An engineer's guide to deploying machine learning in smart devices using audio edge processors
Utilizing audio edge processors for efficient execution of Machine Learning Tasks.

12 Oct, 2021. 10 minutes read

This article was co-authored by Eswar Reddy Kadireddy and Vikram Shrivastava.
Introduction
Following the COVID19 pandemic outbreak, business and personal communications are increasingly carried out through video calling devices. The latter are nowadays ubiquitous: They are not only part of our personal devices (e.g., smartphones, laptops, headsets), but also embedded in TVs and other IoT devices (e.g., Amazon Echo, Google Home, Aloha from Facebook) that come with audio-enabled functionalities such as voice control. Audio Edge processors are specialized devices that deliver superior audio quality during teleconferences and other audio-centric applications. To this end, they can process audio, understand the communication context and optimize the users’ experience based on functionalities such as selective or adaptive noise cancellation or even Hi-Fi audio reconstruction.
To provide these functionalities, Audio Edge processors must support the execution of intelligence functionalities based on machine learning, which asks for high computing capacity on the devices. Moreover, they must offer low-latency processing to perform their operations within timescales that are tolerated by the users. Furthermore, they must come with strong security to prevent possible breaches and cybersecurity attacks. It is also important to provide developer-friendly functionalities that boost their integration in a variety of applications. Nevertheless, despite the need to perform compute-intensive operations quickly, they must also operate in a power-efficient manner.
The fulfillment of the above-listed requirements asks for innovative high-performance edge devices, which provide intelligence, security, and flexibility to meet diverse audio and voice interaction requirements in different settings.
In this context, the Knowles IA8201A core audio edge processor provides an effective solution that meets stringent communication requirements and offers a clear user experience. At the heart of the Knowles IA8201A core lies its cutting-edge Machine Learning (ML) capabilities, which can be flexibly accessed by audio application developers and ML engineers.
Why Knowles IA8201 core?
The IA8201 is a fully customizable, multi-core audio processing platform with DSP SDK ( Software Development Kit) tools that combine Knowles’ Audio expertise in audio transducers, acoustics, DSP, and algorithm development. IA8201A has two Cadence Tensilica-based, audio-centric DSP cores for maximum design flexibility. The DSP cores provide low-latency, high-performance algorithm processing, and ultra-low-power performance. Open DSP capability provides a robust platform for 3rd-party solutions. The DSP SDK with Knowles and Xtensa HiFi 3 instruction sets allows for extensive audio capabilities in voice and audio processing, voice user interfaces, and ambient sound processing.
The IA8201 includes the DeltaMax processor (DMX) and the HemiDelta Processor (HMD), these two cores come with specially designed instructions for both floating point complex-valued Multiply Accumulate operations (MAC) and fixed-point machine learning applications of deep neural networks. This makes IA8201 an ideal choice for edge processing. The following sections describe the key features of IA8201 cores that are specially designed for edge/ML processing.
IA8201 Core Architecture Overview
To achieve high-performance at ultra-low power, Knowles has designed single instruction, multiple data (SIMD) instructions which works on Afloat data on lightweight floating unit for Audio processing and customized fixed point SIMD instructions for ML applications. The block diagram below depicts the top level architecture of DMX core of IA8201. This article focuses mainly on Machine Learning (ML) capabilities of IA8201.
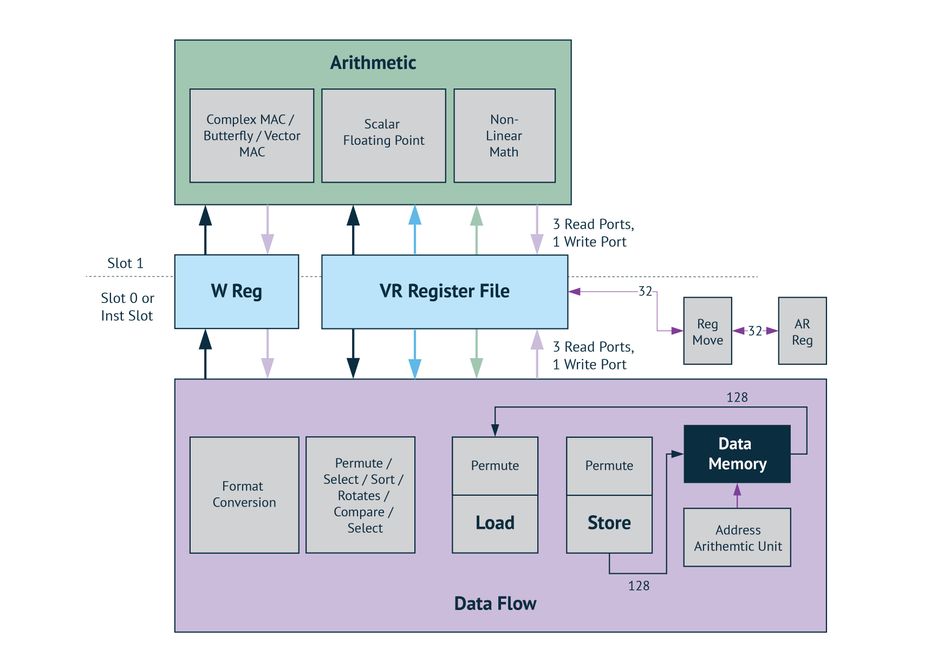
Figure 1: The top-level architecture of DMX core of IA8201
Machine Learning Capabilities
The Machine Learning (ML) applications are built based on Artificial Neural Network architectures, and Convolutional Neural Networks (CNN) are among the most popular core neural networks used in speech recognition and computer vision applications. The implementation of CNN includes the generation of feature vectors, the processing of the features through the layers of the network, and post-processing of resulting output. Typically, the processing of feature vectors or arrays through the layers of networks is computationally intensive and requires special instructions and architecture to complete the process in the shortest time at lowest power. A commonly used type of CNN, consists of numerous convolution layers following sub-sampling and pooling layers, while ending layers are Fully Connected layers.
A typical CNN Architecture consists of below layers.
- Convolution Layers
- Sub-sampling / Pooling layers
- Fully Connected / Deep Neural Network (DNN) Layers
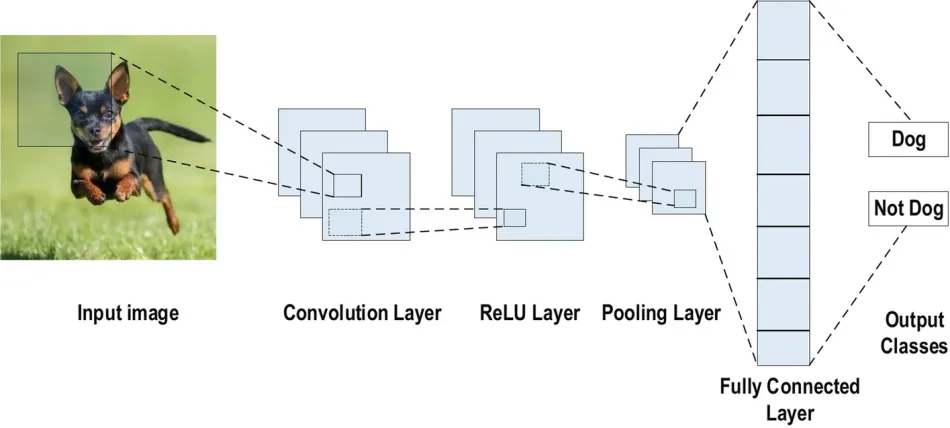
Figure 2: Typical CNN Architecture. Image credit: Alzubaidi[1]
Generally, processing vectors through convolution and fully connected layers is a computationally-intensive process. Knowles has designed special Matrix Vector Multiply (MVM) and non-linear activation instructions to accelerate these computations.
A typical Fully Connected Deep Neural Network (DNN) is shown below. It consists of an input layer, hidden layers, and an output layer.
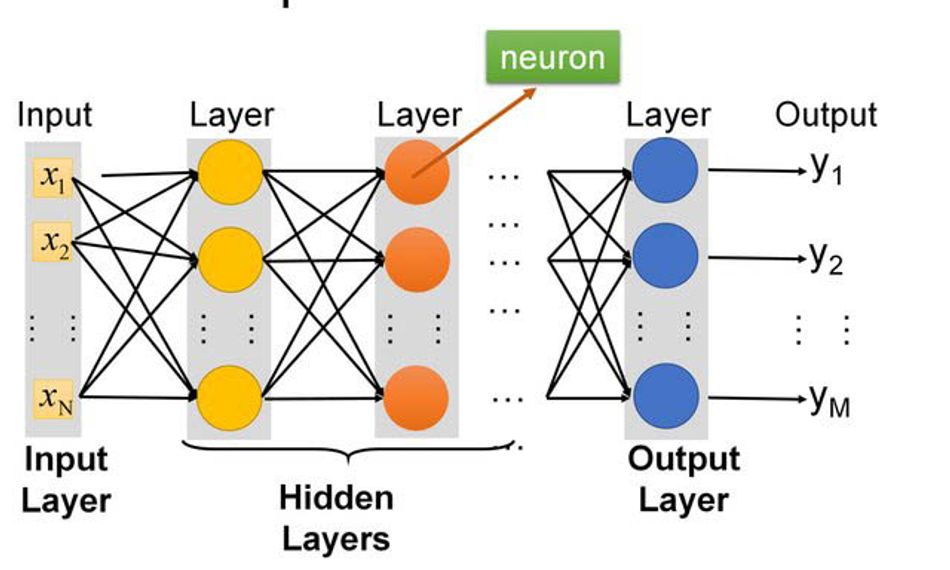
Figure 3. DNN Architecture
At each active node, several operations are performed. This includes
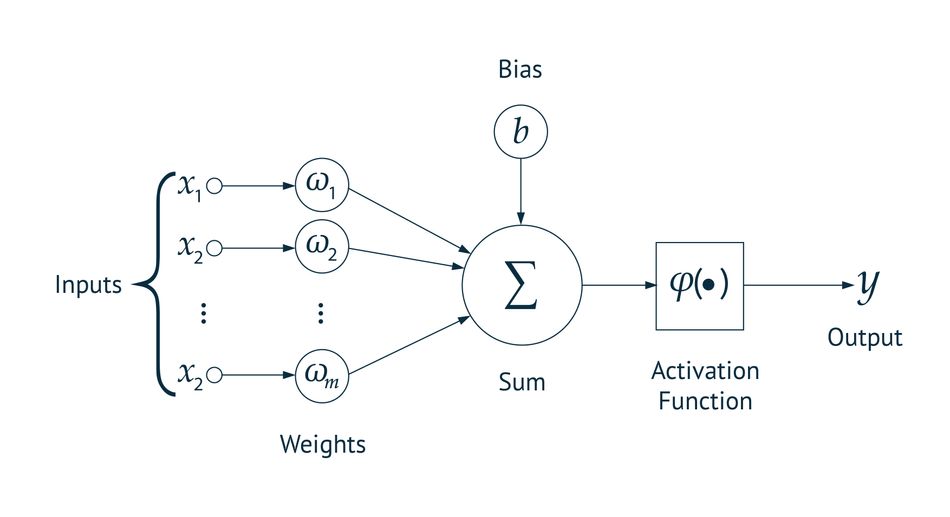
Figure 4: Operations at each active node
- Weighing – Scaling of the inputs to the node
- Summation – Adding of scaled inputs and biases
- Activation Functions – Non-linear function to regulate the contribution from the node to next level
Knowles IA8201 DSP’s cores provide several advantages for processing of ML functions. This is due to the following features
- Dedicated instructions for ML computations
- Highly optimized ML library – implements most commonly used kernels and functions in ML processing
- Highest throughput at ultra-low power
- Optimized TensorFlow Lite library for Microcontrollers (TFLu)
- Software Development Kit (SDK)
- Example applications
- Optimized libraries for ML and classical digital signal processing
- Documentation
Dedicated Instruction-set for ML
Matrix Vector Multiply (MVM) Instructions
The instruction can perform 16 8bx8b MACs (Multiply and Accumulation) in a single cycle on the core DMX and 8 8bx8b MACs on the HMD core. For example, it performs below operations in a single cycle on DMX.
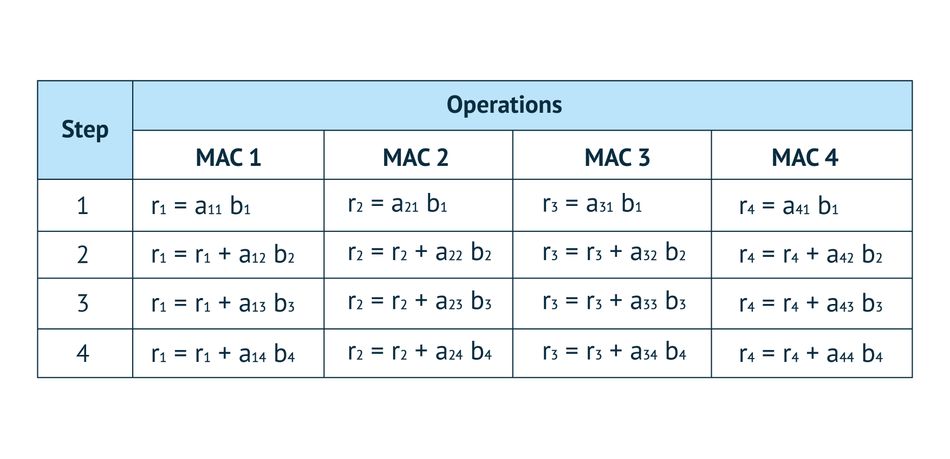
Sparse MVM Instructions
In some ML applications, the computational matrices are spare, that is most of the elements in matrix are zeros. In that scenario , a regular MVM function is inefficient. IA8201 library provides special instructions for sparse matrix processing.
The main focus of sparse matrix processing is to maximize compression while feeding a scalar arithmetic unit. The data is packed maximally and the additional storage to specify the location of the non-zero elements is minimized. This approach doesn’t map well to SIMD architectures unless the matrix has a known structure (such as block diagonal). With SIMD architectures there are conflicting requirements - minimizing storage while performing the maximum number of useful multiplications per cycle. This is illustrated in figure.
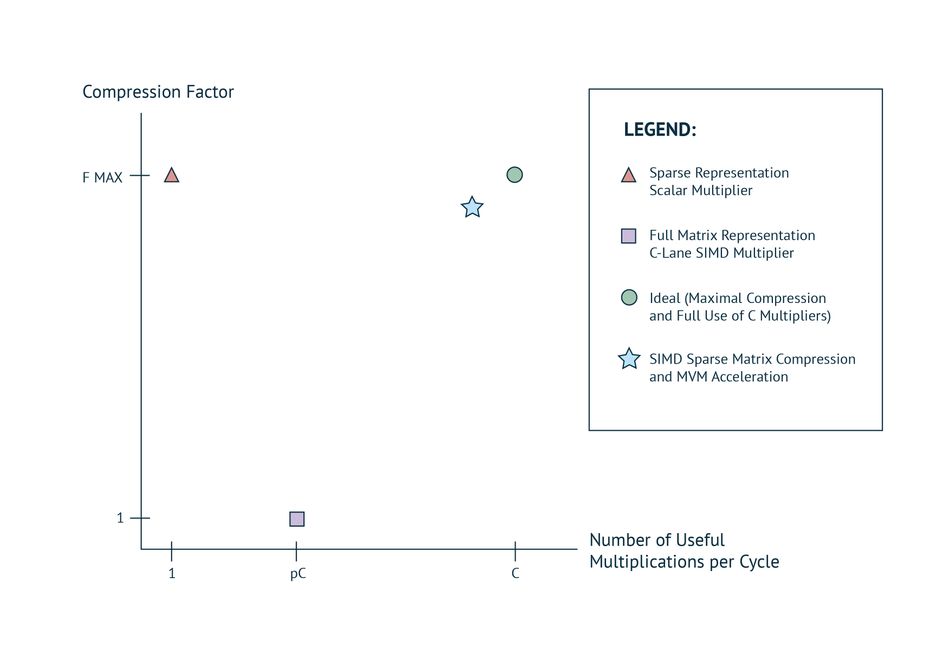
Figure 5: MVM: Compression Vs Execution Speed Trade-offs
The axes show the two competing performance criteria: the horizontal axis execution and the vertical axis compression. C denotes the number of computational units (multiply and accumulate) and p denotes the proportion of non-zero matrix elements.
The pink triangle shows the best performance with a single computational unit. The orange square shows the performance with C computational units if no advantage is taken from ignoring zero matrix elements. The green circle shows the best possible performance if maximally compressed matrix elements can magically be used to perform C useful multiplications per cycle. The blue star qualitatively shows the intended performance of Sparse MVM instruction.
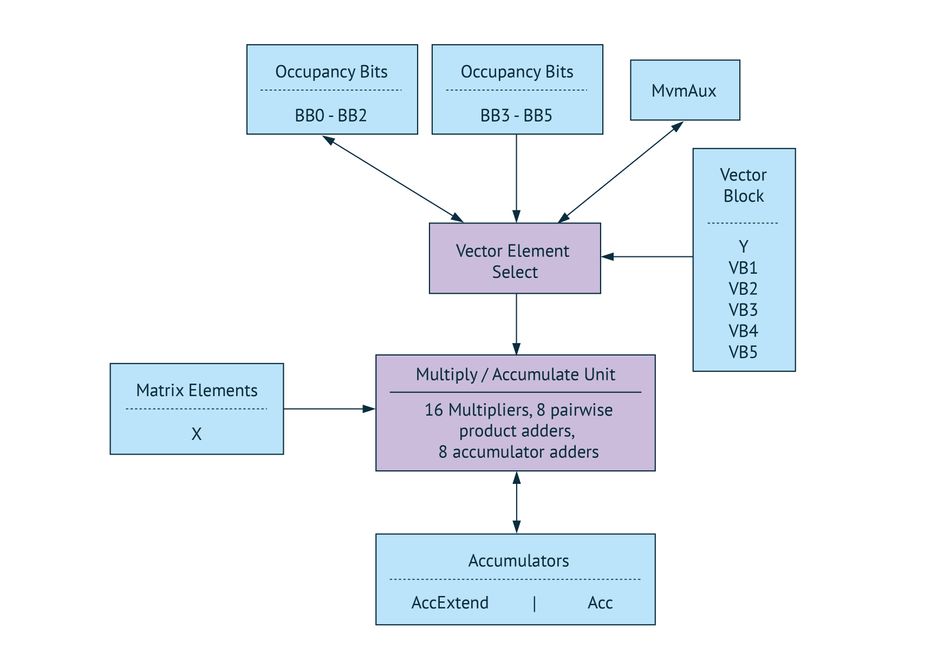
Figure 6: Block diagram of MVM instruction
Both regular MVM and Sparse MVM instructions share the same hardware except the regular MVM instruction bypasses the elaborate index generation logic used in the sparse matrix case.
Convolution Instruction
The one-dimensional convolution arithmetic shares the hardware used by the MVM described in the previous section. Eight dot products are computed in parallel, with two updates per dot product per cycle. The dot products are actual convolutions if the coefficients are stored in reverse order.
Special Instructions for Activation Functions
The IA8201 has special instructions for below activation functions. These include:

Highest throughput at ultra-low power
To meet performance and power efficiency goals, several architectural strategies have been adopted as listed below
- Lightweight floating point number representation for 32-bit data
- 8-bit Fixed Point MACs with 32-bit accumulation
- Machine learning hardware acceleration
- Single-cycle throughput (two-cycle latency) for most critical instructions like complex MAC, Matrix Vector Multiply (MVM)
- Streamlined data flow mechanism to reduce overhead of data movement and to keep the core arithmetic units consistently occupied
The table below captures the compute power of the IA8201 cores.
| S. No | Processor Function | HMD | DMX | Comments |
| 1 | Speed (MHz) | 175 | 175 | |
| 2 | DSP MAC MOPS | 1400 | 2800 | 32-bit float ops |
| 3 | ML MOPS | 2800 | 5600 | 8-bit fixed point ops |
| 4 | SIMD vector for CMAC | 4 | 8 | 32-bit float ops per cycle |
| 5 | SIMD Vector Dimension | 2 | 4 | 32-floating point ops per cycle |
| 6 | SIMD DNN Acceleration | 8 | 16 | 8-bit Macs per cycle |
| 7 | Bus width | 64 | 128 | VR registers |
| 8 | Dynamic power µW/MHz | 72 | 107 | |
| 9 | HiFi3 Support | Yes | No |
The following table provides some commentary on Knowles ML architecture considerations:
| Feature | Rationale | Impact |
| Machine learning matrix-vector multipliers | Matrix-vector multiplication used for machine learning (ML) classification | 1/10th the energy per multiply |
| Low-precision operations | ML relies on a huge number of 8-bit operations for inference | Twice the operations per cycle |
| Large buses, high memory bandwidth | 64b/128b busses continuously load data for computing for single cycle compute | 50% less memory load overhead |
| Machine learning hardware acceleration | Many non-linear functions needed for machine learning (e.g. sigmoid) | 20% less cycles per inference |
| Sparse matrix support | Graceful trade-off between ML model precision and overall memory usage | Low-power embedded ML |
| Large machine learning accumulators | Accumulation through deeper network without incurring precision loss | Higher algorithm performance |
IA8201 Software Development Kit (SDK)
Knowles software development kit (SDK) is a solution for porting and optimizing, algorithms and evaluation. Knowles provides SDK for the IA8201 processor, which includes highly optimized standard ML library functions, TensorFlow Lite library for microcontrollers (TFLu), and relevant sample applications & documentation.
Standard ML Library
Knowles provides highly optimized ML functions for the following neural network architectures as part of IA8201 SDK.
- Deep Neural Networks (DNN): The software architecture is flexible, allowing the developer to easily define the parameters below
- Number layers
- Number of node for each layer
- Precision (8-bit, 16-bt & 32-bit) - input and coefficients
- Activation function
- Convolutional Neural Networks: SDK implements CNN neural network architecture as a standard offering.
- Long Short-Term Memory (LSTM): SDK implements LSTM neural network architecture as a standard offering. The developer can choose the required activation function based on their needs.

Figure 7: The Long Short-Term Memory Cell
TensorFlow Lite for Microcontrollers (TFLu)
TensorFlow Lite for Microcontrollers (TFLu) is developed by Google with the motivation to run machine learning models on microcontrollers. Knowles provides an optimized TFLu library along with required tools as part of IA8201 SDK (Software Development Kit). This SDK enables ML developers to deploy their TensorFlow models on Knowles cores with minimal development cycle.
The TensorFlow core kernels are mapped to Knowles ML Instruction-set to get best cycle advantage on Knowles cores. The block diagram below depicts a typical ML application using TFLu library.
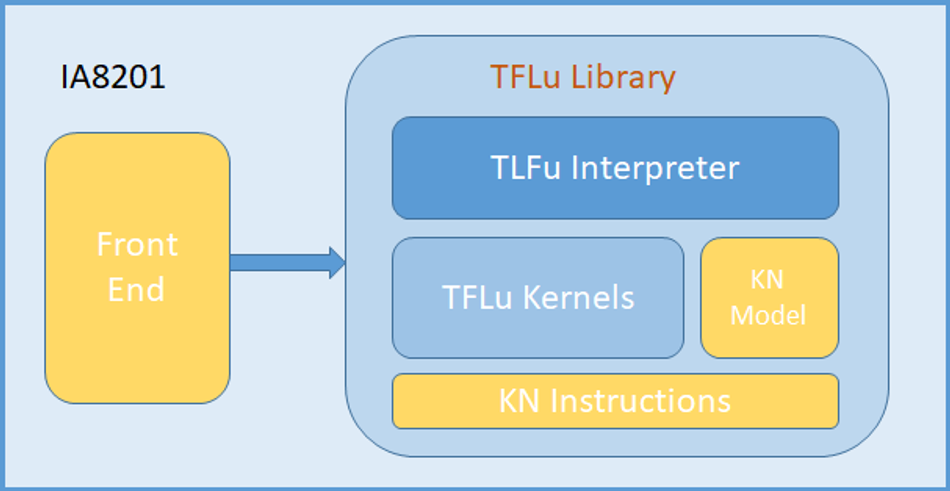
Figure 8: Block diagram of typical ML application using TFLu
A typical NN (Neural Network) based machine learning application would consist of NN model (trained offline on a server) and an inference engine (running on target processor in real-time) that infers from the model to predict results. The TensorFlow Lite provides APIs for both training the model and inference from the model. The developer can easily deploy their model on IA8201. The SDK provides required software and tools to run the TFLu model on the IA8201 development board. The development flow is illustrated below.
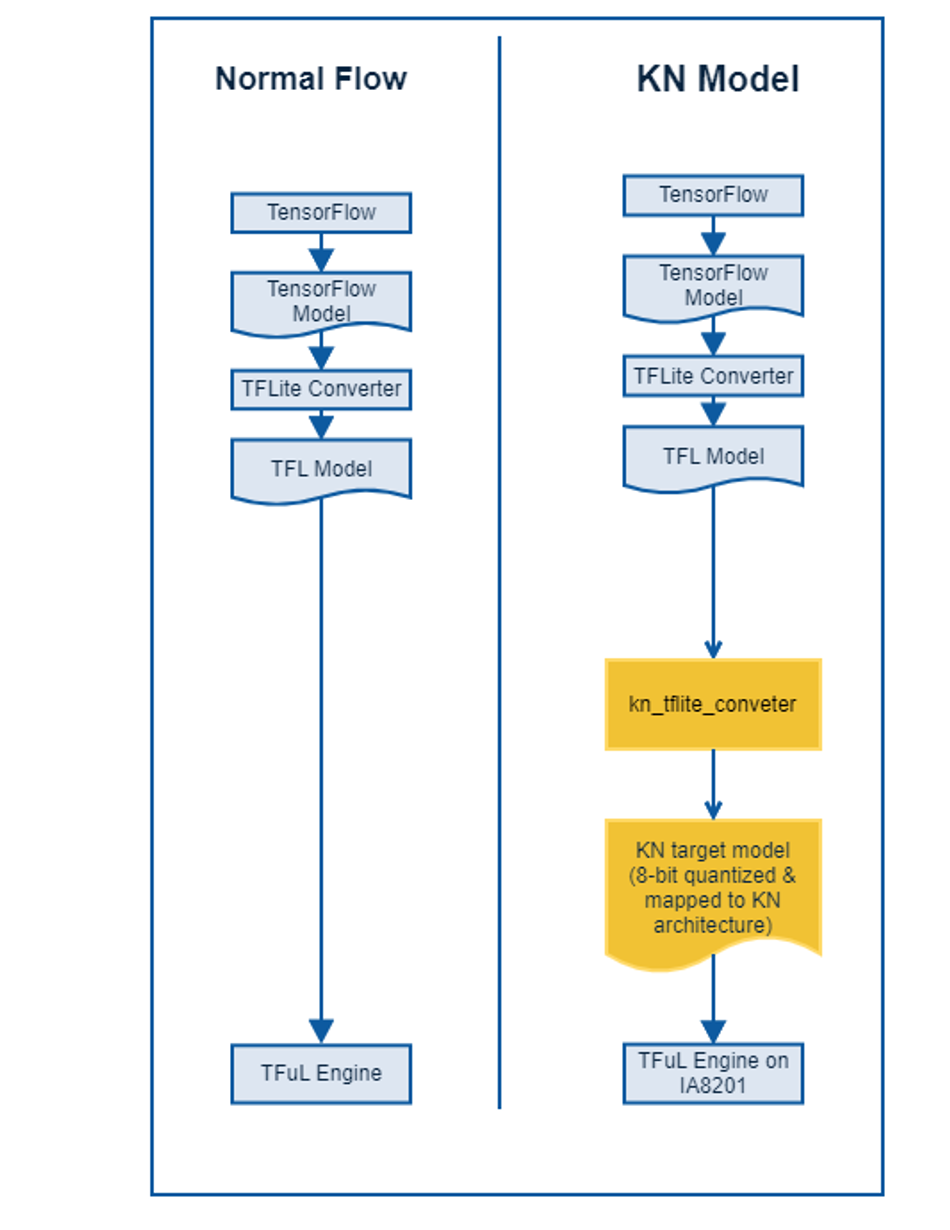
Figure 9: TFLu Development Flow Diagram
From the above diagram, it is clear that once the ML developer is satisfied with performance of the TFLu model on TensorFlow framework running on ML server, the same model can be deployed on IA8201 with minimal effort. The TFLu library on IA8201 enables developers to experiment different neural network architectures on Knowles cores.
TFLu SDK on IA8201: Key Use Cases
The IA8201 SDK unleashes the power of ML, including Deep Learning and Neural Networks on edge audio devices and enables developers to create novel applications. Some prominent examples include:
Wake-words for smart devices: Leveraging deep neural networks, developers can build detectors and classifiers for “Wake Words” and “Wake Phrases” similar to the popular “Alexa”, “Echo”, “Computer”, “Hey Siri” and “OK Google”. Developers can use TFLu to build models that credibly identify the wake words of their choice. By building proper ML models, they can also choose to make the audio device responsive to similar sounds and words, or alternatively avoid the trigger unless the desired words are clearly expressed.
Event Detection: The TFLu SDK enables the detection of a wide array of audio events, ranging from fire alarms, to baby cry and dog barking. The detection of such events enables the development of many applications for different sectors, including smart home, smart building and smart security applications.
Voice Commands for IoT Devices: Access to TFLu enables the development of voice-control functionalities over applications in embedded IoT devices. For instance, it is possible to enhance audio players with speech-enabled functionalities like prompts for playing a certain song. In a similar way, audio devices can be instructed to send out e-mails or other notifications.
Conclusions
Audio edge processors are at the heart of many entertainment, media, and home automation devices, while being indispensable for the operation of video calling and video conferencing tools. Specifically, audio edge processors are key enablers of the users’ experience through providing functionalities like selective noise cancelation and context-aware high fidelity audio reconstruction. These powerful functionalities are context-aware i.e., they consider the context of the user and of his/her communications. Their implementation is based on high performance, low-latency, and power-efficient machine learning systems.
The IA8201 Audio Edge Processing device is a fully customizable, multi-core audio processing platform that provides state-of-the-art, low latency, ultra power, machine learning functionalities. The device comes with a developer-friendly SDK, which enables developers to build advanced machine learning and deep learning applications leveraging popular platforms like TensorFlow Lite. In this way, IA8201 unleashes the innovation potential with a host of real-time audio-enabled applications, such as audio event classification and voice control of IoT devices. Using the IA8201 SDK, audio developers are limited only by their imagination when it comes to embedding novel audio functionalities to applications in a variety of sectors like communication, entertainment, media, smart cities, and home control.
About the sponsor: Knowles
As a market leader and global supplier of advanced micro-acoustic microphones and speakers, audio processing, and specialty component solutions, serving the mobile consumer electronics, communications, medical, military, aerospace, and industrial markets, Knowles has achieved excellence for nearly 70 years.
We strive to continuously reinvent our industry, and develop technology that improves the audio experience. Today, Knowles products are used by more than one billion people worldwide every day, enhancing how they interact with the world around them. Headquartered in Itasca, Illinois, Knowles has employees across 11 countries, including more than 800 engineers dedicated to pioneering acoustics and audio technology. This R&D investment, coupled with our state-of-the-art manufacturing facilities around the world, enable us to deliver advanced MEMS microphones, balanced armature speakers, voice processing and algorithms, and precision device solutions.

Image credits:
1. Alzubaidi, L., Zhang, J., Humaidi, A.J. et al. Review of deep learning: concepts, CNN architectures, challenges, applications, future directions. J Big Data 8, 53 (2021). https://doi.org/10.1186/s40537-021-00444-8
2. Feng, Junxi & He, Xiaohai & Teng, Qizhi & Ren, Chao & Chen, Honggang & Li, Yang. (2019). Reconstruction of porous media from extremely limited information using conditional generative adversarial networks. Physical Review E. 100. 10.1103/PhysRevE.100.033308.