Decoding Transformers on Edge Devices
Bert Moons, Director of System Architecture at AXELERA AI discusses bottlenecks in transformer inference for generative AI.
11 Jul, 2023. 10 minutes read

Recently, transformer-based models have led to significant breakthroughs in several forms of generative AI. They are key in both increasingly powerful text-to-image models, such as DALL-E or stable diffusion, and language and instruction-following models, such as ChatGPT or Stanford’s Alpaca. Today, such networks are typically executed on GPU-based compute infrastructure in the cloud, because of their massive model sizes and high memory and bandwidth requirements. In bringing real-time generative transformers to edge devices, their applicability could be greatly expanded. To this end, this article discusses bottlenecks in transformer inference for generative AI at the edge.
Introducing Transformers
Transformer models, first introduced in the 2017 research appear, ‘Attention Is All You Need’ [1] have been firmly established as the state-of-the-art approach in both sequence modeling problems, such as language processing and in image processing [2]. Its network architecture is based solely on attention mechanisms, as opposed to Recurrent or Convolutional Neural Networks. Compared to recurrent networks, this makes them much faster to train, as model execution can be parallelized rather than sequentialized. Compared to convolutional neural networks, the attention mechanism increases modelling capacity.
A transformer model typically contains an Encoder and Decoder stack, see Figure 1. Here, the encoder maps an input sequence of tokens, such as words or embedded pixels, onto a sequence of intermediate feature representations. The decoder uses this learned intermediate feature representation to generate an output sequence, one token at a time. The encoder stack exists out of N identical layers, split into multi-head attention-, normalization, elementwise addition, and fully connected feed-forward sublayers. The decoder stack differs in that it inserts a second multi-head cross-attention sublayer, performing attention over the output of the encoder stack, as well as over the newly generated output tokens. Figure 1 illustrates this typical Encoder/Decoder setup, as well as the concept of multi-head Dot-Product attention. We refer the reader to [1] for a detailed discussion.
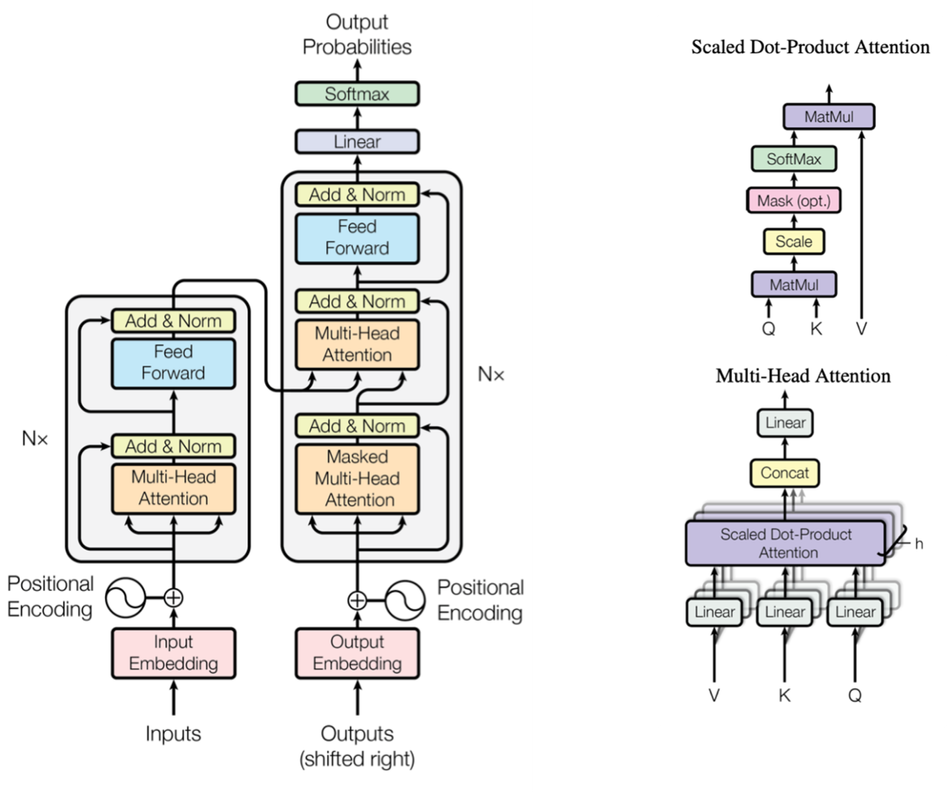
Since their introduction in 2017, transformer topologies and network architectures have largely remained the same, increasing their functionality through better training on more complex data rather than through architectural changes. The architecture proposed in Figure 1, is now used mostly unchanged in State-Of-The-Art Large Language Models such as ChatGPT [3], Falcon [4], Guanaco [5], Llama [6] or Alpaca [7]. The quality of the proposed models varies depending on how they are trained, and on their size, as is illustrated on the hugginface leaderboard at [8]. Smaller models contain less layers (lower N) and have lower embedding dimensions (smaller E). State-of-the-art large language models now contain between 7-65 billion parameters in their feedforward connections.
Challenges in Transformer Inference
Inferring transformer models on an Edge device is challenging due to their large computational complexity, large model size and massive memory requirements. On top of that, computational and memory requirements can be badly balanced in a modern AI accelerator, which focusses mostly on implementing many cheap parallel computational units and have limited memory capacity and bandwidth available due to physical, size and cost constraints. However, transformers are often memory-capacity and memory-bandwidth bound, as discussed below.
Transformer models can primarily be used in three ways: (1) encoder-only, typically in classification tasks, (2) decoder-only, typically in language modeling and (3) encoder-decoder, typically in machine translation. In the decoder-only case, the encoder is removed, input-tokens are directly fed to de decoder, and there is no cross-attention module. It is especially the execution of the decoder mode that is challenging, but even encoding can come at a high computational cost.
A. Computational Cost
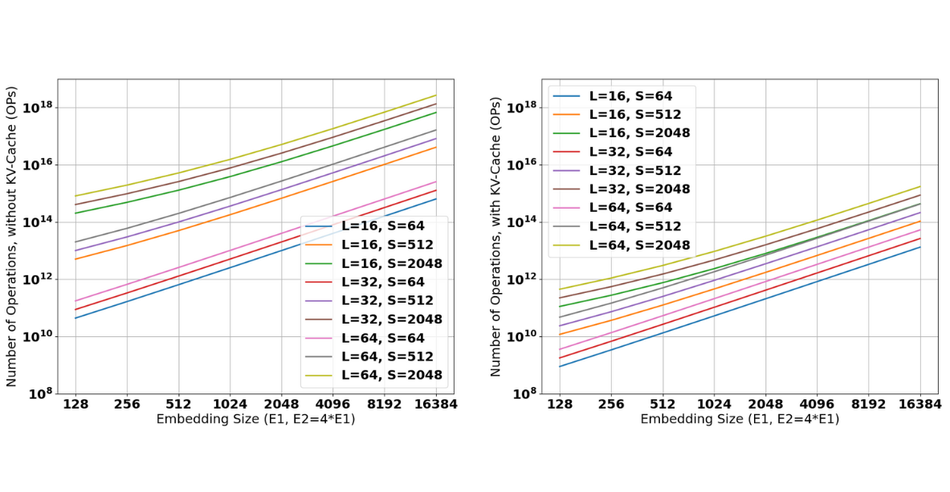
The computational cost of transformers is extremely high, as discussed in the survey by Yi Tay and colleagues [10]. The authors show the number of computations in a Transformer can be dominated by the Multi-Head Self-Attention module, whose complexity scales quadratically with the sequence length s. This is particularly challenging in vision transformers, where the sequence length scales with the number of pixels in an image, and when trying to interpret or generate large portions of text, with potentially thousands of words or tokens. This is illustrated in Figure 2, showing the number of operations required in a decoder-only transformer for various Embedding sizes E, Sequence Lengths S and number of layers N. Figure 2 (left) shows the number of operations required without caching optimizations, Figure 2 (right) the number of operations with caching optimizations, see below. Note that mostly the sequence length dominates the computational cost, due to the quadratic dependency on sequence length in self-attention.
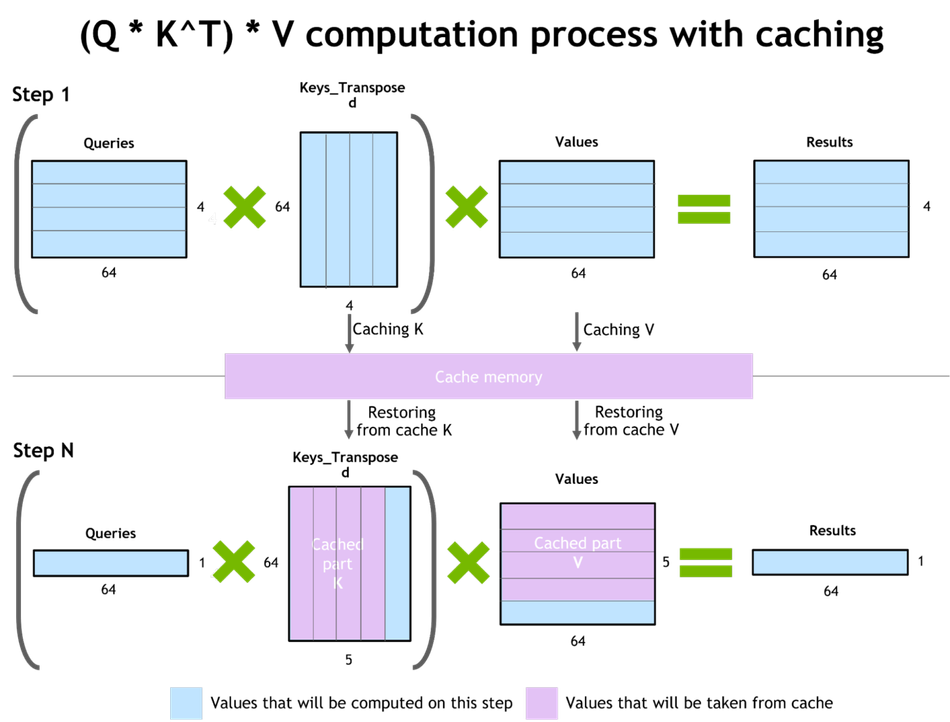
In KV-caching, intermediate data is cached and reused, rather than recomputed. Instead of recomputing full key and value matrices in every iteration of the decoding process, some intermediate feature maps (the Key and Value matrices) can be cached and reused in the next iteration, see Figure 3. This caching mechanism reduces the computational complexity of the decoding mechanism exchanging it for data transfers and essentially further lowering the applications arithmetic intensity. The memory footprint of this KV-cache can be massive, with up to terabytes of required memory capacity for relatively small sequence lengths in a state-of-the-art LLM model.
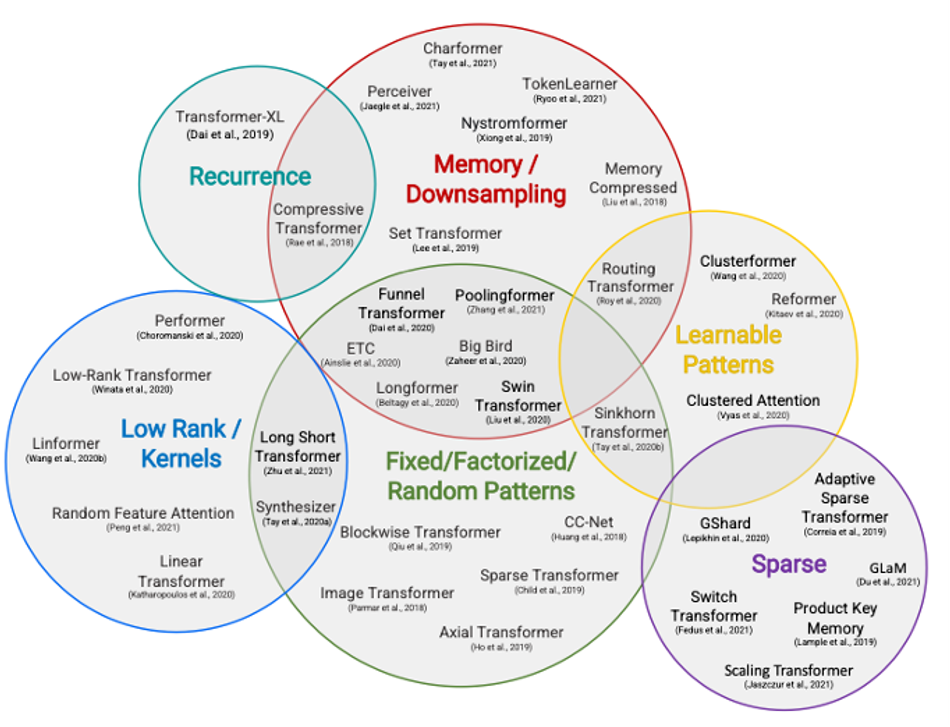
A large body of research focuses on reducing this computational complexity. Here, complexity is not reduced by KV-Caching, but by either (1) finding ways to break the quadratic complexity of self-attention through subsampling or downsampling the field-of view, or (2) by creating different types of sparse models that can be conditionally executed. See Figure 4 or the survey by Tay and colleagues [10] for a full overview of recent techniques in efficient transformer design. Notable works as Linformer [11] or Performer [12] manage to reduce the complexity from O(s^2) to O(s) at a limited accuracy cost. Other works such as GLAM [13] keep the O(s^2) complexity but reduce the computational cost by introducting various forms of sparsity. Though these works do reduce the computational complexity of transformers, especially on large sequence lengths, their overall success is mostly limited, and they are not yet used in the latest sota ChatGPT-like models.
Another mainstream approach that is used to reduce transformers computational cost and memory footprint is to aggressively quantize both the intermediate features and weights, often down to 8 or 4 bits, without losing accuracy [14].
B. Memory Footprints
Another fundamental problem in Transformer acceleration is their massive memory footprint, especially when used as a decoder.
First, and fundamentally, state of the art LLMs require 1-10’s of billions of parameters. Figure 5 (left) illustrates the number of parameters required for various sizes of networks, with number of layers varying between 16-64 and varying embedding sizes. Obviously, typical state-of-the-art models such as Llama [6] use network depths up to 64 layers, with embedded sizes in the range from 4k to 16k. Such models require 1-100GiB of parameter storage if every weight can be quantized to 1 byte. Figure 5 (right) illustrates the same for a single layer, showing that a single layer can require 1MiB to 1GiB of weights, depending on the embedding size.
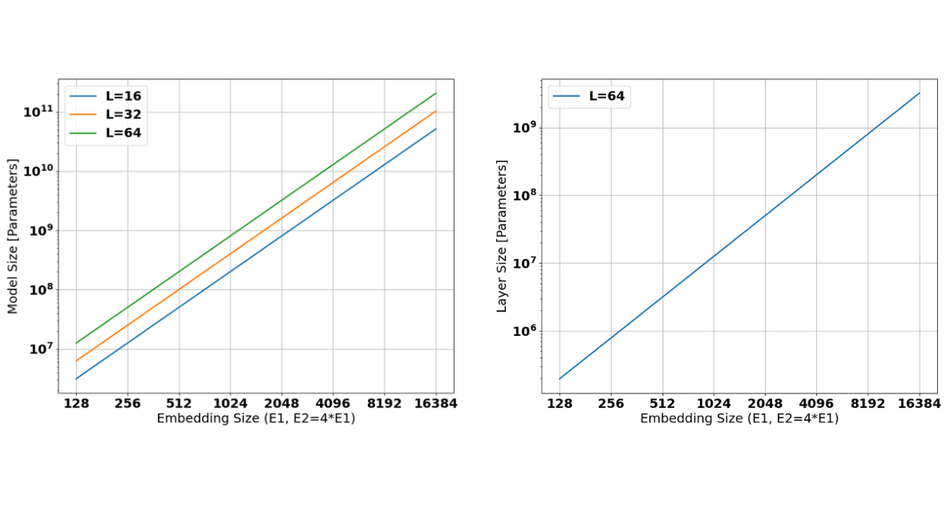
Second, although caching reduces computational cost by orders of magnitude, it can pose stringent memory requirements, requiring up to terabytes of intermediate data storage, depending on the batch and sequence size. Apart from memory capacity, the bandwidth requirements of decoding transformers further increase, as the KV-cache is too large to be stored on-chip and needs to be fetched constantly from an off-chip memory for every generated token.
The size and operation required in a KV-cache is explained in detail in [15]. For a particular run with batch-size b, input sequence length si, output sequence length so, embedding dimension E1 and hidden dimension E2 and the total number of transformer layers N the size of the model and the static KV-cache requirements can be easily computed.
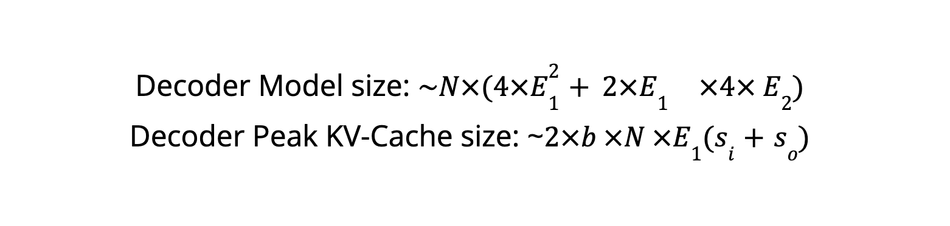
These sizes are further illustrated in the Figures below. Figure 6 shows the (peak) size of the KV-cache per model (left) and per layer (right) for a batch-size of 1. Even in such case, KV-caches up to 10GiB are required with up to 10-100MiB of KV-cache per layer.
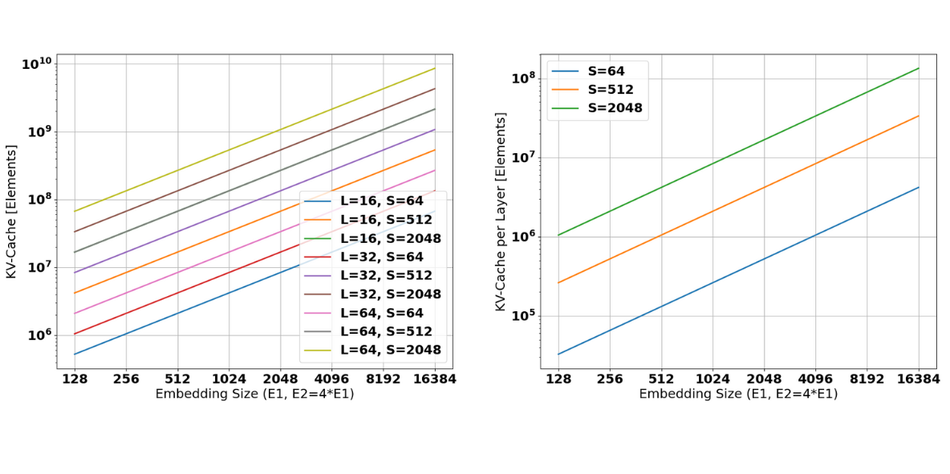
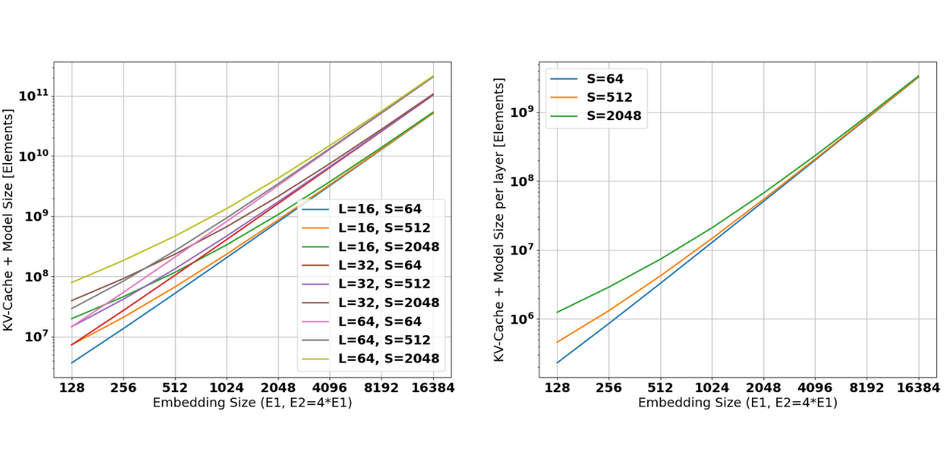
Figure 7 shows the combined memory requirements for the model parameters and the KV-cache for the same assumptions. This again illustrates the large capacity requirements for state-of-the-art NLP’s, requiring storage of up to 100GiB and 1-10MiB of weight and cache loading per layer.
C. Arithmetic Intensity
The information above on computational complexity and memory transfer requirements can be converted in a single Arithmetic Intensity metric: the number of operations that can be executed per byte that is fetched from external memory, assuming that all operations per byte can be executed after a fetch. Looking at Figure 8 (left) it is apparent that arithmetic intensities can be very high for long sequence lengths if kv-caching is not enabled. When KV-caching is enabled, the arithmetic intensity of decoding drops and the system immediately becomes bandwidth bound.
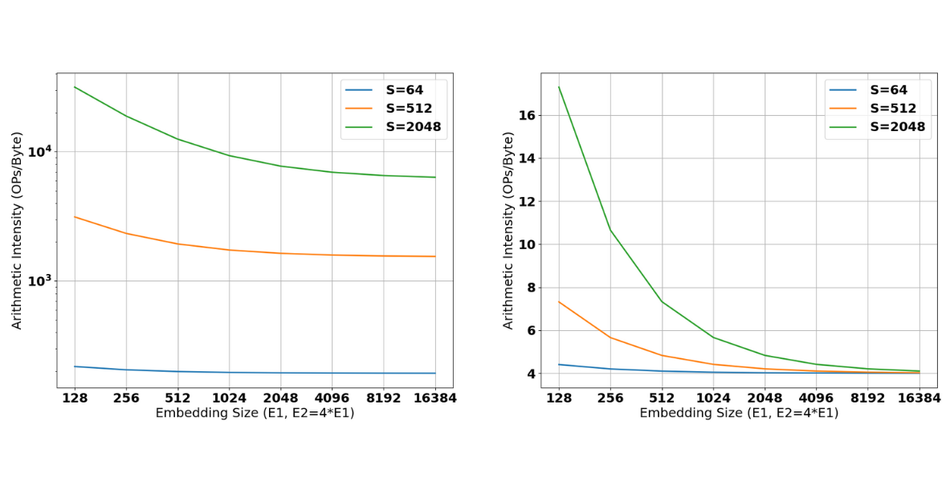
D. Discussion
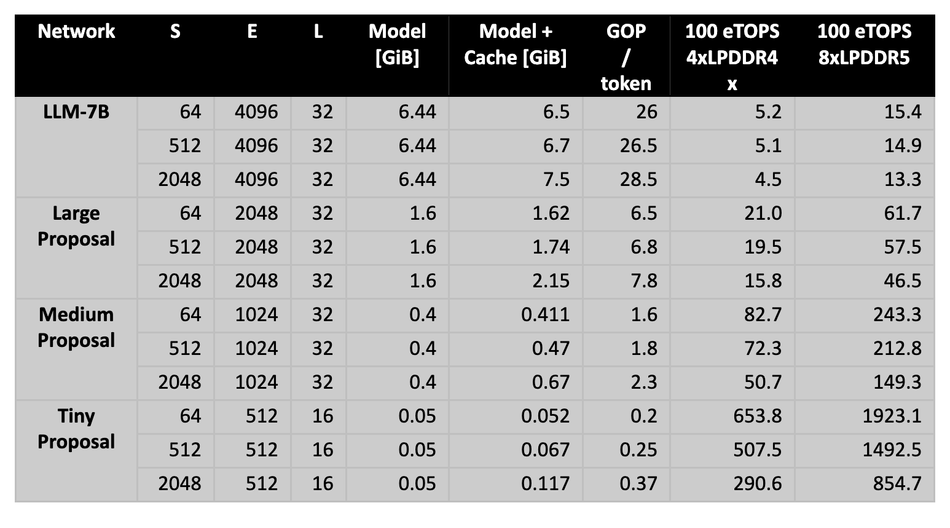
Embedded platforms typically have stringent power, memory capacity and memory bandwidth constraints, with computational budgets of up to 100-200TOPS peak on the latest generations. Let’s look at how a simplified LLM model with around 7 billion parameters (similar in size to LLAMA-7B [6]) would perform on an Embedded device, based on these high-level metrics. We are simplifying LLM complexity by modelling it as a decoder-only transformer with L=32, E=4096, per the template of Figure 1 (without cross-attention and feeding all input-tokens directly to the decoder stage). The transformer consumes and generates sequences of S=64, 512 or 2048 for a batch size of 1. The platform we are running this on is a machine with an effective 100 TOPS (Terra-Operations per second) and two options for its external memory connection: either 4 channels of LPDDR4x for a total bandwidth of 34GB/s or 8 channels of LPDDR5 with a total bandwidth of 100GB/s. For LLM-7B, it’s immediately clear that the system is memory bound and can generate only up to around 4-5 tokens per second, limited by the LPDDR4x interface, see Table 1. Even with 8 channels of LPDDR5, the maximum amount of throughput achievable is around 15 tokens per second.
If transformer topologies do not change significantly in the future, they need to be made considerably smaller to achieve higher performance on high end edge devices. To illustrate that, Table 1, discusses three model proposals (tiny, medium, large) which achieve much higher throughput up to the order of 1000’s of tokens per second depending on the model and the platform. For example, the Tiny Proposal achieves up to ~2000 tokens/second for short sequences on a 100TOPS machine with a peak bandwidth to external memory of 100GiB/s.
Table 1 - Estimating throughput in terms of tokens/s for a variety of models and for two different platforms: an edge machine with 100 effective TOPS (terra-operations per second) of compute capabilities and either 4 channels of LPDDR4x (+/- 34GiB/s) or 8 channels of LPDDR5 (+/- 100GiB/s). Inferring networks like LLM-7B for large sequence lengths is infeasible on such devices, network designers should focus on developing better, smaller models in order to increase throughput on such Edge devices. S is the sequence length, E is the embedding dimension (E2=4xE1) and L is the number of layers in the encoder and decoder.
Conclusion
Transformers and their usage in Natural Language Processing and generative AI is becoming ever more important. However, their computational cost and memory and bandwidth requirements make them hard to accelerate efficiently on specialized hardware at the edge. This blog introduces the transformer encoder and decoder architecture and discusses the challenges in inferring them on an edge device: high computational cost, high peak memory requirements, low arithmetic intensity. Several solutions to all of these are proposed.
First, efficient transformers increase efficiency by modifying the attention mechanism and reducing complexity from O(s^2) to O(s), where s is the sequence length. Other works focus on quantization and increasing sparsity of the neural networks. None of these solutions are currently mainstream. Second, we discuss the KV-caching mechanism to reduce the computational complexity of decoding by orders of magnitude, in exchange for bandwidth and memory capacity. KV-caching makes transformer inference bandwidth-bound, leading to very low performance on the order of 5 tokens per second for the current smallest state of the art NLP models, like the discussed LLM-7B. We propose several network topologies that can be accelerated efficiently on an Edge platform. To bring transformer decoding inference to Edge devices, network designers should focus on making them significantly smaller without sacrificing application accuracy.
References
[1] Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017), https://arxiv.org/pdf/1706.03762.pdf
[2] Moons, Bert "Transformers in Computer Vision”, https://www.axelera.ai/vision-transformers-in-computer-vision
[3] https://chat.openai.com/chat
[4] https://huggingface.co/tiiuae/falcon-40b
[5] Dettmers, Tim, et al. "Qlora: Efficient finetuning of quantized llms." arXiv preprint arXiv:2305.14314 (2023), https://arxiv.org/abs/2305.14314
[6] https://github.com/facebookresearch/llama
[7] Taori, Rohan, et al. “Stanford Alpaca: An Instruction-following LlaMA model”, https://github.com/tatsu-lab/stanford_alpaca
[8] https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
[10] Yi Tay et al. “Efficient Transformers: A survey”, ACM computing surveys 2022. https://arxiv.org/pdf/2009.06732.pdf
[11] Zhou, Haoyi, et al. "Informer: Beyond efficient transformer for long sequence time-series forecasting." Proceedings of the AAAI conference on artificial intelligence. Vol. 35. No. 12. 2021. https://arxiv.org/abs/2012.07436
[12] Choromanski, Krzysztof, et al. "Rethinking attention with performers." arXiv preprint arXiv:2009.14794 (2020). https://arxiv.org/abs/2009.14794
[13] Du, Nan, et al. "Glam: Efficient scaling of language models with mixture-of-experts." International Conference on Machine Learning. PMLR, 2022. https://arxiv.org/abs/2112.06905
[14] Shen, Sheng, et al. "Q-bert: Hessian based ultra low precision quantization of bert." Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 34. No. 05. 2020. https://arxiv.org/abs/1909.05840
[15] Sheng, Ying, et al. "High-throughput generative inference of large language models with a single gpu." arXiv preprint arXiv:2303.06865 (2023). https://arxiv.org/abs/2303.06865