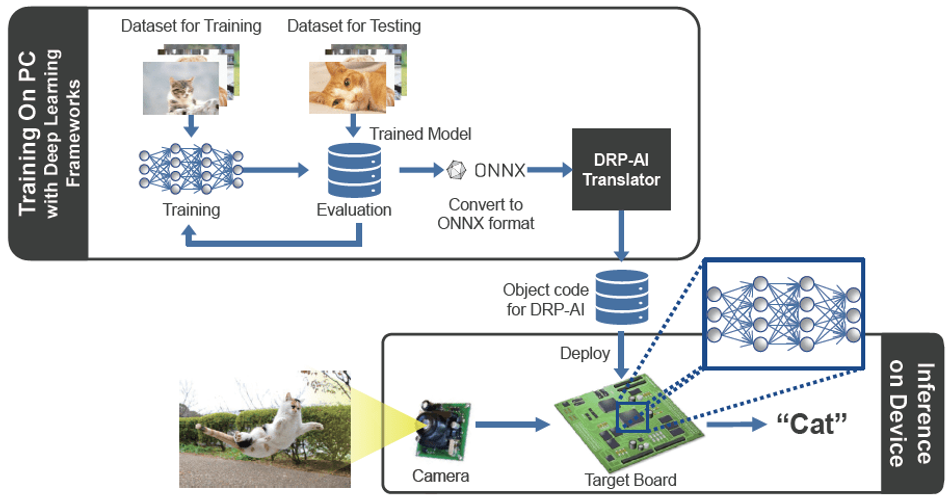
The DRP-AI translator is the software provided to enable users to easily implement AI models optimized to maximize the performance of DRP-AI on this flexible hardware. Multiple executables output by the DRP-AI translator can be placed in external memory. This makes it possible to dynamically switch between multiple AI models. In addition, the DRP-AI translator can be continuously updated to support newly developed AI models without hardware changes[4]. The DRP-AI Translator converts the originally trained weights to DRP-AI optimized executables independent of various AI frameworks.
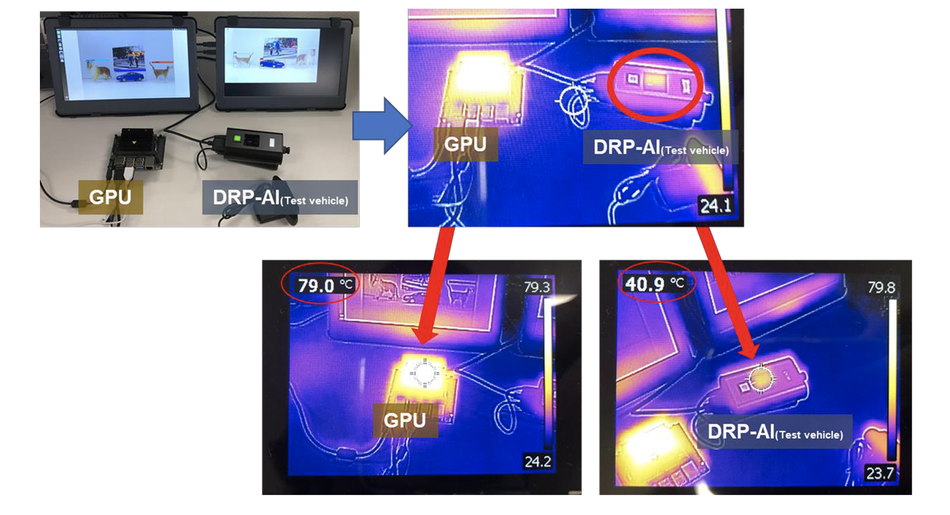
Impact
To measure the impact of the AI processor, a popular object classifier, TinyYolov2[8] was implemented in the DRP-AI test device and a commercially available GPU server regulated under the same conditions. The surface temperature of both systems was measured using thermography. The DRP-AI test device had a surface temperature of 40.9 degrees without using any heat sink when the TinyYolov2 was running at 42 fps. The GPU server had a surface temperature of 79 degrees, even with a heat sink installed running at a lower frame rate than DRP-AI.
The integrated RZ/V2M was further compared with a standard AI accelerator to evaluate the overall power consumption and efficiency by running YOLOv3-tiny[9] under regulated conditions. In addition, the performance was evaluated for another standard object classification model, MobileNet v2[10]. The results are listed in the below table.
Table 1. Performance comparison of RZ/V2M and other Accelerators, source:[5]
RZ/V2M MobileNet V2 | RZ/V2M YOLOv3-tiny | Other AI accelerator YOLOv3-tiny (Reference) | |
AI performance (fps) | 55fps | 52fps | 46fps |
Power consumption | 2.6W | 3.0W | 9.8W |
Power efficiency | 21.3fps/W | 17.2fps/W | 4.7fps/W |
As the table indicates, the RZ/V2M MPU can process at a higher frame rate with just ~3.0W power usage with a ~17fps/W which is 3.5 times more efficient than a regular AI accelerator. The surface temperature of the RZ/V2M was 29.7 degrees without any heat sinks compared to the 75 degrees with heat sink by the regular AI accelerator.
Conclusion
Overall, RZ/V2M is an MPU designed to implement deep learning models, specifically Vision AI, in edge devices with low power, stable performance, low heat emission, and flexible user modifications. The DRP-AI is the core technology that allows this high performance. This product is a stepping stone to developing advanced edge devices that can react intelligently in real-time. Visit Renesas’ website to read more about these products[11].
References
[1] Siebel, T. M. (n.d.). Model Training. C3 AI. Retrieved October 24, 2022, from https://c3.ai/glossary/data-science/model-training/
[2] Everything You Need To Know About Thermal Throttling. (2021, September 22). Electronics Hub. Retrieved October 27, 2022, from https://www.electronicshub.org/thermal-throttling/
[3] Alsop, T. (2022, April 19). Global AI semiconductor market size 2025. Statista. Retrieved October 24, 2022, from https://www.statista.com/statistics/1100690/ai-semiconductor-market-size-worldwide/
[4] Cognitive Product Department, IoT and Infrastructure Business Unit, Renesas Electronics Corporation. (2021, June). Embedded AI-Accelerator DRP-AI. Retrieved October 27, 2022, from https://www.renesas.com/kr/en/document/whp/embedded-ai-accelerator-drp-ai?r=1526446
[5] Yamano, S. (n.d.). Farewell, Heat Countermeasure: RZ/V2M Brings the Innovation for AI Products. Renesas. Retrieved October 27, 2022, from https://www.renesas.com/us/en/blogs/farewell-heat-countermeasure-rzv2m-brings-innovation-ai-products
[6] Renesas Electronics Corporation. (n.d.). AI Accelerator: DRP-AI. Renesas. Retrieved October 27, 2022, from https://www.renesas.com/us/en/application/key-technology/artificial-intelligence/ai-accelerator-drp-ai#overview
[7] Renesas Electronics Corporation. (2022, January 17). Renesas. Retrieved October 27, 2022, from https://www.renesas.com/kr/en/application/key-technology/artificial-intelligence/ai-accelerator-drp-ai/ai-tool-drp-ai-translator#overview
[8] YOLO: Real-Time Object Detection. (n.d.). Joseph Redmon. Retrieved October 27, 2022, from https://pjreddie.com/darknet/yolov2/
[9] YOLO: Real-Time Object Detection. (n.d.). Joseph Redmon. Retrieved October 27, 2022, from https://pjreddie.com/darknet/yolo/
[10] Sandler, M., Howard, A., Zhu, M., Zhmoginov, A., & Chen, L. (2018). MobileNetV2: Inverted Residuals and Linear Bottlenecks. arXiv. https://doi.org/10.48550/arXiv.1801.04381
[11] Renesas Electronics Corporation. Retrieved October 27, 2022, from https://www.renesas.com/us/en